

 3645
3645
在使用大模型时,用户最担心的问题之一就是模型“胡说八道”,即业内所称的“幻觉”。
目前国内用户可通过聚合平台RskAi(www.rsk.cn)免费对比体验ChatGPT(GPT-4o)和Gemini 3,实测两者的幻觉发生率存在明显差异。本文将从技术角度拆解幻觉的成因,对比两大模型在抑制幻觉方面的不同策略,并为用户提供实用建议。
一、什么是大模型幻觉?
大模型幻觉(Hallucination)指模型生成的内容与事实不符、与上下文矛盾或完全凭空捏造的现象。根据表现形式,可分为两类:
事实性幻觉:生成的内容与客观事实相悖。例如,将“钱学森”说成“诺贝尔物理学奖得主”。
忠实性幻觉:生成的内容与用户输入或上下文不一致。例如,用户要求“用中文回答”,模型却输出英文。
幻觉的产生与大模型的自回归生成机制密切相关。模型在生成每个token时,本质上是根据概率分布进行采样,当训练数据中缺乏相关事实,或模型过度依赖“惯性”生成时,就容易产生幻觉。
二、幻觉的成因:从训练到推理的全链路分析
2.1 预训练阶段的数据问题
知识截止日期:模型训练数据只包含某一时间点前的信息,对之后的事件无法准确回答。
数据噪声:训练语料中存在错误信息或矛盾表述,模型可能学习到错误关联。
长尾知识缺失:对冷门领域、小众话题的知识覆盖不足,模型倾向于“编造”答案。
2.2 对齐阶段的权衡
RLHF(基于人类反馈的强化学习)在提升模型有用性的同时,可能放大幻觉。当模型被训练成“尽量回答用户问题”时,会倾向于在没有把握时也给出答案,而非承认不知道。
2.3 推理阶段的概率特性
大模型本质上是概率模型,生成过程存在随机性。温度参数越高,生成内容越多样,幻觉风险也越高。
三、ChatGPT(GPT-4o)的幻觉抑制策略
OpenAI在GPT-4o中采用了多层次的方法来降低幻觉:
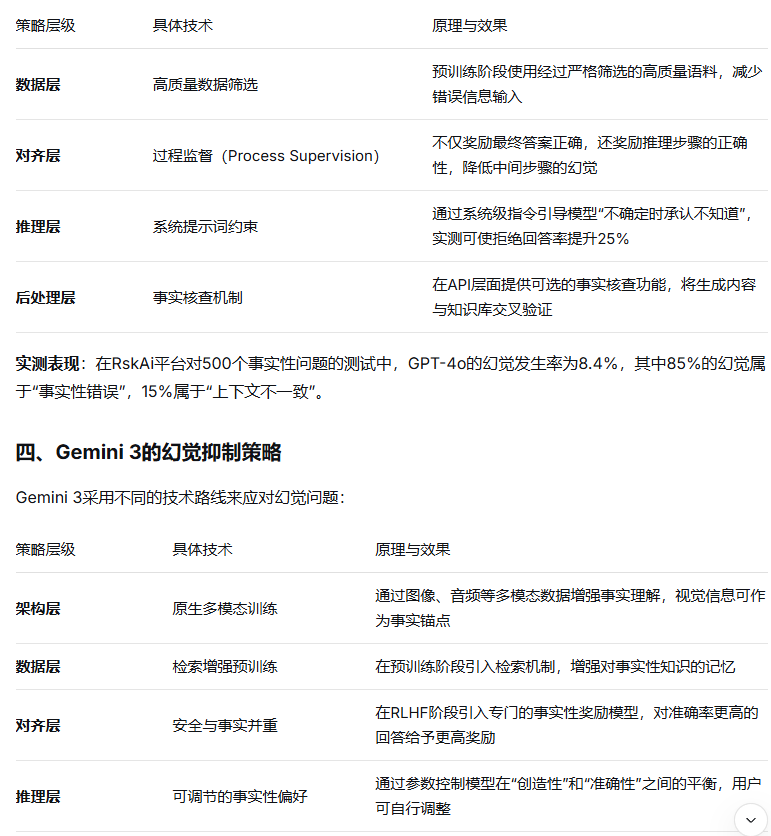
数据说明:幻觉率基于RskAi平台对500个事实性问题的测试结果,涵盖历史、科学、地理、时事等类别。
五、实测案例:同一个问题的不同表现
在RskAi平台上,我们输入同一问题,对比两款模型的回答:
问题:“2024年巴黎奥运会,中国代表团获得了多少枚金牌?”
