

 1096
1096
TinyMaix是面向单片机的超轻量级的神经网络推理库,即TinyML推理库,可以让你在任意单片机上运行轻量级深度学习模型。
关键特性
- 核心代码少于400行(tm_layers.c+tm_model.c+arch_cpu.h), 代码段(.text)少于3KB
- 低内存消耗,甚至Arduino ATmega328 (32KB Flash, 2KB Ram) 都能基于TinyMaix跑mnist(手写数字识别)
- 支持INT8/FP32/FP16模型,实验性地支持FP8模型,支持keras h5或tflite模型转换
- 支持多种芯片架构的专用指令优化: ARM SIMD/NEON/MVEI,RV32P, RV64V
- 友好的用户接口,只需要load/run模型~
- 支持全静态的内存配置(无需malloc)
- MaixHub 在线模型训练支持
项目地址:
https://github.com/sipeed/TinyMaix
实验了一把手写识别数字效果。效果还行。就是发现有时候7会识别成2了。
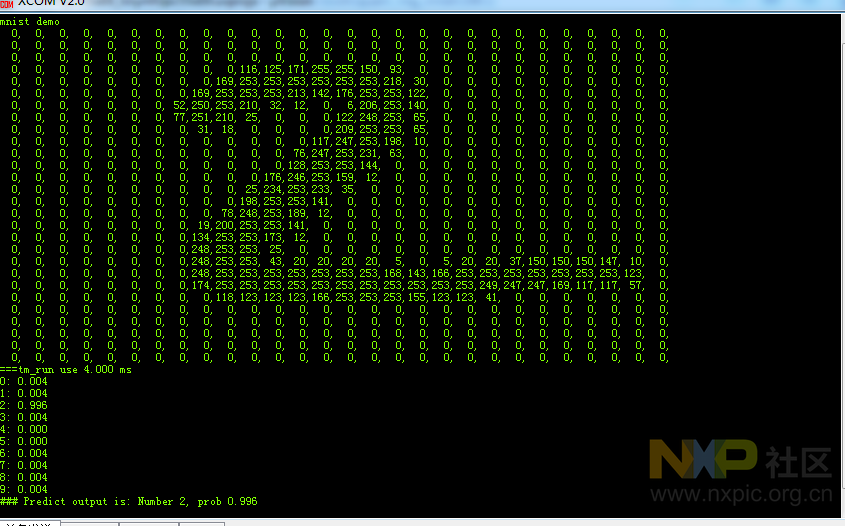
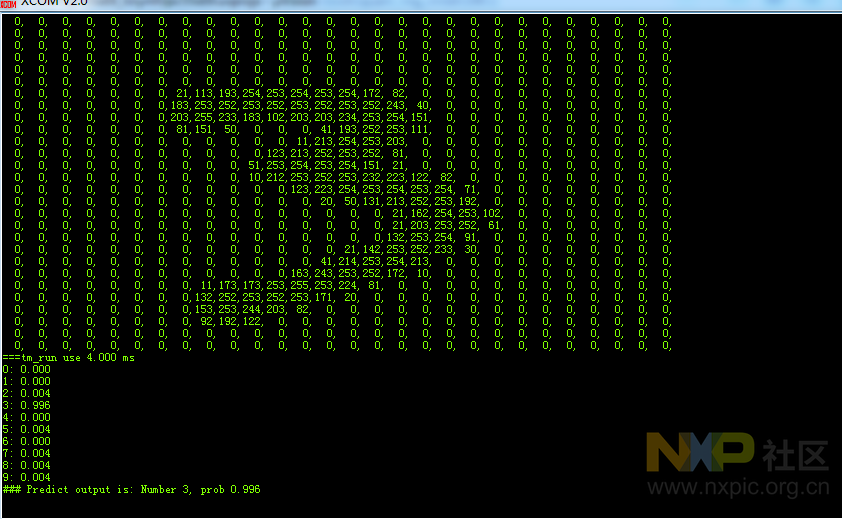

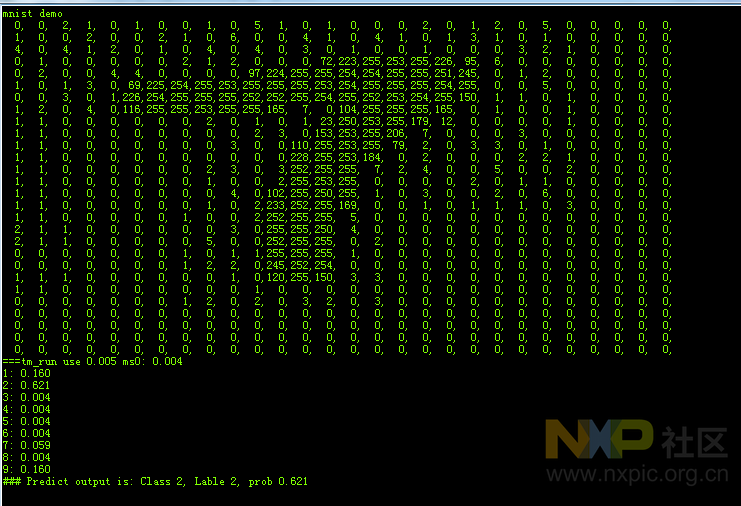

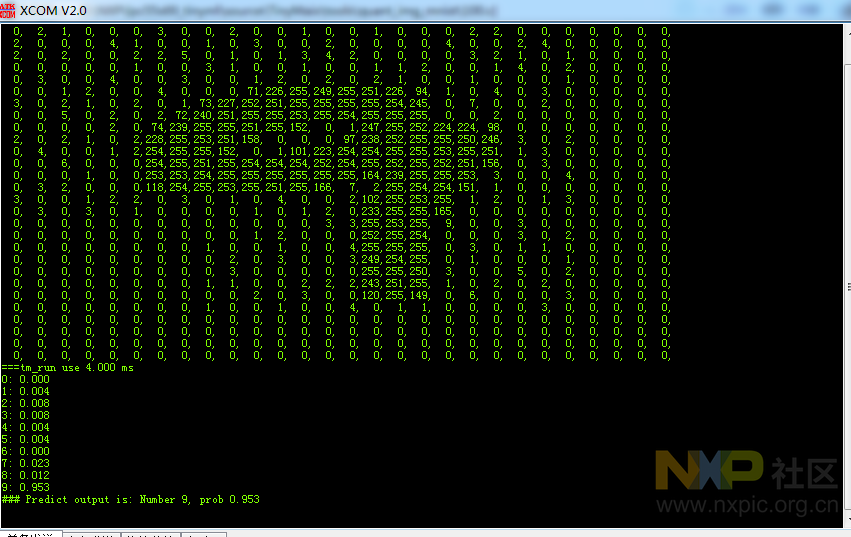
其中有个7识别成了2.
下面补充下如何移植。官方文档内有说明如何移植(readme文档),下面重新记录一下。
TinyMaix的核心文件只有这5个:tm_model.c, tm_layers.c, tinymaix.h, tm_port.h, arch_xxx.h
如果你使用没有任何指令加速的普通单片机,选择 arch_cpu.h, 否则选择对应架构的头文件
然后你需要编辑tm_port.h,填写你需要的配置,所有配置宏后面都有注释说明
注意 TM_MAX_CSIZE,TM_MAX_KSIZE,TM_MAX_KCSIZE 会占用静态缓存。
最后你只需要把他们放进你的工程里编译~
下面是我修改tm_port.h的配置,内存分配函数和printf打印。有内存分配所以注意堆空间设置大点。
/******************************* PORT CONFIG ************************************/
#define TM_ARCH TM_ARCH_CPU
#define TM_OPT_LEVEL TM_OPT0
#define TM_MDL_TYPE TM_MDL_INT8
#define TM_FASTSCALE (0) //enable if your chip don't have FPU, may speed up 1/3, but decrease accuracy
#define TM_LOCAL_MATH (0) //use local math func (like exp()) to avoid libm
#define TM_ENABLE_STAT (1) //enable mdl stat functions
#define TM_MAX_CSIZE (1000) //max channel num //used if INT8 mdl //cost TM_MAX_CSIZE*4 Byte
#define TM_MAX_KSIZE (5*5) //max kernel_size //cost TM_MAX_KSIZE*4 Byte
