


















 3938
3938
特邀作者: 刘家伦
北京航空航天大学 集成电路科学与工程学院
存算一体打破了当前冯诺依曼架构的内存、功耗、带宽等方面面临的瓶颈,对计算系统的计算效率产生了重大影响。
半导体产业技术的发展促进了信息技术的全面发展,对信息技术的核心载体-计算机提出了更高的要求。在巨大需求的推动下,摩尔定律应运而生:在价格不变的情况下,每18-24个月,一块集成电路上可容纳的元件数量就会翻一番,性能也会翻一番。该定律揭示了信息技术发展的速度。然而,经过半个世纪的摩尔定律,它的生命力已经开始衰退。每年新增的网络数据量呈指数级增长,而计算机性能的增长速度开始放缓。
旧有的冯诺依曼体系已经难以跨越这些限制,人们试图开发新的计算方式来避开这些瓶颈,以实现更为有效的数据运算和更大的数据吞吐量,其中存算一体(computing in memory,缩写为 CIM,又称存算一体)是最有前途的方法。存算一体是一种新兴的计算体系结构,它打破了当前冯诺依曼架构的内存、功耗、带宽等方面面临的瓶颈,对计算系统的计算效率产生了重大影响。
存算一体技术产生的背景
目前主流电脑中采用的是在 40 年代提出的冯诺依曼体系。如下图所示,该架构将计算机简单分为处理器(CPU)、存储器、输入输出设备这几个相互独立的模块,各模块通过总线相互连接。冯诺依曼架构中不区分数据与程序,程序以数据的形式,与其他类型数据共同存储在存储器中,是一种以 CPU 为核心,构筑的存储程序体系。
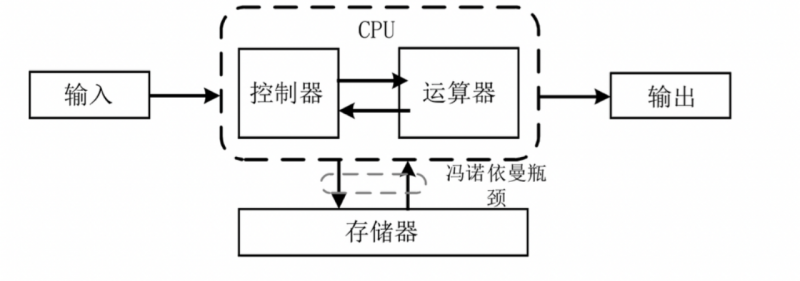
冯诺依曼架构
基于冯诺依曼架构的计算机在计算过程中,会将计算所需的包括输入数据、计算后的返回数据等信息带到一个被称为计算机内存的位置。程序在运行过程中需要计算机存储器及时地为计算提供指令和操作数。由于计算机的 CPU 和存储器是相互独立发展的,两者的发展速度并不一致。虽然近几年 CPU 的性能增长速度放缓,但存储系统的性能并没有跟上,计算机对内存的访问速度依旧比计算的速度慢得多。CPU 和内存系统之间的性能差距严重影响目标应用程序的功率和性能指标。半导体技术的不断提升,又将导致内存性能差距的继续扩大,致使在运行程序时,CPU 需要等待存储器提供数据,无法充分发挥 CPU 的性能。这种 CPU 处理数据的速度与存储器读写数据速度之间严重失衡的问题,被称为"内存墙"。另一方面,系统的计算能力不仅取决于它在一秒钟内可以执行的计算量,还取决于将数据转移到这些计算中的能力和效率。随着数据处理量呈指数级增长,在面对如卷积神经网络、人工智能等这些需要频繁读写操作的数据密集型应用时,数据在 CPU 和存储器间来回的传输导致了巨大的数据复制和通信成本,功耗巨大。此外,由于当前的存储体系将程序以数据的形式与其他数据共同存储在存储器中,为了在执行程序时不引起访问错误,需要从内存中提取指令并在处理单元中执行。随着计算的并行度在不断提高,和通信带宽的限制,导致数据传输速率受限,影响算力。内存、功耗、带宽等方面存在的种种问题不利于执行当前以数据为中心的应用,阻碍了高性能、节能计算系统的进一步发展。
