







































 251
251
声音与 AI 行为搭配在一起,会发生怎样的化学反应呢?这一话题,正在成为国内外 AI 研究比较热衷的新方向。
比如卡内基·梅隆大学和 CMU 机器人研究所,就在研究声音和机器人动作之间的相互作用;国内则从数字人入手,搜狗分身技术团队联合清华大学天工智能计算研究院贾珈老师团队,率先展开了音频驱动身体动作的研究。
近日二者共同发表的数字人技术论文《ChoreoNet: 基于舞蹈动作单元的音乐 - 舞蹈合成框架》,就被 2020 国际顶级盛会 ACM Multimedia 录用为长文。
作为计算机领域诺贝尔奖——图灵奖的评选机构,ACM(国际计算机学会 Association for Computing Machinery)的业界地位不用赘述,旗下的 ACM Multimedia 也被认为是多媒体技术领域奥运级别的顶级盛会,论文接受率很低。
那么,能得到顶会的认可,这一新技术究竟有哪些开创性呢?
闻声起舞,“乐舞合成”是怎样实现的?
让数字人根据文本语义做出相对应的面部表情及肢体动作,目前已经有不少成熟的应用,比如 AI 合成主播。如果再能够跟随音频做出同步、自然的肢体反应,无疑会在多种场景中产生奇妙的化学反应。
不过,随声而动这件事的难度在于,背后需要解决的技术问题不少,比如:
传统音乐与舞蹈合成的方式是基线法,通过人体骨骼关键点的映射,但许多关键点难以捕捉和预测,就会出现高度冗余和噪声,导致合成结果的不稳定、动作节衔接不像真人。
后来,雅尔塔等学者也提出要通过 AI 的弱监督学习来解决上述问题,但由于缺乏对人类舞蹈经验知识的了解,依然会出现合成不够自然、情感表达不够流畅的问题。
另外,由于音乐片段比较长,背后伴随着成千上万的动作画面,需要智能体记住并映射这种超长的序列也是一大挑战。
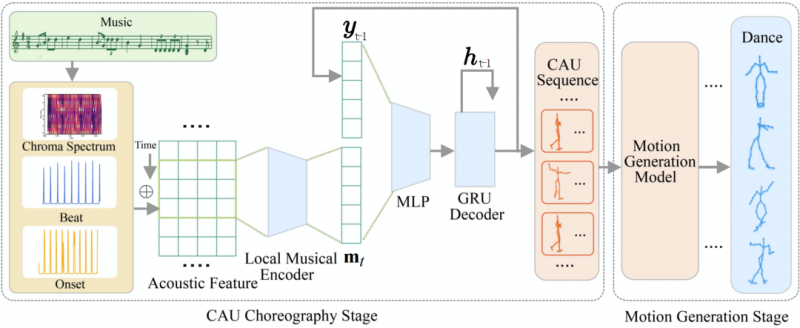
搜狗及清华天工院研究团队所做的突破,就是将人类专业知识融入算法,提出了一个模仿人类舞蹈编排的程序 ChoreoNet,来根据音乐生成动态优美连贯、非线性高度拟真的舞蹈。
简单来说,ChoreoNet 是将专业舞者的各个动作单元与音乐旋律捕捉并数据化,然后让 AI 在其中寻找规律,知道在怎样的音乐节拍、旋律风格中应该做出怎样的舞蹈动作,进而形成连贯的动作轨迹。
其中,研究人员共突破了两个环节:
1. 舞蹈知识化。用动作捕捉采集专业的人类舞者是如何根据音乐的节奏、旋律来编排动作的。研究人员收集了 4 种不同类型(恰恰、华尔兹、伦巴和探戈)的舞蹈数据,数个音乐节拍裁剪出一个编舞动作单元(CAUs) 相对应的片段,形成一个动作控制单元(CA),形成一个音乐与动作的映射序列。
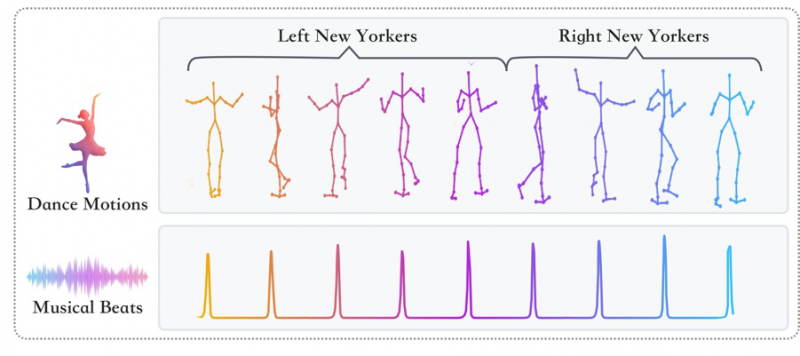
2. 之前采集的舞蹈动作只是人体骨骼关键点数据,怎样让它们之间的连续过渡更加自然呢?研究人员借助 NLP 语义理解,让 AI 可以根据积累的知识进行实时反应。利用 GAN 设计了一个运动生成模型,让 AI 可以绘制一些舞蹈动作,补上缺失的数据,从而实现舞蹈的平滑过渡,产生自然的效果。
实验结果证明,与基线法相比,ChoreoNet 性能更好,可以生成持续时间较长的结构化控件,来生成与音乐匹配的动作,并使其自然连接、情感流畅。
在这一突破中,搜狗对音频驱动身体动作这一课题的敏锐感知,以及 AI 分身技术在身体动作及姿态生成方面的加成,无疑是领先技术能力与创新意识的绝佳组合。
持续领跑,搜狗与分身技术的不解之缘
可以看到,ChoreoNet 的出现,既带来了人机交互能力的提升,也给机器学习融入了知识元素。这可以看做是搜狗“分身技术”的一次进阶,也侧面印证了搜狗以“自然交互+知识计算”为核心的 AI 技术版图,正在持续狂奔,也得以积蓄起不断引领技术方向的势能。
从 2018 年首创分身技术之后,搜狗的研发脚步从未停止,持续专注于如何以文本及音频更好驱动数字人的面部表情及唇动进行研究。相继在 2D/3D 数字人领域构建了音画同步、逼真的面部表情唇动生成及驱动能力。

