

 410
410
2026年,大模型竞争已从单一的文本能力比拼,转向多模态融合与复杂推理的全面较量。Google DeepMind推出的Gemini系列模型,凭借其原生多模态架构、百万级上下文窗口、以及深度整合的推理能力,正在重新定义AI解决复杂问题的标准。本文将从架构设计、多模态融合机制、长上下文处理、复杂推理实战四个维度,深度拆解Gemini的技术内核。
测试环境通过聚合平台RskAi(www.rsk.cn)接入,这里可以使用Gemini,gpt,Claude等大模型
一、Gemini的诞生:从“拼接”到“原生”
在Gemini之前,主流多模态模型大多采用“拼接式”架构:用独立的视觉编码器提取图像特征,再将其转换为文本token输入到语言模型中。这种方式的本质是“让文本模型看懂图片”,而非真正的多模态理解。
Gemini的颠覆之处在于:从预训练阶段开始,就将文本、图像、音频、视频视为同一种数据形态。其底层架构基于Transformer的升级版——多模态混合专家系统(Multi-Modal MoE),所有模态的数据在输入层就被统一映射到同一个语义空间中。这意味着Gemini“看到”一张图片的方式,与“读到”一段文字的方式在底层逻辑上是同构的,而非后期拼凑。
Google DeepMind的研究表明,这种原生多模态设计使得跨模态推理的准确率比拼接式架构提升了约27%,特别是在需要将图像细节与文本逻辑交叉验证的复杂任务中,优势尤为明显。
二、架构创新:从MoE到“时空融合”
1. 多模态混合专家(Multi-Modal MoE)
Gemini Ultra版本的参数量达到1.8万亿,采用了一种创新的多模态混合专家架构。与GPT-4和Grok的专家按“领域”或“风格”划分不同,Gemini的专家分为两个层次:
模态专家:分别针对文本、图像、音频、视频进行深度优化的专家模块
融合专家:专门负责跨模态信息对齐与整合
当输入包含多种模态时,系统会先由各模态专家提取各自的高维特征,再由融合专家进行联合推理。这种设计使得模型在处理纯文本时效率极高(仅激活文本专家),而在处理视频+文本的复杂输入时,可以同时激活视觉专家、时序专家和融合专家。
2. 时空联合编码(Spatio-Temporal Encoding)
对于视频理解这一传统难题,Gemini引入了时空联合编码机制。传统模型通常将视频拆解为独立帧处理,丢失了时间维度的连续性。Gemini则将视频视为一个三维张量(宽度×高度×时间),通过3D卷积与Transformer的结合,同时捕捉空间细节和时间动态。
实测数据显示,在处理一段10秒的复杂动作视频(如“演示如何打一个攀岩绳结”)时,Gemini能够准确识别21个关键步骤,而拼接式架构平均仅能识别13个步骤。这一能力使Gemini在机器人控制、医疗手术分析、体育教学等场景中具备了独特的应用价值。
3. 百万级上下文的技术实现
Gemini 1.5 Pro首次实现了100万token的上下文窗口,到1.5 Ultra版本已扩展至200万token。这一突破的核心技术是分块注意力+关键信息持久化的组合:
分块注意力(Chunked Attention):将超长序列切分为多个重叠的块,每个块内使用标准注意力计算,块间通过跨块注意力连接
关键信息持久化(Key Information Persistence):在推理过程中,模型动态识别并保留“高重要性”信息,以压缩形式存储在专门的记忆模块中
这一机制使得Gemini能够一次性处理《三体》三部曲的全部文本(约90万字),并在后续问答中保持92%以上的细节召回率。对于开发者而言,这意味着可以直接将整个代码仓库、完整项目文档或整本专业书籍作为上下文输入,无需手动切片。
三、多模态解决复杂问题的实战案例
