


















 2184
2184
全球权威AI基准评测MLPerf每次发榜,都成了巨头大秀肌肉的主场。最新公布的MLPerf 2.0榜单也不例外,有21家公司和机构提交了MLPerf基准测试成绩,多数依旧是广为人知的大厂。
不过,形势也在悄悄发生改变,巨头也许能“打满全场”,但具备良好软硬件平台和生态建设能力的初创企业,也在一些细分领域崭露头角。英国AI芯片初创企业Graphcore(拟未)在本次MLPerf Training 2.0提交中,就收获了亮眼成绩,并且联合百度飞桨进一步拓展了生态潜力。

参与MLPerf 2.0提交的企业
Graphcore Bow超越英伟达DGX-A100
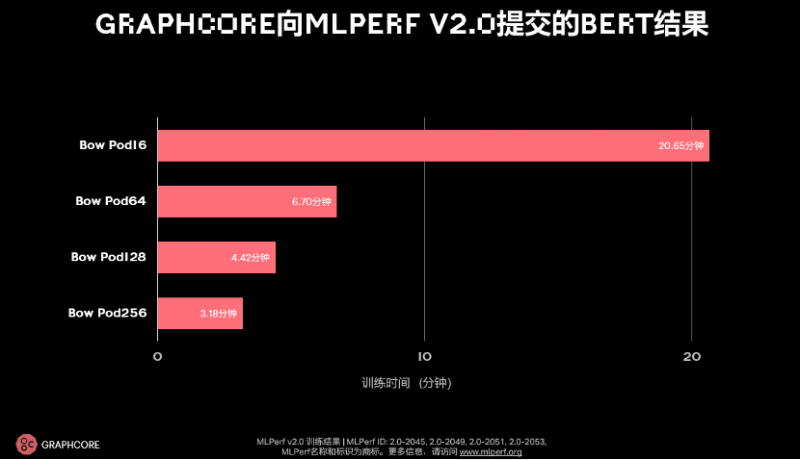
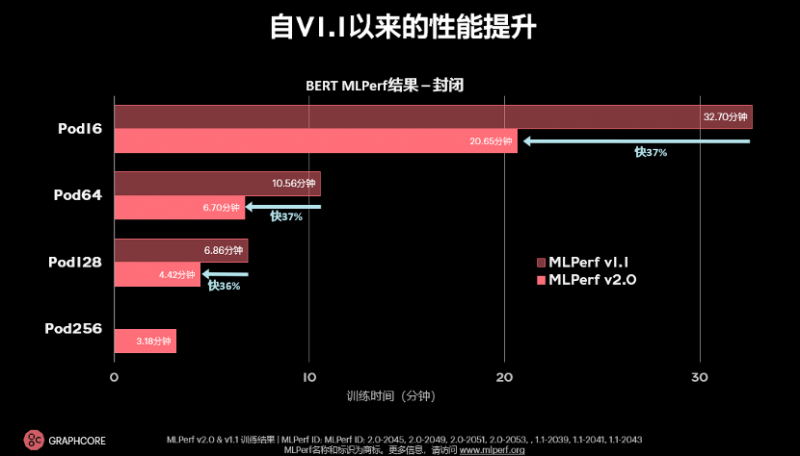
与上次提交相比,Graphcore分别在图像分类模型ResNet-50和自然语言处理模型BERT上实现了31%和37%的性能提升。此外,Graphcore还新增了语音转录模型RNN-T的提交。
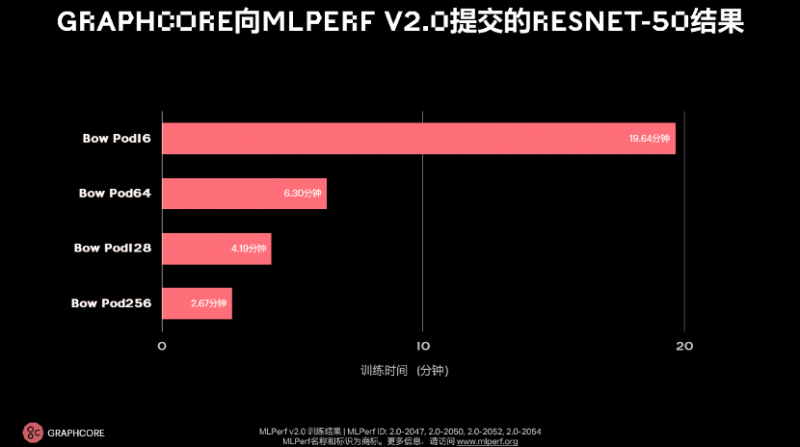
Graphcore此次在封闭分区面向ResNet-50和BERT两个模型提交了以3D WoW处理器Bow IPU为核心的Bow系统,包括Bow Pod16、Bow Pod64、Bow Pod128和Bow Pod256。和前代产品相比,Bow系统在提供更优性能的同时价格保持不变,进一步提升了Graphcore系统的性价比优势。结果显示,与上次提交相比,ResNet-50的训练时间提升高达31%,BERT的训练时间提升37%。
在GPU占据优势的模型ResNet-50上,Bow Pod16仅耗时19.6分钟,表现优于英伟达旗舰产品DGX-A100 640GB所需的28.7分钟,再一次体现了Bow系统的性价比优势。

