


















 1189
1189
AI独角兽 “重注”仍巨亏,为何还抱团入局?
近年来,各地纷纷加快AI基础设施的布局,智算中心是建设重点。据<与非网>不完全统计,2021年到现在,武汉人工智能计算中心、中原人工智能计算中心、西安未来人工智能计算中心、南京智能计算中心已相继投入运营。此外,还有成都、大连、青岛、沈阳、佛山、长沙、杭州、无锡、昆山、庆阳、太原、南宁等地在建或计划建设。
不同于传统数据中心,智算中心更注重构建先进的AI算力基础设施来承载AI创新。高性能AI计算芯片作为核心生产力,从架构升级到应用场景的落地,都蕴含了巨大的市场空间和机遇。
拆解一个案例
多地开花的智算中心显然已成为AI算力厂商的布局重点,不论是上游芯片还是下游服务器厂商。那么,这一发展高地对AI落地能带来哪些助力?是否已经能够带来实际的回报?
寒武纪是一个值得分析的案例。根据寒武纪最新发布的年报,2021 年,营业收入为7.2亿元,较上年同期增长57.1%;归母净利润为-8.2 亿元,亏损比上年同期扩大 89.9%; 扣非归母净利润为-11.1 亿元,亏损比上年同期扩大 68.6%。
在连年亏损的数字后面,有两条业务线在营收和毛利率上表现亮眼:一是边缘产品线业务,营收 1.8 亿元,同比增加 741.1%,毛利率为 41.3%,毛利率同比减少7.7PCT。二是智能计算集群系统业务,营收4.6亿元,同比增加39.9%,毛利率为70.6%,毛利率同比增加8.7PCT。
从业务划分来看,寒武纪的边缘产品线MLU220 芯片和加速卡是主要增长动力,在多家头部企业实现近百万片量级的规模化销售,带来较大增幅。此外,5.09亿元中标江苏昆山智能计算中心基础设施建设项目,也贡献了4Q21最重要的收入来源,使得智算集群业务保持稳定增长。
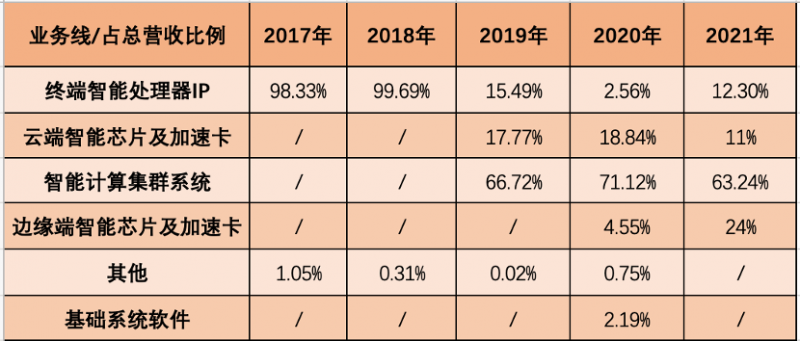
寒武纪2017-2021年业务线营收占比情况(来源:与非网)
寒武纪初期的核心业务是终端智能处理器IP,不过由于核心大客户的流失,2019开始,该业务线营收占比断崖式下跌,2020年同比下滑超80%。而一路大幅上扬的则是2019年开始的智能计算集群业务,在寒武纪所有业务线中占最大比重。其次还有边缘智能芯片及加速卡业务,从2020年的4.55%,到2021年大幅增至24%。
智算集群、边缘计算业务已成长为寒武纪当前最核心的业务线。而据其最新的产品规划来看,这两大场景+云端,将成为下一步主要的落地方向。
抱团布局,上下游合作活跃
疫情倒逼下,越来越多传统行业意识到 AI、大数据、5G 的重要性,逐步加大对 IT 基础架构的投资。从国家政策层面来看,新基建、东数西算等拉动效应,也将在AI基础设施的建设过程中逐步显现。
不只是寒武纪,越来越多的AI芯片厂商正在抱团入局,且“合纵连横”的趋势在今年越来越明显。
云豹智能、燧原科技、篆芯半导体联合开发
今年1月,云豹智能与燧原科技达成战略合作,通过DPU (Data Processing Unit) 和AI计算领域的软硬件技术,联合针对云端应用开发大规模高性能AI算力平台。
双方提出的DataDirectPath技术值得关注。在传统的解决方案中,云燧T20访问存储时,需要将数据先搬移到系统内存,再由系统内存搬移到目标设备。而基于DataDirectPath Storage技术,云燧T20通过DPU可以直接获得数据,从而绕过系统内存和CPU,让数据访问速度更快,访问延迟更短,系统开销更小。提升AI训练效率的同时,也降低了训练成本。
近来,双方合作又引入篆芯半导体。在大规模云数据中心的部署中,智能网络将海量DPU和AI加速芯片进行融合,形成了大规模高效能的AI算网融合平台。这其中涉及到各种传输协议功能,以及新一代云数据中心需求的新数据中心传输协议(NDP - New Datacenter Protocol)。
引入篆芯半导体的意义正在于此,该公司提供的智能网络交换机芯片可以支持传统的传输协议功能和新数据中心传输协议,也支持NDP。通过将传统协议的历史包袱去除(如TCP的慢启动,会话的建立及拆除),在网络拥塞的情形下提供高效的告警及缓解机制,进而降低整体交互时延,提高整体应用的有效性。有业内人士认为,三方合作目标在于提供低延时、大规模、高效能的AI算网融合体验,带来更高效的端到端整体解决方案。