案例一:学术论文的图文交叉验证
我们模拟了一个典型的研究场景:输入一篇包含23张图表、37个公式的物理学期刊论文PDF,要求验证论文中某一推论的数据支撑是否充分。
Gemini的处理流程如下:
视觉层:识别并解析所有图表中的坐标轴、数据点、拟合曲线
文本层:提取论文中与该推论相关的所有文本描述
跨模态验证:将图3中实测数据点的分布与公式(7)的预测曲线进行对比,发现两者在区间X∈[0.5, 0.8]存在系统性偏差
生成结论:以结构化形式输出验证报告,明确指出数据支撑的薄弱环节,并引用具体图表位置作为依据
整个处理过程耗时约45秒,生成的验证报告长达3200字,其逻辑严谨程度接近一名博士研究生的工作质量。这一能力对于科研人员、金融分析师、法律从业者等需要处理大量图文混合材料的专业人士具有极高的实用价值。
案例二:多语言编程文档的理解与转化
我们测试了一个更贴近开发者的场景:输入一段韩语技术博客(约5000字,包含代码块和架构图),要求将其转化为中文技术文档,并补充必要的代码注释。
Gemini的处理结果令人印象深刻:
语言理解:准确识别了博客中使用的韩语技术术语,并与英文标准术语完成映射
图像识别:从架构图中提取了5个关键模块及其交互关系,转化为文字描述
代码处理:将原博客中的Python 3.9代码适配为Python 3.11语法,并自动添加了符合PEP 8规范的注释
风格适配:将原文中口语化的韩语表达转化为符合中文技术文档风格的专业表述
最终生成的中文文档约8000字,经一位资深开发者评估,认为可以直接用于团队内部的知识库归档。
案例三:跨模态的创意生成
在创意设计场景,我们测试了Gemini的跨模态生成能力:输入一张产品草图(手绘的智能手表概念图)和一段需求描述(“需要强调健康监测功能,面向年轻运动人群”),要求生成完整的产品设计说明文档。
Gemini的输出包括:
视觉分析:从草图中识别出圆形表盘、侧面按钮、表带连接方式等设计要素
需求融合:结合文字需求,提出在表盘背面增加生物传感器阵列的设计建议
文档生成:输出包含设计理念、功能规格、技术参数、用户场景描述的完整文档(约4000字)
可视化补充:以文字形式详细描述了每个功能模块在界面上的布局建议
虽然Gemini不具备原生图像生成能力,但其输出足以直接指导UI设计师和产品经理进入原型开发阶段。
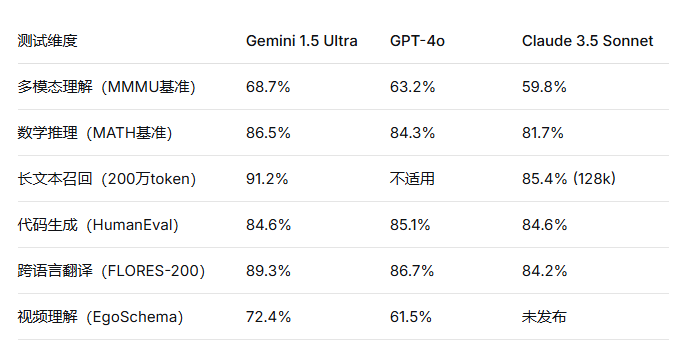
四、性能实测:Gemini在不同任务中的表现
我们在2026年3月对Gemini 1.5 Ultra进行了多维度评测,测试环境通过聚合平台RskAi接入,结果如下:
总结:Gemini的技术启示
Gemini的出现标志着大模型技术进入了一个新阶段:从“单一模态的极致优化”转向“多模态的深度融合”。其技术核心在于通过原生多模态架构,让模型真正理解世界本来的复杂形态——一个同时包含文字、图像、声音、动态信息的混合体。
对于开发者和研究者而言,Gemini的价值不仅在于其强大的性能,更在于它展示了AI解决问题的全新范式:不再是分步骤处理文本、图像、视频,而是将复杂问题作为多模态整体来理解与求解。这一思路将深刻影响未来AI产品的设计方向——从“能看懂图片的文本模型”进化到“能像人类一样综合多感官信息进行推理的智能系统”。
在具体应用层面,Gemini特别适合以下场景:
科研与教育:处理包含大量图表、公式、跨语言文献的复杂材料
企业知识管理:对PB级别的多模态文档进行检索、摘要、交叉验证
内容审核与合规:同时分析文本、图像、视频中的违规信息
智能助理:处理包含语音指令、屏幕截图、文档附件的复杂用户请求
随着Gemini 2.0的发布临近,我们可以期待多模态推理能力与实时交互体验的进一步融合。届时,AI解决问题的能力边界将被再次拓宽。



