


















 3759
3759
神经网络芯片NPU(Neural Processing Unit),是为了专门处理神经网络算法而存在的。NPU的主要竞争对手,就是大家更熟悉的GPU、特别是英伟达的GPU。
说是竞争对手,不如说统治级的存在更贴切。事实上,在GPU面前,NPU就是个弟弟。GPU凭借成熟的生态和良好的易用性,已经占领了AI芯片领域的大部分市场份额。
面对GPU的统治,NPU能否破局?今天的文章,就为大家解读四篇来自上一届DAC大会的NPU论文,也算是为7月份即将召开的新一届DAC预热一波。一起来看看在研究者的眼中,NPU的破局之路究竟有哪些。
通用与专用:不可兼得的鱼与熊掌?

标题意译:支持细粒度任务划分的基于脉动阵列的神经网络处理器
一句话总结:在架构设计中引入少量的额外电路,使得脉动阵列能够支持细粒度的任务划分;通过让一个神经网络处理器同时完成多个网络模型运算的方式,实现了硬件资源利用率的显著提升。
技术细节:
对于神经网络加速器设计,通用性与专用性间最佳的平衡点究竟在哪?这是学术界与工业界都颇为关注的难题。
拿之前介绍过的脉动阵列结构来说,当用脉动阵列来完成矩阵乘法时,数据流呈现出很规则、工整的特征,与之对应的是十分简单的控制逻辑。得益于此,脉动阵列结构在神经网络加速器架构中是非常常见的一个选择,比如我们可以在Google TPU等产品中看到它的身影。
但这种简洁其实是一把双刃剑,脉动阵列在处理网络模型时常常会面临因灵活性差导致的硬件资源利用率不够高的困境。而这篇论文便在这一问题上提供了一种新的思路。

在传统的脉动阵列中,由于缺少复杂的控制逻辑,数据传输过程是很死板的:只有当数据从阵列的一侧传递到另一侧,整个传递过程才能被判定为结束。
而通过引入“水平边界线”和“垂直边界线”的概念,一个大的脉动阵列结构在功能上被划分为二至四个子结构。“水平/垂直边界线”分别定义了水平/垂直数据传输的终点/起点。通过设定这两种分界线的位置,阵列能够被根据目标应用的需求灵活地被划分。
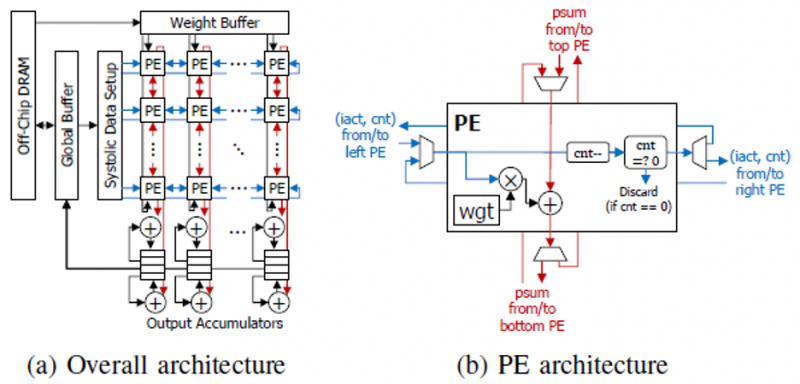
为了呼应动态划分的思路,数据通路也被相应地扩展了:相邻的处理单元间的数据传输原本只支持向右和向下两个方向,如今则是四个方向都成为了可能。
如何用尽可能少的硬件资源实现上述逻辑呢?作者选择了利用计数器来实现“水平边界线”这个概念:当水平数据传输的次数达到了设定值,传输行为便会停止。
除了微架构创新本身,文章里还能看到很多颇具启发性的“小心机”。
一方面是动态的硬件资源分配:当一个神经网络模型的处理完成后,硬件资源将根据其余的处理任务重新进行分配,避免硬件资源的浪费。
另一方面是自动化的思想:通过开发调度器,根据待处理的神经网络模型自动地寻找最佳的分界线设置,实现最佳的处理效果。
至于通用性,脉动阵列真的注定与通用性无缘吗?此前一个取得了显著进展的思路来自2020年HPCA的最佳论文SIGMA:用数个由网络连接的链状运算单元来取代二维的阵列,以实现更灵活的脉动式运算;而此研究提供了另一个思路,让我们仍然可以相信脉动阵列能带我们走向更高性能的神经网络加速器设计。
NPU的自动设计:无稽之谈还是确有其事?