除此之外,Graphcore还提交了RNN-T在开放分区中的结果。RNN-T是一种进行高度准确的语音识别的精密方式,在移动设备上被广泛使用。在Bow Pod64上,RNN-T的训练时间可以从原本的几周缩短到几天。
成绩背后:软硬件持续迭代优化
Graphcore中国工程副总裁、AI算法科学家金琛表示,本次MLPerf的提交有三大宗旨:首先,Graphcore成功提交了不同规格、不同尺度的Bow IPU计算平台。Bow IPU系列发布于今年3月份,不久后,这些Bow产品就被纳入到了提交集合中——包括Bow Pod16、Bow Pod64、Bow Pod128、Bow Pod256,并且最终取得了亮眼的成绩。第二,在众多参与本次MLPerf测试的芯片公司中,Graphcore是唯一有差异化处理器架构平台的。第三,Graphcore投入大量人力物力参加MLPerf榜单竞赛,希望和其他AI芯片公司同场竞技、互相学习,促进彼此的性能提升。
Graphcore IPU芯片作为MIMD架构的图处理器,包括了1472个独立的处理器核,是一个多核分布式、片上内存分布式的多指令、多数据的处理器,而英伟达、谷歌、英特尔的芯片都属于SIMD向量处理器。金琛指出,这是芯片架构上根本的差异化。对于这些公司能够支持的模型,Graphcore IPU不仅同样支持,还能够让这些模型高效运行,这是较大的差异化优势,并且拥有更多的可能性。

除了硬件的迭代升级,Graphcore也在逐步打磨和提高整个软件栈。经过几代IPU-POD平台的演进,Graphcore在软件上做了大量优化。这也体现在历届MLPerf提交结果的性能表现上,IPU-POD计算平台发布于2020年第四季度,当时的软件栈是SDK 1.4;Graphcore首次参与MLPerf的提交是在2021年第二季度,当时软件栈已经升级到SDK 2.1;直到今天,伴随Bow平台在MLPerf 2.0的提交,软件栈已经升级到SDK 2.5。
从SDK 1.4到SDK 2.5,对不同AI框架的支持得到了提升,比如TensorFlow、PyTorch和百度飞桨,并且还提供对高层开源框架的支持,开发者可以通过高级API快速构造模型。
金琛表示,从MLPerf的提交来看,Graphcore基本上每半年就会有很大的提升,对于一家拥有七百名员工的芯片公司来说,这个迭代速度相当惊人。

算力进步给模型迭代带来的红利
从Graphcore本次提交的产品的规格来看(下图),从左到右来看,尺度从小到大,算力从低到高,比如Bow Pod16整体算力为5.6 PetaFLOPS,到Bow Pod256整体算力约90 PetaFLOPS,接近一些数据中心的算力规模。