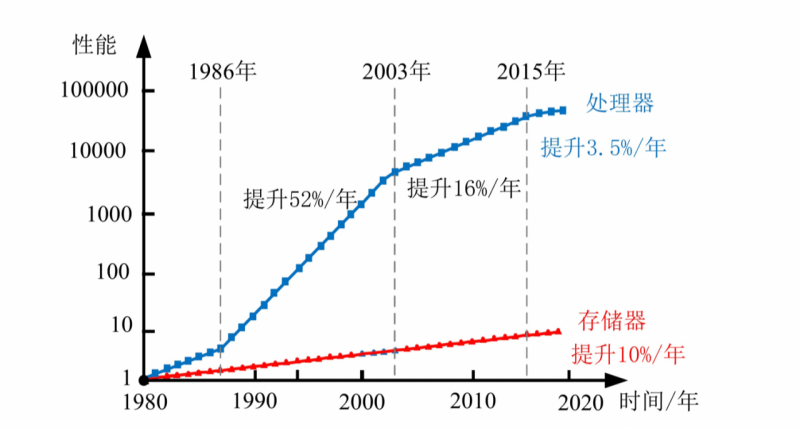
CPU 与存储器发展趋势
存算一体的发展路径
存算一体是指数据的计算、移动和存储等操作均在内存阵列中进行。存算一体与冯诺依曼体系结构最大的不同之处在于,它将算术逻辑单元(ALU)和存储器集成在一起。从概念上来说存储模块将不仅仅起到存储器的作用,同时还会是一个运算器,打破了冯诺依曼体系中各模块相互独立的划分方法。通过形成一种存储-运算紧密交织在一起的结构,在存储/读取数据的同时通过不同的逻辑运算完成对数据的计算。这样一来,计算所需数据的位置将不再是以前物理分离的存储器。这不仅有助于加快执行速度,还减少了数据在内存和计算器之间连续传输所消耗的能量,并且由于可以在存储模块中提前处理一些简单的数据,不需要频繁地在内存系统中来回移动数据,减轻了带宽的压力。
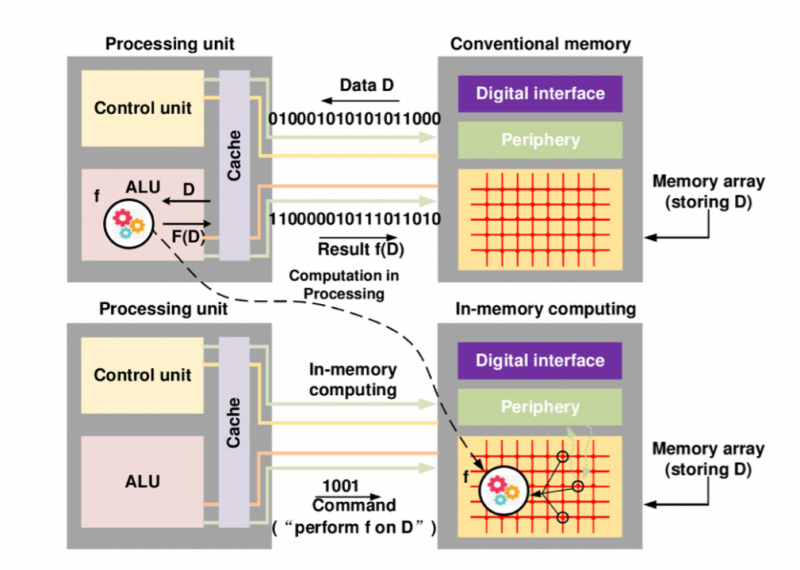
存算一体概念图
早在 1990 年代,CIM 架构的思想就非常流行,抽象出许多前人的注意力,例如 Teras、IRAM、DIVA、Active Page、FlexRAM 。1995 年,Gokhale 等人提出了一个配备设计和制造的处理器内存处理器芯片的 Terasys 系统。该芯片是一个标准的 4 位存储器,增加了一个控制每一列存储器的单位算术逻辑单元 (ALU),它可以执行本地操作和可选的读/写 OR 操作。
但是,1990 年代 CIM 体系结构的努力未能改变计算机体系结构的模式,因为存在一些实际问题和限制。首先,难以将复杂的逻辑与 DRAM 技术集成。通常,内存有 3 或 4 层金属层,但计算逻辑在制造过程中需要 10 层以上。
其次,内存的优化方向更倾向于高密度、低成本、低泄漏的晶体管,而优化的逻辑更倾向于高速晶体管。具体来说,即使在 DRAM 工艺技术中包含简单的加法器也会导致相当大的开销并降低内存的性能 。
第三,数据移动量在当时不是关键问题,摩尔定律仍然遵循规则。另外,软件和算法开发缓慢,主要应用可以找到合适的硬件加速器。此外,技术驱动的计算机体系结构使处理器的性能在当年翻了一番。综上所述,与主存集成的 CIM 针对内存密度和低功耗进行了优化。并逻辑裸片和内存裸片可以达到减少处理器和片外内存之间数据移动的目的,但是内存的区域开销引起服务器的关注。
随着互补金属氧化物半导体晶体管(CMOS)和内存技术,以前在主内存上的方法已经被重新审视,例如缓冲的 COM-parator、DRISA 和 SCOPE 。已经开发了几个关于 CIM 架构的新实现。主要工作负载,包括机器学习算法、大数据处理、云计算和物联网正在兴起,以推动硬件架构和电路搜索革命性的解决方案 。此外,时间到了后摩尔时代,计算机体系结构的技术驱动效益正在下降。新颖的非冯诺依曼架构是预计将解决数据移动问题,并且需要对 AI 处理器的性能进行巨大改进。
