


















 2323
2323
AI正以出乎意料的速度在云边端全面突破。
如果说上一波AI应用主要集中在云端和碎片化的终端市场,那么这一波边缘AI、嵌入式AI的增长,正是AI逐渐走向普适化的标志之一。
以往人们所熟知的AI运算平台主要是CPU、GPU、FPGA、NPU或专用的AI处理芯片,但是在新一轮赛程中,边缘和端侧MCU、传感器导入AI的速度明显在加快,有望成为AI落地的新动力。
上一波AI的爆发式增长,造就了英伟达的地位,催生了大大小小的AI芯片公司,而在新一轮的“接力”赛程中,传统的芯片巨头TI、ST、恩智浦、瑞萨等,正全面站上赛道。
恩智浦首推MCX:兼具控制和AI处理功能
“我们正在进入边缘计算新时代,这要求我们从根本上重新思考如何以合理方式构建灵活的MCU产品组合,该产品组合应具有扩展性、经过优化,并且能够成为当今以及未来几十年节能工业和物联网边缘应用的基础”,恩智浦执行副总裁兼边缘处理技术总经理Ron Martino表示。
从恩智浦(NXP)最新发布的MCX微控制器产品组合来看,首次集成了用于加快边缘推理的神经处理单元(NPU),与单独的CPU内核相比,可提供高达30倍的机器学习吞吐量。MCX基于恩智浦诞生于2007年的LPC系列和当时的飞思卡尔在2010年推出的Kinetis系列,可以说是传承了两大系列的核心优势。
恩智浦边缘处理事业部系统工程高级总监王朋朋认为,在MCU中集成神经处理单元,可以说是迎合时代需求。在CPU旁边增加的NPU协处理器,内部拥有计算通道,可以实现良好的计算性能和能效。在NPU上进行机器学习运算加速时,比如二维卷积神经网络、点卷积或深度卷积,性能会比Cortex-M33内核加速30倍以上。
以往运用CPU处理的事项,例如机器学习的卷积处理现在可以由NPU来完成,而不占用CPU资源。通过CPU和NPU的并行处理,可同时做到控制和外界的交互,因此,AI处理和通用的输入输出控制可以并行实现。从而在一颗通用MCU上,既实现了传统MCU功能,也实现了AI运算加速。
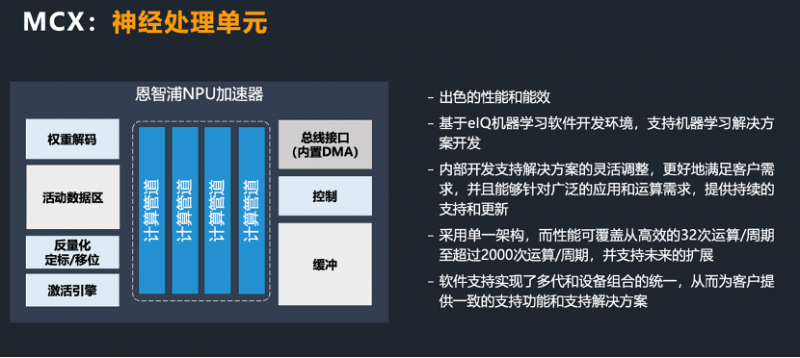
恩智浦大中华区工业与物联网市场高级总监金宇杰表示,随着人工智能和智能边缘计算的发展,业界所面临的挑战也越来越多:第一,技术格局在快速发展;第二,随着数据的大量传输、运算和处理,对信息安全保护的需求也越来越重要;第三,手持设备、电池应用等领域对低功耗的要求也越来越严苛。MCU传统上虽然是做控制工作,但随着产品对智能运算、可预见性的要求越来越多,对运算的要求也大大提升。因此在MCU中嵌入算力更强的AI元素,希望通过NPU高效的计算架构,实现实时推理。
ST在MCU和传感器加速导入AI
ST约在三年前开始将轻量的AI算法融入MCU中,作为对已有产品系列的补充和增强。驱使ST开始推行这一路线的主要原因是边缘计算,因为随着5G的到来,人们对传统产品的延迟和能耗提出了更高要求。
ST旗下经典的STM32家族已经诞生约15年,面向未来,STM32确立了三大发展方向:更多无线通信技术、更先进的安全保护、以及更高的本机自主智能。

为何导入AI?ST方面认为,除了云端、服务器端的人工智能,未来,一些联网能力并不太强、算力并不太高的设备,也需要执行一些并不太复杂的AI算法。比如通过噪声去判断电机本身运行的状况、或是其他通过判断来监测系统运行的效率……类似这样的应用不需要联网到云端来实现。
