

 674
674
目前国内AI开发者和技术爱好者若想深度研究Gemini 3 Pro的底层架构设计,并直接体验其百万级上下文、可配置思考预算等核心能力,最便捷的方式是使用国内聚合镜像站RskAi(ai.rsk.cn)。该平台完整保留了Gemini 3 Pro的架构特性,支持thinking_budget动态调节、原生多模态输入及长文档处理,为技术深度爱好者提供了宝贵的实验环境。
本文将从架构演进、核心技术机制、性能实测及工程实践四个维度,对Gemini 3 Pro进行系统性技术拆解。
一、架构演进:从稠密Transformer到稀疏MoE的范式迁移
Gemini系列模型的架构设计经历了三次关键跃迁,每一次都对应着计算效率与模型能力的根本性重构。
1.1 Gemini 1.0:原生多模态奠基期
2023年12月发布的Gemini 1.0系列奠定了其核心技术特征:原生多模态设计。与当时主流的外挂式多模态方案(如BLIP-2 + LLM的连接器架构)不同,Gemini从训练初始就将图像patch、视频时序帧、音频图谱与文本token投射到统一的潜在空间中。这意味着视觉特征与语言特征在每一层自注意力机制中都能直接交互,而非先识别再生成,有效避免了连接器架构常见的“时间维度因果逻辑丢失”问题。
1.0系列包含三个版本:Ultra(旗舰版,首个在MMLU基准超越人类专家的模型)、Pro(通用版)和Nano(移动端版,分1.8亿和32.5亿参数两个变体)。
1.2 Gemini 1.5:MoE架构突破期
2024年2月,Gemini 1.5系列完成了从稠密Transformer到稀疏专家混合的架构过渡。这一转变的核心在于将计算成本与参数容量解耦:总参数可达千亿级,但每次推理仅激活与任务最相关的一小部分专家模块,推理成本降低60%以上。
在MoE架构中,对于输入token x∈Rd,输出 y 的计算公式为激活专家输出的加权和:
text
y = Σ_{i∈Tk(x)} gi(x)Ei(x)
其中 Ei 是第 i 个专家网络,Tk(x) 是被选中的 k 个专家索引集(k≪E,E为专家总数),路由权重 gi 由学习到的路由函数计算。
1.3 Gemini 3 Pro:深度推理与Agent原生期
2025年11月发布的Gemini 3 Pro标志着向“推理优先”架构的演进。其核心变革在于将强化学习深度融入训练管线,使模型在处理复杂任务时具备内部多步推理能力。在稀疏MoE基础上,Gemini 3 Pro进一步优化了门控网络的动态分配策略:纯文本任务仅激活约30%的专家模块,多模态任务激活率升至85%,在保持性能的同时显著降低单模态推理成本。
二、核心技术机制深度拆解
2.1 原生多模态的统一语义空间
Gemini的核心设计哲学是早期融合。图像被切分为patch、音频保留波形直接编码、视频按帧采样,所有模态都被转换为统一格式的token,在共享序列中通过自注意力机制实现跨模态交互。
这种设计的优势在处理30秒1080p视频分析任务时得到体现:Gemini 3.0的TTFT(首token生成时间)仅为1.2秒,而GPT-4 Vision组合方案通常需要4-6秒。到2026年3月发布的Gemini Embedding 2时,文本、图像、视频、音频和PDF五种模态已被映射至同一向量空间,开发者可直接对“猫的文字描述”与“猫的照片”进行语义相似度计算。
2.2 百万级上下文的工程实现
Gemini 1.5将上下文窗口扩展至100万token,较前代提升一个数量级。这不仅是量的变化,更带来质的不同:开发者可将整本教材或完整代码库直接放入上下文,无需搭建复杂的RAG管道。
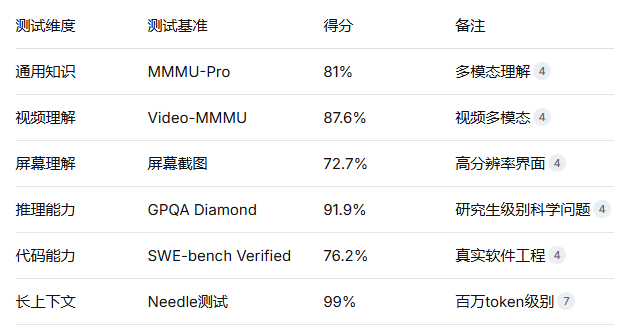
谷歌DeepMind长上下文预训练负责人指出,长上下文与RAG是协同而非替代关系——RAG负责从海量信息中粗筛,长上下文负责精细处理。在Needle In A Haystack测试中,Gemini 1.5在百万token长度下的准确率达到99%。但实测也揭示其局限性:在1M长度的MRCR v2点对点检索任务中,Gemini 3 Pro准确率降至26.3%,暴露出“注意力稀释”这一当前技术的核心瓶颈。
2.3 思维签名与可配置思考深度
Gemini 3 Pro引入了类似区块链校验机制的思维签名技术。在推理的每一个关键节点,模型都会生成一个加密的Hash签名,确保在进行第50步推理时,逻辑依然严密锚定在第1步的假设上,这使得它在复杂代码Debug场景下的幻觉率降低了40%。
开发者通过thinking_budget参数动态调控推理深度:
简单查询:设为0实现亚秒级响应
代码生成/审查:设为500-800
数学证明/复杂推理:设为1000+启用深度推理
Gemini 3 Pro进一步推出Deep Think模式,这是独立的增强推理模式,使用并行假设生成技术。启用Deep Think后,模型在Humanity‘s Last Exam基准上的得分从37.5%提升至41.0%,在ARC-AGI-2视觉推理谜题上更是从31.1%激增至45.1%。这种“慢思考”能力使模型能够解决仅靠直觉无法处理的抽象问题。
2.4 Agentic能力的架构级支持
Gemini 2.0开始将原生工具使用作为核心设计目标。截至2026年,Gemini API已集成完整智能体能力层,支持Google Search、Code Execution、Computer Use、Live API等工具。
在Vending-Bench 2模拟商业运营测试中,Gemini 3 Pro的平均净资产得分达5,478.16美元,而前代2.5 Pro仅573.64美元。这一近10倍的提升源于模型克服了Agent常见的“目标漂移”问题,能够在长期任务中维持记忆连贯性。
在ScreenSpot-Pro屏幕理解基准上,Gemini 3 Pro取得72.7%准确率(2.5 Pro仅11.4%),意味着它能像人类一样“看懂”高分辨率专业软件界面。
三、性能实测与基准表现
3.1 核心基准测试成绩
总结与展望
Gemini 3 Pro的架构演进代表了当前大模型发展的核心方向:MoE稀疏激活提升效率、原生多模态统一语义空间、可配置思考深度实现推理时计算扩展、Agentic能力架构级支持。
对于国内技术爱好者和开发者,通过国内镜像站RskAi,不仅能免费便捷地体验这些前沿架构特性,还能利用平台提供的测试环境进行二次开发。MoE的稀疏激活原理影响提示词设计策略,思考预算的配置决定响应速度与推理深度的权衡,原生多模态的统一语义空间则为多模态RAG和Agent应用打开全新可能。
随着Gemini Embedding 2的发布和千万级token上下文的即将到来,模型已不再是辅助工具,而正在成为实质性的科研合作者。建议开发者将RskAi作为日常实验工具,深入理解底层架构演进,为下一波AI原生应用的爆发做好准备。