具有大规模并行、自适应、自学习特征的人脑中,信息的存储和计算没有明确的分界线,都是利用神经元和突触来完成的。人们开始研究新型的纳米器件,希望能够模拟神经元和突触的特性。在这类纳米器件中,忆阻器因与突触的特性十分相似且具有巨大的潜力而备受青睐。突触可以根据前后神经元的激励来改变其权重,而忆阻器则可以通过外加电压的调制改变其电导值。利用这类新型的忆阻器可以实现数据存储的同时也能够原位计算,使存储和计算一体化,从根本上消除了内存瓶颈。这类新型的忆阻器包括磁效应忆阻器(magnetic random-access memory,MRAM)、相变 效 应 忆 阻 器(phase-change random-accessmemory,PRAM)和阻变效应忆阻器(resistiverandom-access memory,RRAM)等。
模拟方式的存算一体的实现方案:利用具有多级阻态的模拟型忆阻器可以实现在模拟域的乘法-加法运算。模拟型交叉结构阵列有行列两个正交互连线,互连线的每个结点处夹着1 个忆阻器件。电压Vj 是施加在第j 列的电压值,根据欧姆定律和基尔霍夫定律,可以得到第i 行的总电流值其中Gij 为位于第j 列第i 行的忆阻器件的电导值。总电流值Ii 是电导矩阵与电压向量的乘积结果,从存内计算角度来说,模拟型交叉阵列完成乘法-加法过程只需要一步,自然地可以实现矩阵向量乘的硬件加速。相比于传统的计算过程,这样的加速阵列更加节时、节能。模拟型交叉阵列可以在稀疏编码、图像压缩、神经网络等任务中担任加速器的角色。在神经网络中,Gij 代表突触权重的大小,Vj 是前神经元j 的输出值,Ii 是第i 个神经元的输入值。下图是3×3 的交叉阵列,列线与行线分别代表神经网络中的输入神经元和输出神经元,忆阻器的电导值为神经元之间相互连接的突触权重值,利用反向传播等学习算法可以通过SET/RESET 操作来原位更新网络权重。
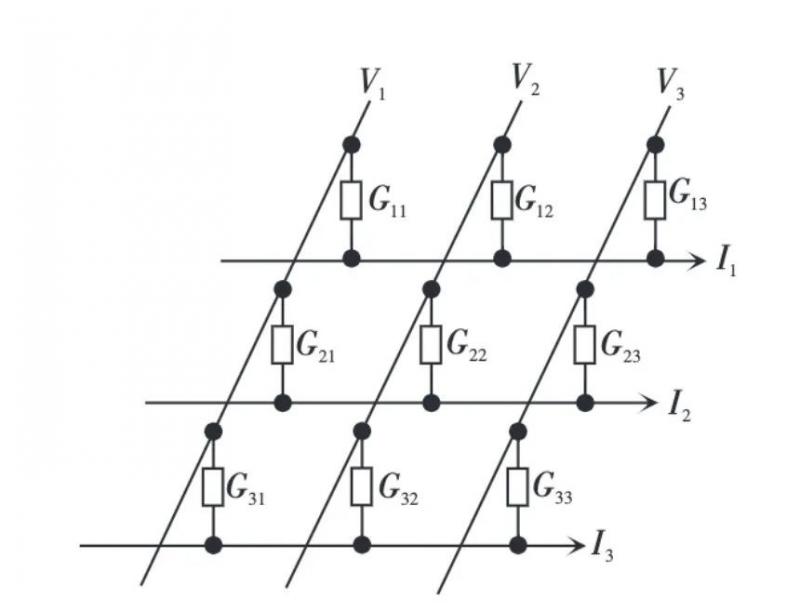
模拟型交叉结构阵列
存算一体发展现状及未来
存算一体芯片市场广阔,国内外企业、科研院所纷纷布局。据 Gartner 预测,全球内存计算市场将以每年 22% 的速度持续增长,截至 2020 年底有望达到 130 亿美元。
科研院所方面,加州大学圣芭芭拉分校谢源教授团队致力于在新型存储器件 ReRAM(阻变存储)里面实现计算的功能研究,即 PRIME 架构。清华大学刘勇攀教授团队和汪玉教授团队均参与了 PRIME 架构的研发,目前已实现在150nm 工艺下流片,在阻变存储阵列里实现了计算存储一体化的神经网络,功耗降低 20倍,速度提高 50 倍。此外,清华大学与 SK海力士联合成立智能存储计算芯片联合研究中心,未来五年,中心将致力于研发存算一体与近存储处理技术。
在产业应用方面,英特尔、博世、美光、Lam Research、应用材料、微软、亚马逊、软银都投资了 NOR闪存存算一体芯片。其中,英特尔发布的傲腾固态盘采用片外存储技术,实现 CPU 与硬盘之间数据高速搬运,从而平衡高级分析和人工智能等大规模内存工作负载的性价比。