#define TM_MAX_KCSIZE (3*3*256) //max kernel_size*channels //cost TM_MAX_KSIZE*sizeof(mtype_t) Byte
#define TM_INLINE __attribute__((always_inline)) static inline
#define TM_WEAK __attribute__((weak))
#define tm_malloc(x) malloc(x)
#define tm_free(x) free(x)
#define TM_PRINTF(...) printf(__VA_ARGS__)
#define TM_DBG(...) TM_PRINTF("###L%d: ",__LINE__);TM_PRINTF(__VA_ARGS__);
#define TM_DBGL() TM_PRINTF("###L%drn",__LINE__);下面是时间获取配置。通过SysTick中断1ms定时uwTick++计时。
/******************************* DBG TIME CONFIG ************************************/
extern volatile uint32_t uwTick;
#define TM_GET_US() ((uint32_t)uwTick)
#define TM_DBGT_INIT() uint32_t _start,_finish;float _time;_start=TM_GET_US();
#define TM_DBGT_START() _start=TM_GET_US();
#define TM_DBGT(x) {_finish=TM_GET_US();
_time = (float)(_finish-_start);
TM_PRINTF("===%s use %.3f msrn", (x), _time);
_start=TM_GET_US();}如何使用 (API)
使用步骤-》1、加载模型-》2、输入数据预处理-》3、运行模型-》4、移除模型
加载模型
tm_err_t tm_load (tm_mdl_t* mdl, const uint8_t* bin, uint8_tbuf, tm_cb_t cb, tm_mat_t in);
mdl: 模型句柄;
bin: 模型bin内容;
buf: 中间结果的主缓存;如果NULL,则内部自动malloc申请;否则使用提供的缓存地址
cb: 网络层回调函数;
in: 返回输入张量,包含输入缓存地址 //可以忽略之,如果你使用自己的静态输入缓存
输入数据预处理
tm_err_t tm_preprocess(tm_mdl_t* mdl, tm_pp_t pp_type, tm_mat_t* in, tm_mat_t* out);
TMPP_FP2INT //用户自己的浮点缓存转换到int8缓存
TMPP_UINT2INT //典型uint8原地转换到int8数据;int16则需要额外缓存
TMPP_UINT2FP01 //uint8转换到01的浮点数 u8/255.0
TMPP_UINT2FPN11//uint8转换到-11的浮点数
运行模型
tm_err_t tm_run (tm_mdl_t* mdl, tm_mat_t* in, tm_mat_t* out);
移除模型
void tm_unload(tm_mdl_t* mdl);
测试代码流程:
int main_demo(void)
{
TM_DBGT_INIT();
TM_PRINTF("mnist demorn");
tm_mdl_t mdl;