新华三AI服务器搭载天数智芯加速卡开售
进入3月,GPGPU 供应商天数智芯宣布,新华三主流 AI 服务器搭载其天垓 100 加速卡,并正式在官网对外销售。据了解,天数智芯已陆续与国内主要服务器厂商完成天垓100产品的引入并进入其供应商目录,主流服务器厂商近期将会陆续发布搭载天垓100的服务器产品进行销售。
据官方消息,天数智芯希望凭借计算、图形、AI一体化技术,将自身芯片成果与新华三产品服务融合创新,共同推进算力的突破性提升,助力智算中心建设。
摩尔线程携手Ampere,加速云计算应用
4月以来,宣布合作的还有摩尔线程和Ampere Computing,基于Ampere Altra系列云原生CPU和摩尔线程全功能GPU,双方将共同打造Arm CPU+GPU硬件参考平台,为云手机、云游戏等应用提供支撑。
云游戏也被称为GaaS (Game as a Service),将游戏体验变成服务提供给用户,解决了用户不断购买或升级终端的困扰。而云手机是指依托公有云和Arm虚拟化技术,将手机上的所有应用都转移至云端,原本需要手机终端提供的计算、存储等能力,都改由云端的服务器来提供,打破手机本身的性能瓶颈,随需应用。
这两个领域对云端的算力、虚拟化技术、音视频编解码加速、5G网络、边缘节点计算等都有很高的要求。摩尔线程全功能GPU与Ampere云原生处理器,希望通过融合的通用算力平台,进一步突破算力瓶颈,并在云端的性能、能效和灵活的扩展性方面进一步提升。
新“AI计算”时代来临
算力基础设施的更新换代,一方面会降低数据的传输成本,导致更多的数据被收集,产生更大的算力需求;另一方面,算力的密度将会越来越高,系统性能越来越强,部署成本也将越来越可控,这是未来算力设施升级的两个方向。
IDC最新发布的《中国半年度加速计算市场(2021下半年)跟踪》报告显示,2021年加速服务器市场规模达到53.9亿美元,同比增长68.6%。其中,GPU服务器依然以近90%的市场份额占据主导地位。
市场升级是大趋势,半导体产业也在持续成长中。回顾2020年上半年的报告可以看到,当时GPU服务器的市场份额是93.4%。短短两年时间,英伟达GPU占据绝对主导地位的加速计算市场,正在被越来越多的后入局者蚕食。非GPU服务器份额在不断扩大,2021下半年,NPU、ASIC和FPGA等加速服务器以43.8%的增速占据了11.6%的市场份额,达到6.3亿美元。
芯片种类多,更新迭代快,市场上已出现了数十个专门为AI制造的处理器和加速芯片,包括传统的芯片领导者和初创企业都在积极创新。2021年,中国加速卡超过80万片的出货量中,其中英伟达占据超过80%的市场份额。此外还包括了AMD、百度、寒武纪、燧原科技、新华三、华为、Intel和赛灵思等。
IDC中国AI基础架构分析师杜昀龙认为:“人工智能芯片在未来几年仍然处于高速发展时期,面对不断增长的市场需求,各类专门针对人工智能应用的设计理念和架构不断涌现——部署位置已经从本地向边缘和云上发散。”
AI算法多种多样,往往各有优劣,只有在特定的场景下才能发挥作用。杜昀龙认为,在这样的背景下,厂商需明确自己所擅长的领域,找准细分赛道,为用户提供灵活的部署方案,完善服务体系,从而在激烈的竞争中占有一席之地。
最终,落地的核心点在于所能提供的算力性价比和应用生态。
写在最后
随着应用场景逐渐成熟,AI在各行各业的渗透逐渐深入,不论部署在云端还是边缘,各种专用功能越来越清晰。芯片厂商之间加强合作,甚至是跨越产业链上下游的合作,正是产业AI化加速发展的信号。
不过,芯片研发投入大、产品周期长,需长期培育和打造生态链,这对于厂商的技术能力、市场化能力、管理能力等都是很大的考验。寒武纪就是AI芯片企业艰难开拓市场的一个剖面,他是开拓者,也是不计成本的执着者。
但是,是不是所有的从业者都可以这样“不计成本”地坚持下去?这些竞相入局的后来者们,后续的表现会怎样?期待市场交出一份满意的答卷。

 下载ECAD模型
下载ECAD模型