SK 海力士在今年的ISSCC 发表存内计算的开发成果-基于GDDR 接口的DRAM 存内计算,并展示了其首款基于存内计算技术产品-GDDR6-AiM 的样本。SK 海力士表示,GDDR6-AiM 是将计算功能添加到数据传输速度为16Gbps 的GDDR6 内存产品中。与传统DRAM 相比,将GDDR6-AiM 与CPU、GPU 相结合的系统可在特定计算环境中将计算速度提高16 倍。此外,由于存内计算在运算中减少了内存与CPU、GPU 间的数据传输往来,大大降低了功GDDR6-AiM 可使功耗降低80%。SK 海力士解决方案开发担当副社长安炫表示:“基于具备独立计算功能的存内计算技术,SK 海力士将通过GDDR6-AiM 构建全新的存储器解决方案生态系统。”SK 海力士定制设计项目负责人Dae-han Kwon 也指出:“对于RNN(循环神经网络)等内存受限的应用程序,当应用程序在DRAM 中使用计算电路执行时,性能和功率效率有望显著提高。考虑到要处理的数据量将大幅增加,存内计算有望成为改善当前计算机系统性能极限的有力候选者。”
三星2022年1月12日在顶级期刊nature发表题为”crossbar array of magnetoresistive memory devices for in-memory computin”的论文,实现了在mram(磁效应忆阻器)上的存内计算,并在MNIST(Mixed National Institute of Standards and Technology database 美国国家标准与技术研究所混合数据库 包含 7 万张黑底白字手写数字图片,其中 55000 张为训练集,5000 张为验证集,10000 张为测试集。每张图片大小为 28*28 像素),使用64 × 64 mram交叉开关阵列执行了 10000 个MNIST 图像进行分类所需的所有 MAC 操作。使用BNN(二值化神经网络,神经网络量化的一种,在之前的文章中对神经网络量化有过介绍)对10,000 幅图像重复分类三次,达到了 93.23 ± 0.05% 的准确度。
与利用电流求和的方法来完成模拟方式的存算计算不同,因为mram的低电阻特性,若采用电流求和会导致模拟MAC运算时的功耗十分大,三星提出了一个基于 MRAM 单元的 64 × 64 交叉开关阵列,该阵列通过使用电阻求和进行MAC计算,从而达到了较好的效果。

64 × 64 MRAM 交叉开关阵列的显微照片
国内知存科技、新忆科技等大量初创公司也进入存算一体市场,其中知存科技开发的超低功耗语音识别存算一体芯片,采用片外存储技术,预计今实现量产,与普通专用芯片相比,其算力可提高 10 至 50 倍。
阿里达摩院于2021年11月成功研发存算一体芯片。为全球首款基于DRAM 的 3D 键合堆叠存算一体芯片。它可突破冯・诺依曼架构的性能瓶颈,满足人工智能等场景对高带宽、高容量内存和极致算力的需求。在特定 AI 场景中,该芯片性能提升 10 倍以上,效能比提升高达 300 倍。
也许在不久的将来,存算一体芯片就会出现在我们的日常生活中,改变现有芯片应用格局。

 下载ECAD模型
下载ECAD模型




.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


-%E5%89%AF%E6%9C%AC.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