标题意译:神经网络加速器架构搜索技术
一句话总结:本文实现了对于神经网络加速器的架构设计空间的高质量的自动探索:通过更好地为搜索问题建模,并有效地将对于调度方案的探索任务从架构设计的探索任务中解耦出来,NAAS生成的架构设计拥有非常优越的性能,成功实现了在功耗、时延等评价标准下超越一些具有代表性的既有设计。
技术细节:
芯片设计里有一个概念,叫设计空间探索。用大白话讲,它的意思就是在很多种可能里,选择最好的方案。
就拿神经网络举例,它有各种模型、各种参数,也会对应各种NPU芯片的实现方式。所以如何根据模型和参数,自动确定最优化的芯片架构,就是设计空间探索的重要意义。
要想实现对于神经网络加速器的架构设计空间的高质量的自动探索,目前主要的难点有两个:如何有效地定义探索空间,以及如何高效地完成探索任务。
打个比方,如果将搜索的范围局限于欧洲大陆,那么即使花上再多时间、找遍每一寸土地,也不可能发现新大陆。搜索的方式方法也非常重要:由于探索空间很大,启发式的寻找(比如根据沿途收集的信息不断调整航线)很可能比地毯式的搜索(比如根据经纬度一处处地排查)来得可行得多。

NAAS为什么能比现有的NPU自动化设计工具做得更好?因为它成功地将架构的探索任务与调度方案的探索任务相解耦,前者解决的是「架构该怎么定」的问题,而后者解决的是「定下的架构该如何完成运算」的问题。
定义前者时,又可以将探索任务其进一步地分为两个子任务:硬件资源的数量、它涵盖了处理单元的数量、一二级缓存的容量大小、硬件的连接方式,比如运算单元的连接方式等,而这是此前的研究所忽略的。因此,这样的定义方式增大了探索空间,大大提高了“发现新大陆”的可能性。
此外,作者采用了一种基于生物学理论的进化算法来渐进式地寻找最优解。当硬件架构由工具自动地确定后,NAAS还研究了如何进一步地优化网络模型,即软件侧,意图在硬件表现不受影响的前提下实现更高质量的应用。
通过将NAAS与神经结构搜索技术(Neural Architecture Search, NAS)交互,软硬件技术层面上的闭环或许会带来更多可能:当客户数据成为了唯一的成本,神经网络模型搭建和硬件实现都能由计算机高质高效地完成,这样基于神经网络的解决方案将在越来越多的应用场景中受到青睐。
近似计算:没人能拒绝免费的午餐