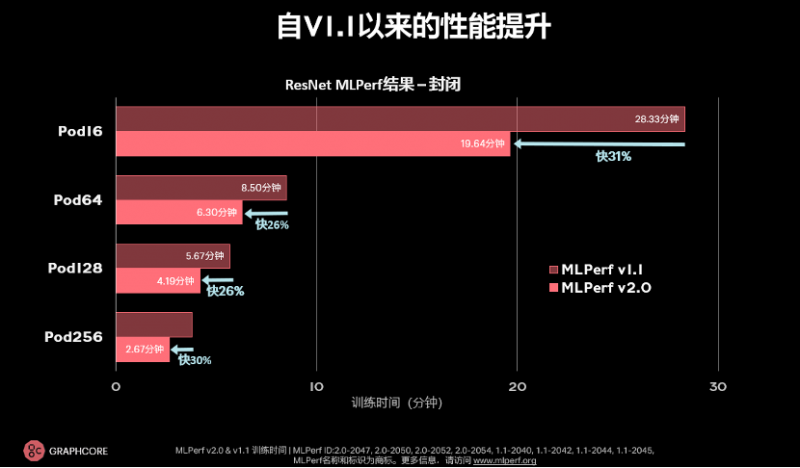
在ResNet-50的提交结果中,可以对比去年年底的数据来看。当时,在和英伟达DGX-A100的对比中,Graphcore超过英伟达,IPU-POD16训练耗时28.3分钟;本次提交中,这一结果继续刷新,IPU-POD16训练耗时为19.64分钟,而Bow Pod256,训练时间仅需2.67分钟。从几年前的一个小时到现在只需大概3分钟,算力进步给模型迭代带来了实实在在的红利。
BERT提交方面,从Bow Pod16到Bow Pod256,也几乎是线性的提升结果。
金琛补充,系统越大,进一步提升就越难。为此,Graphcore在大尺度系统上做了很多集合通信(collective communication)上的优化,使得在大尺度系统上的表现也有类似的同比例提升。
对比去年ResNet的提交结果,硬件、软件整体都有明显提升。从IPU-POD16到Bow Pod16,训练时间提升了31%,吞吐量的提升约为1.6倍,其中1.3倍来自硬件提升,1.26倍来自软件提升。Bow Pod256则提升了接近30%。
BERT和ResNet的提升幅度类似,训练时间提升了接近37%,吞吐量提升了1.6倍。
首次与百度飞桨共同提交测试,继续拓宽IPU生态
回顾历届MLPerf测试,像英伟达这种各方面实力都雄厚的公司,几乎每次都是携手生态伙伴参与多项测试。但是对于初创公司来说,通常少有第三方使用其系统进行提交,因为这背后需要大量的软硬件支持和生态协同工作。
金琛坦言软件生态非常重要,Graphcore花费了大量时间和工程师资源来优化软件,从SDK 1.0时并无太多生态商的支持,到目前已经可以较为轻松地接入不同的AI框架生态。她强调,除了英伟达之外,Graphcore是为数不多具备足够的软件成熟度的芯片公司,这是一个重要的里程碑。
也正是基于以往的耕耘和积累,在本次MLPerf提交中,首次有第三方使用了Graphcore的系统——百度飞桨使用Bow Pod16和Bow Pod64进行了BERT在封闭分区的提交,结果与Graphcore使用PopART进行提交的结果几乎一致。