for(int i=0; i<28*28; i++){
TM_PRINTF("%3d,", mnist_pic[i]);
if(i%28==27)TM_PRINTF("rn");
}
tm_mat_t in_uint8 = {3,28,28,1, {(mtype_t*)mnist_pic}};
tm_mat_t in = {3,28,28,1, {NULL}};
tm_mat_t outs[1];
tm_err_t res;
// tm_stat((tm_mdlbin_t*)mdl_data);
res = tm_load(&mdl, mdl_data, NULL, layer_cb, &in);
if(res != TM_OK) {
TM_PRINTF("tm model load err %drn", res);
return -1;
}
#if (TM_MDL_TYPE == TM_MDL_INT8) || (TM_MDL_TYPE == TM_MDL_INT16)
res = tm_preprocess(&mdl, TMPP_UINT2INT, &in_uint8, &in);
#else
res = tm_preprocess(&mdl, TMPP_UINT2FP01, &in_uint8, &in);
#endif
TM_DBGT_START();
res = tm_run(&mdl, &in, outs);
TM_DBGT("tm_run");
if(res==TM_OK) parse_output(outs);
else TM_PRINTF("tm run error: %drn", res);
tm_unload(&mdl);
return 0;
}怎样添加新平台的加速代码
对于新增平台,你只需要在src里添加arch_xxx.h文件并实现其中的函数即可,主要为以下几个函数(重要性降序排列,不重要的函数可以直接拷贝纯CPU运算的函数):
a. TM_INLINE void tm_dot_prod(mtype_t* sptr, mtype_t* kptr,uint32_t size, sumtype_t* result)
实现平台相关的点积函数,可以使用MAC相关的加速指令加速。
b. TM_INLINE void tm_dot_prod_pack2(mtype_t* sptr, mtype_t* kptr, uint32_t size, sumtype_t* result)
实现平台相关的双通道点积函数。(仅提供到双通道是因为有些芯片平台的寄存器不足以支持更多通道的点积加速)
c. TM_INLINE void tm_postprocess_sum(int n, sumtype_t* sums, btype_t* bs, int act, mtype_t* outp, sctype_t* scales, sctype_t out_s, zptype_t out_zp)
实现平台相关的批量后处理函数,注意n为2的次幂。
d. TM_INLINE void tm_dot_prod_3x3x1(mtype_t* sptr, mtype_t* kptr, sumtype_t* result)
实现平台相关的3x3点积加速
e. TM_INLINE void tm_dot_prod_gap_3x3x1(mtype_t* sptr, mtype_t* kptr, uint32_t* k_oft, sumtype_t* result)
实现平台相关的3x3 gap的点积加速
工程文件:
lpc55s69_tinyml_s.zip (14.5 MB)

 下载ECAD模型
下载ECAD模型