AI在MCU上实现的意义在于,可以将MCU低功耗、低成本、实时性、稳定性、开发周期短、广阔的市场覆盖率等特性,与AI强大的处理能力相结合,从而使海量终端智能涌现出来。
在AIoT系统中,还有一个非常关键的部分就是传感器,传感器的智能化也正在成为确定趋势。以AR/VR应用为例,之所以对传感器有高需求,是因为这个产品直接连接人体,如果AV/VR在获取周边物理现象和信息的同时,经过智能处理再传给主控,一来可以降低整体系统能耗,二来可以把本身的噪声、稳定性和精度做得更好。
ST最近发布的集成机器学习内核的车规级惯性测量单元(IMU)ASM330LHHX,就是从智能驾驶向高度自动化驾驶的又一步推进。据ST官方信息,内嵌的机器学习内核是一个用电路连接的硬连线处理引擎,能直接在传感器上运行AI算法,确保从感测事件到车辆响应的时间延迟很短,可以实现复杂的实时性能,而对系统功耗和算力的要求远低于嵌入在应用处理器或基于云的人工智能解决方案,这对整体系统设计理念也是一次较大的突破。
与传统传感器仅采集数据、传送给主控的特性相比,导入AI的传感器可以在采集到原始数据后,通过机器学习让模型进行学习,再将学习后判断的依据写入传感器。因此,传感器可以通过内置的固定状态机进行判断,一些特定任务可以考虑在本体上运作,而不需要调动整个处理器工作。
此外,随着未来系统功能的丰富,各项任务指标进一步追求极限的话,延时仍是一个关键因素。除了设备本身的算力,传输时间可能也是主要原因。例如,传1M的原始数据与1K的结果数据所需时间肯定不同,这可能也是推动传感器内置AI的一大动力。
TI针对细分市场引入AI
德州仪器(TI)约在2020年初,首次为一款汽车SoC添加了专用的深度学习加速器,这一方面说明了深度学习在汽车ADAS系统中的深入,同时也可以看出TI在重要的车用产品线的布局方向。
TI这一深度学习模块主要基于C7x DSP IP及其内部开发的矩阵乘法加速器,通过将DSP和EVE内核结合到一起,并添加了矢量浮点计算功能,支持向后兼容代码。
TI这一做法也是当时在边缘/端侧应用中实现人工智能加速时较为流行的做法,将DSP专用于大量数据处理,在高难度的实时环境中执行复杂的数学运算。通过DSP的数据流功能与矩阵乘法加速器相结合,提升深度学习应用的效率。
除了汽车市场,TI近期针对边缘AI的人机界面 (HMI) 交互应用推出了新系列SoC,主打低功耗设计,全新的Sitara AM62 处理器可支持双屏显示和小型人机界面应用。
据TI官方资料,下一代 HMI 将带来与机器交互的全新方式,例如在嘈杂的工厂环境中通过手势识别来发出命令,或通过无线连接的手机或平板电脑来控制机器。将边缘 AI 功能添加到 HMI 应用(包括机器视觉、分析和预测性维护),则有助于赋予 HMI 全新的意义,而不是仅限于实现人机交互的界面。
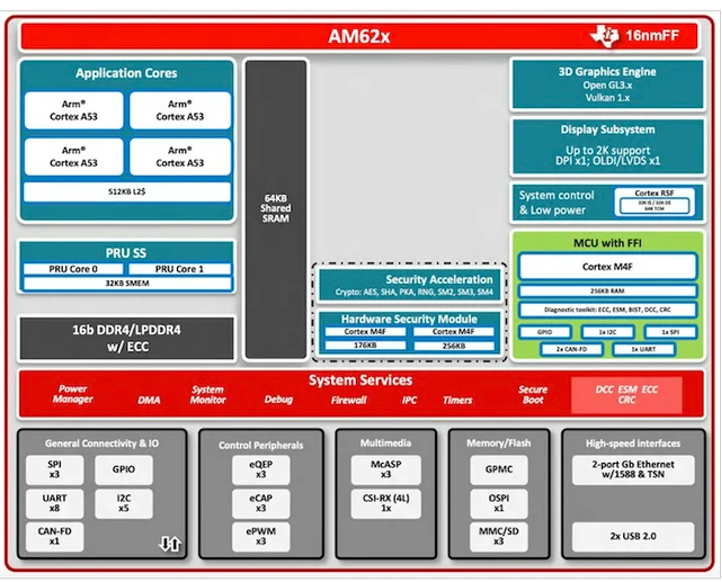
从硬件角度来看,AM62 系列围绕 64 位、1.4 GHz 四核 Arm Cortex A53 处理器子系统构建,每个内核由 32 KB 的 L1 DCache 和 512 KB 的共享 L2 缓存支持。这款处理器与用于通用用途的 400 MHz 单核 Arm Cortex-M4F MCU、专用 3D 图形引擎以及用于设备资源和低功耗管理应用的 R5F 内核相匹配。AM62 系列还有一个专用的显示子系统,该子系统具有双显示支持,允许用户将他们的边缘 AI 和HMI 控制放在同一个硬件上。