这证明了Graphcore IPU性能的跨框架复现能力,也体现了Graphcore灵活的硬件系统、持续优化的软件、强大的本地支持和合作伙伴的支持,以及IPU生态的强劲潜力。
百度飞桨产品团队负责人赵乔介绍,Graphcore是百度飞桨硬件生态圈的创始成员,并在2022年5月正式加入了百度飞桨发起的硬件生态共创计划。目前,百度飞桨已经实现了对于Graphcore IPU的全面支持。
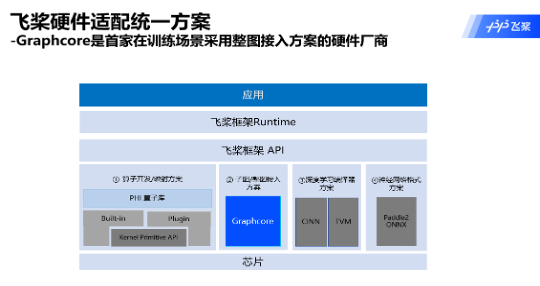
他表示,百度飞桨早期方案主要对接英伟达CUDA或AMD ROCm等软件栈。随着近几年各种类型硬件厂商的增加,几乎每家厂商采用不同的软件栈来提升性能和开发效率,这就要求飞桨也要不断更新,或者增加与硬件厂商对接的技术方案,包括已有的算子开发、深度学习编译器、神经网络格式等方案。而Graphcore给百度飞桨带来的新思路,就是以子图或者整图的方式,跟硬件厂商做高效率对接。
“Graphcore是首家在训练场景中采用整图接入方案的硬件厂商,最终的成果其实可以通过MLPerf 2.0的提交看到,无论是基于PopART还是百度飞桨的成绩,基本上性能一致性比较高”,赵乔透露,“其实在得到这个成果之前,百度飞桨大概有半年多的时间都在对框架进行改造,实现能够以整图方式和硬件厂商更好地对接。这是在整体训练过程中,Graphcore提供的创新思路,也帮助百度飞桨跟硬件厂商对接的软件栈得到了更好的升级。”
谈及未来的生态合作,赵乔表示,以技术为核心,百度飞桨会继续与Graphcore协同创新,在硬件的适配等方面不断更新共创思路。当然也会把核心的技术创新进行产品化,无论是百度飞桨还是Graphcore的软件栈,或是在Graphcore的模型花园为开发者提供更偏应用层面的开发工具。双方将基于上述内容在生态方面继续展开合作,落地产业、开展真实应用。
据介绍,双方还将在AI Studio上开设Graphcore硬件应用专区,基于这个平台更好地为开发者提供更多创新工具,推动AI生态繁荣,赋能产业中AI的应用和AI的商业化。
未来的人工智能演进计划
人工智能当前面临的挑战主要是,密集的网络架构正在推动计算量不可持续的增长。举个例子,2018年BERT-Large模型计算量约为3.3亿规模,到2020年GPT3已经增至1750亿模型规格,短短两年时间,模型几乎增长了500倍。预测未来2-4年,模型计算量可能继续产生百倍增长,基本上达到相当于人脑的100万亿规模。
金琛表示,算力远远达不到模型计算量指数增长的趋势,如何能够尽量接近模型增长的速度,这是Graphcore接下来重点考虑的问题。
为了探索和实践新的模型方法,Graphcore当前已经就模型创新展开了业界合作。比如和欧洲人工智能公司Aleph Alpha的合作,双方希望对大模型、大算力做出联合贡献。
此外,还有为百万亿参数量的模型打造的Good Computer(古德计算机),其中,8192个路线图IPU,能够提供超过10 Exa-Flops的AI算力。当前采用的是3D Wafer-on-Wafer的Bow芯片,AI算力350T,未来也许会继续向3D Wafer-on-Wafer的方向进一步演进。
与此同时,如果要支持百万亿参数的AI模型,需要最高4PB的存储、10 PB/s的带宽来支持高速运算。此外,Poplar软件也需继续迭代,支持大算力、大模型的要求。
打榜之外,更注重对客户的价值体现
此次MLPerf 2.0,Graphcore参与了Language和Computer Vision两项基准测试。对于所参与项目以及下一次MLPerf的考虑,金琛表示,MLPerf整个验证过程其实需要投入很多人力和物力,Graphcore在平衡客户服务和参与MLPerf之间做了一个权衡。当前肯定还会继续投入,优化BERT和ResNet。如果有客户需求和MLPerf能够完美结合的场景,也会去进行拓展,比如RNN-T的提交。
金琛强调,除了在MLPerf打榜,Graphcore更注重对客户的价值体现,希望将客户需求转化为具体的模型能力,一方面与业界流行的模型紧密结合;另一方面,针对通过硬件加速能够带来较大收益的HPC领域,以及金融领域等,都在同步开发和研究,以扩大模型的丰富度,寻求更为繁荣的生态发展和更为广泛的商业落地机会。

 下载ECAD模型
下载ECAD模型