标题意译:低硬件成本的近似乘法器误差补偿技术
一句话总结:作者分析了一种常用的近似乘法器设计所导致的误差,引入了可控制变量的概念对该误差进行补偿,并给出了关于该变量的取值与补偿效果间的关系的数学证明,能够在不引入大量额外电路开销的前提下,有效弥补近似乘法器带来的神经网络模型精度下降。
技术细节:
目前,大部分神经网络模型都伴随着巨大的运算量,而其中占比很大的计算类型是乘累加运算。一个热点方向,就是用近似乘法器取代精确乘法器,从而立竿见影地降低功耗。
但是用这种“近似计算的方法”必然会引入计算误差,进而导致神经网络模型精度的下降,这无异于“捡了芝麻丢了西瓜”。
如何规避这部分负面影响?重新训练神经网络模型是一个较为主流的选择。
重训练的本质是:让神经网络模型通过参数的调整,自行“消化”掉近似乘法器带来的误差,保证最终的计算结果与之前的几乎一致。
然而,重训练也有不少缺点。首先,神经网络模型的「训练」过程往往伴随着比「推理」大得多的计算量。因此,重训练有悖于我们通过近似计算技术节约功耗的这个初衷。但最为致命的是,重训练并不完全消除近似计算的误差。这是因为误差的产生与输入数据有关,重训练无法让网络模型掌握广义上的抑制误差的能力。
所以,通过近似计算降低功耗只能成为一纸空谈了吗?
在这篇论文里,就提出了抑制近似计算造成的误差的算法,以及相应的硬件实现。
具体的思路是,我们可以在近似计算的结果上加上一个补偿量来模拟精确结果,并将这个变量称为“可控制变量”。通过严谨的数学推导,作者证明了:当这个可控制变量的取值满足一定的条件时,经补偿后的近似结果将非常接近精确结果(此时,误差的均值为零,且方差可以取到最小值)。
同时作者指出,只需要极小的电路开销即可实现对于该误差补偿技术的硬件支持。
以基于脉动阵列的神经网络处理器作为目标案例:该补偿技术的硬件实现仅需要往二维阵列中扩展一列处理单元。
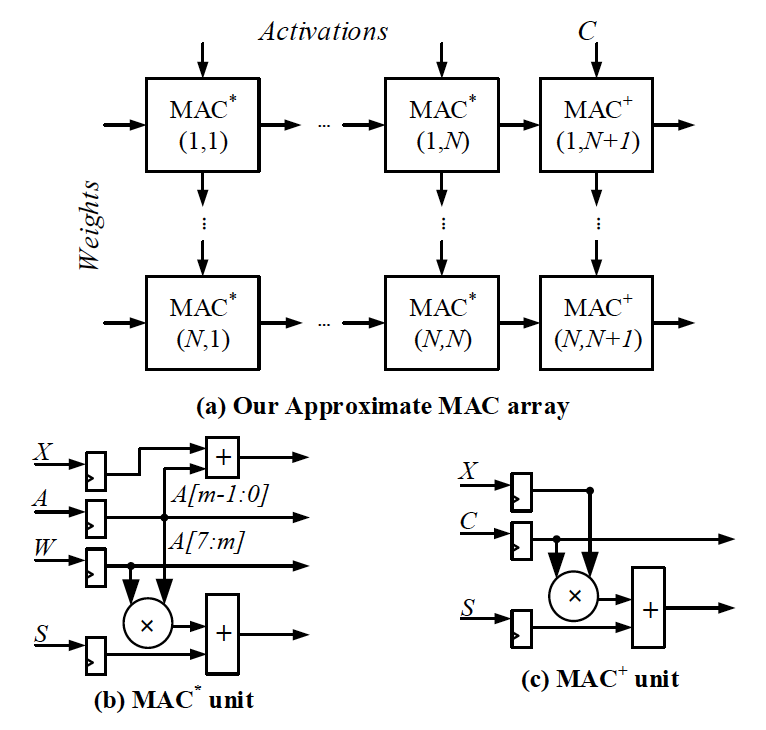
根据测试结果,在模型的精度平均只下降了0.16%的微小代价下,NPU的功耗降低了24%。值得注意的是,近似乘法器的应用并不局限于某一特定的处理器架构,所以这种思路或许也可以扩展到其他的场景。
此外,研究的整体思路属于非常典型的“软硬件协同设计”。大到架构设计、小到NPU设计,软硬件协同设计都称得上是当下一大主流的设计理念,这也是和大家分享这篇论文的另一个原因。
如何评估一个NPU设计:又快又准的那种?

标题意译:支持系统级性能评估的NPU生成平台
一句话总结:Gemmini的目的不仅仅是生成NPU本身,更是支持对于包括host CPU、存储资源在内的整个硬件系统的配置,使用者能够从系统的角度,便捷且准确地评估硬件性能,通过协调系统中各组件的配置来实现最优的设计。
技术细节:
有过装机经验的读者朋友们肯定深有体会:单个组件的优异性能并能保证整个硬件系统就会有理想的性能——因为后者并不是前者的简单叠加。
同样的,一个NPU在实际的应用中也不是独立工作的,而是需要与系统中的其他硬件相配合。
“生淮南则为橘,生于淮北则为枳”,有没有可能在NPU的设计阶段就将其未来的工作环境考虑在内,从而设计出“实用”的NPU呢?
这个来自伯克利和MIT的工作给出了答案。
通过指定参数配置来便捷地生成NPU的软件框架与平台并不少见,但是Gemmmini显然往前迈了一大步:可配置的不仅仅局限于加速器中的MAC阵列和池化单元,而是涵盖了整个硬件系统的各组成部分——从host CPU到存储体系均为可配置的对象。

Gemmini能够评估生成的加速器的性能。这一评估是基于系统层面的,这意味着各种影响性能的潜在因素,比如组件间的资源冲突、缓存的一致性等问题都能够被考虑在内,所以评估结果是相当可靠的。
从另一个角度来说,通过使用Gemmini平台,我们能够清晰、直观地看到系统中的其他部分将如何影响、制约加速器达到理想的性能表现,进而通过不断地调整各组件的配置,得到整体性能最优的系统设计。
伯克利作为RISC-V的摇篮,其在结构体系方面的辉煌历史自然不必多言。由伯克利的研究团队出品的Gemmini充分展现了研究者们扎实的技术积累,令人深感格局大开,而Gemmini也凭借其开创性,一举夺得本届DAC的最佳论文奖。
小结
面对GPU的统治, NPU能否破局?
这个问题,没有人知道答案。但从学术会议和相关研究不断攀升的热度可以看到,尽管GPU目前赢得了市场,但我们还远远没有进入盖棺定论的阶段。
AI时代的第一个十年,GPU占了绝对的上风。但下一个十年呢?






.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)

-1-%E5%89%AF%E6%9C%AC.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