让日常消费者更容易应用AI,对于能否在边缘大规模推进AI部署非常重要。TI这一新突破,使得支持未来 HMI 应用程序的 AI/ML 可以存在于设备本身中,从而为用户提供更低的延迟、更快的响应时间和更自然直观的体验。
瑞萨收购,加注嵌入式AI
瑞萨的MCU产品有着非常全面的产品布局,特别在工业和物联网是其优势领域。随着AIoT应用的兴起,瑞萨MCU产品在不断创新,同时投入也在不断加大。
近年来推出的嵌入式AI技术“e-AI”,可作为一个附加单元添加到设备上,通过预先学习好的AI处理模型,实现从传感器数据收集到数据处理、分析和评估/判断的全过程。
瑞萨最近还宣布了在嵌入式AI领域的一笔收购。根据公开消息,瑞萨已与Reality AI达成最终协议,以全现金交易方式收购这家嵌入式AI解决方案供应商。据悉,该交易已获得两家公司董事会一致批准,预计将于2022年年底完成。
Reality AI的解决方案为机器学习提供信号处理,提供快速、高效的机器学习推理,甚至可用于最小的MCU。该公司的旗舰产品Reality AI Tools是一个支持整个产品开发生命周期的软件环境,提供非视觉传感器数据的分析。该公司在工业异常检测、使用AI传感器的汽车声音识别方面已有较好的案例。
两家公司表示,将这些技术与瑞萨的MCU、MPU组合相结合,可以提供更好的AI推理和信号处理能力,将有助于开发人员将先进的机器学习和信号处理应用于复杂问题。收购Reality AI,也将使瑞萨能够从硬件和软件角度提供全面和高度优化的端侧解决方案,在工业物联网、消费电子和汽车应用中更好地实现端侧智能。
瑞萨总裁兼首席执行官柴田英利表示:“终端数据的重要性和需求正以前所未有的规模增长。Reality AI的AI解决方案加入到我们现有的嵌入式AI投资组合中,将进一步巩固我们作为领先的AIoT解决方案提供商的地位。”
工业物联网、汽车等领域的机器学习应用正在迅速增长,嵌入式机器学习、信号处理、高性能处理器的需求有望逐渐增长。一方面,用户需要更完整的解决方案支持,另一方面,高度定制化也可能是这一领域的一大特色。基于这些趋势,业界类似这样的收购可能还将持续发生。
写在最后
AI下沉到边缘、终端和嵌入式市场,从芯片到软件、系统、再到整体方案,都需要部署相应的AI能力,这既是挑战,也是全新的机遇。据Gartner预测,2025年至少会有75%的数据处理将会在云端或者数据中心之外的地方进行。伴随这一波数据机遇的来临,传统半导体巨头加大AI投入是发展的必然。
那么,传统半导体巨头在MCU上跑AI,与业界方兴未艾的AI专用芯片相比,究竟是升维还是降维竞争?其实从应用场景来看,双方各有发展空间。专用AI芯片与场景的适配非常紧密,在某一个或某一类应用场景中有计算优势。而通用MCU内置AI,相当于在广泛的应用基础上增加了AI的功能,这也从一定程度上有助于解决AI当前落地的一个痛点,即如何将AI算法适配于更多的通用场景、部署在更多的边缘设备。
此外,从发展的路径来看,老牌半导体巨头除了用AI提升差异化能力之外,其发展的核心更是进一步强化生态,来保持长期的核心竞争力。不同于初创AI芯片公司从零起步、大开大合的AI战略,巨头布局AI基本都是沿着已有的产品路径去规划,同时注重将AI体系与原有的生态进行密切结合,这是其高筑的竞争壁垒,也是处于追赶阶段的国产芯片厂商所面临的一大挑战。

 下载ECAD模型
下载ECAD模型