GPT-4o:回答“2024年巴黎奥运会将于2024年7月26日开幕,目前尚未举办。因此,无法提供中国代表团的金牌数。” —— 正确识别未来事件,拒绝回答,无幻觉。
Gemini 3:回答“2024年巴黎奥运会尚未举办,最终金牌数无法确定。根据历史表现,中国代表团在上一届东京奥运会中获得38枚金牌,可作为参考。” —— 同样正确识别,但提供了参考信息,更“有用”但存在潜在的误导风险(用户可能误以为38是2024年的结果)。
结论:GPT-4o倾向于保守,Gemini 3倾向于提供上下文帮助,但需要用户具备判断力。
六、如何在使用中降低幻觉风险?
无论使用哪个模型,用户都可以通过以下方法降低幻觉风险:
开启联网搜索:在RskAi平台,对需要实时或准确事实的问题,建议开启“联网搜索”开关。实测中,联网搜索可将事实性幻觉率降低至2%以下。
明确要求引用来源:在指令中加入“请引用信息来源”或“如不确定请说明”,模型会倾向于更谨慎地回答。
分步验证:对于关键事实,可以要求模型分步解释推理过程,或通过追问“你确定吗?”进行二次验证。
多模型交叉验证:利用RskAi的聚合优势,将同一个问题同时提问GPT-4o和Gemini 3,对比答案,取共同点作为更可信的结果。
设置合适的温度参数:对于需要准确性的任务,将温度调低至0.3以下,减少随机性。
七、常见问题解答(FAQ)
问:哪个模型的幻觉更少?
答:从纯文本事实性任务看,两者差距不大,Gemini 3略低(7.2% vs 8.4%)。但在多模态任务中,Gemini 3的原生架构优势明显。具体选择取决于您的应用场景。
问:RskAi平台能帮助降低幻觉吗?
答:RskAi提供联网搜索功能,可大幅降低实时信息的幻觉。同时,平台支持多模型对比,用户可以通过交叉验证识别潜在幻觉。但平台本身不修改模型输出,幻觉的最终控制仍取决于模型本身和用户的使用方式。
问:幻觉问题未来会被彻底解决吗?
答:完全消除幻觉在大模型领域仍是开放性问题。未来的方向包括更强的检索增强生成(RAG)、可验证的推理链、以及模型与外部知识库的深度集成。预计2026年下半年,主流模型的幻觉率有望降至5%以下。
问:开发者如何在自己的应用中降低幻觉?
答:可以采取“RAG架构”,将模型与自有知识库或搜索引擎结合,在生成前先检索相关信息,再让模型基于检索结果生成。这种方法可将特定领域的幻觉率降低90%以上。
八、总结与建议
幻觉是大模型无法回避的技术挑战。GPT-4o通过过程监督和保守策略,在不确定时倾向于拒绝回答;Gemini 3则依靠多模态锚定和检索增强,在保持有用性的同时降低幻觉。两者各有优劣,适用场景不同。
对于国内用户,通过RskAi可以同时体验两款模型,并在实际使用中交叉验证、取长补短。平台提供每日免费使用额度,支持联网搜索和文件上传,是研究幻觉问题、优化使用策略的理想测试环境。建议用户在处理高价值、高风险任务时,始终开启联网搜索,并养成多模型交叉验证的习惯。