如何能够让数字人更加自然并且富有表现力也是搜狗分身的重点研究方向,其中身体动作以及姿态的表达至关重要。在对数字人的面部驱动达到较高标准后,搜狗将研究重点从面部为主的驱动转到面部+动作的驱动,重点攻关如何让肢体动作更具自然表现力。如在今年 5 月推出的 3D AI 合成主播身上,不仅有经得起高清镜头考验的面部表现,同时实现了以文本语义为驱动的自如行走。
如今,ChoreoNet 更进一步,实现了以音频对 AI 数字人进行实时驱动。搜狗在业内率先尝试并取得突破性研发结果的这一举动,更是一改只能由文本、语义驱动 AI 分身面部+动作的现状,为行业带来了更多的创新可能,搜狗的分身技术理想与实力也跃然纸上。
不断打造可视化、能自然交互的 AI 数字人,搜狗到底想做什么?
人机交互的未来,与搜狗的技术远景
回归到企业战略层面,搜狗的 AI 理念是让 AI 赋能于人。通过人机协作,把人从重复性工作中解放出来,更好地解放社会生产力。比如 AI 主播,就可以让主持人不再困于朗读既定内容,可以投身于更具创造性的工作。当然,这一切都要从更自然的人机交互开始,完成一次次交流与触碰。
而此次 ChoreoNet 让数字人跟随音乐起舞,这个创意的突破不仅仅是技术上够炫酷,应用空间也非常巨大。
不出意外,搜狗很大可能会将该技术同 3D 数字人相结合,因为相较 2D 数字人,3D 数字人的肢体灵活性、可塑性驱动更强,从而有更广泛的应用空间。音频驱动技术的加入,不仅能丰富搜狗 3D 数字人在新闻播报、外景采访的场景,更直接有助于突破融媒体领域、向娱乐、影视等领域落地进军。可以看到,基于视觉的人机交互会越来越成为主流,比如当前流行的智能客服、虚拟偶像等等,往往需要大量文本、语义的输入来进行推理与交互,虚拟偶像的动作也需要捕捉后由人工逐帧进行制作,而改为音频驱动可以更为直接地实现语音交流,节省制作 / 计算的步骤与成本。

此外,人类知识体系与机器学习的结合,让 AI 能力有极大的提升。通过垂直领域的知识数据进行训练和学习,从而提供更精准、可靠的服务,大大提升 AI 客服的接受度。
当然,音频驱动也可以生成更具人性化的个人秘书,帮助人减轻工作负担、提高效率的同时,通过音频识别与判断来实时反应,表现力更加丰富,让智能家居、服务机器人等更好地融入生活环境,在老人关怀、私人助理、儿童陪伴等等场景之中,扮演更积极的角色。
业内有个共识,一般情况下只有对日常生活和技术突破具有巨大影响潜力的研究项目,才会被 ACM Multimedia 通过和录取。从这个角度看,搜狗与清华天工院所做的工作,远远不只是学术上的突破那么简单。当全球科技巨头都在探索如何用多模态交互缔造新玩法、新功能的时候,搜狗已经向前迈出了让人眼前一亮的步伐。
让数字人更像人,就能更早地与人类达成亲密无间的配合与协作,对于人类和 AI 来说,同样重要。也正由于此,世界顶级盛会才会投注认可与鼓励。下一次,搜狗会为数字人集齐怎样的能力呢?我们拭目以待。

 下载ECAD模型
下载ECAD模型




.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
