

 1539
1539
IT产业正在发生两大根本性转变:一是CPU性能无法持续增长,每五年以同样成本获得十倍性能提升的故事已经结束,并且,也无法用同样的成本和电力消耗负担这种增长态势;二是AI大模型对数据中心的规模、算力等需求不断攀高,使得整个数据中心的计算和通信架构需要被重塑。
这样的变化迫切吗?走在AI大模型竞赛最前沿的NVIDIA看到,迫切且重要。随着GPU的处理性能不断提升,数据中心的网络传输能力面临瓶颈。也正是如此,NVIDIA专门针对以太网环境,推出了创新的Spectrum-X 网络平台,致力于提高基于以太网 AI 云的性能与效率。
面向超大规模生成式AI,NVIDIA推出加速以太网平台
NVIDIA Spectrum-X的核心是 Spectrum-4 以太网交换机、BlueField-3 DPU、LinkX高性能线缆/模块和NVIDIA端到端加速软件,与传统以太网相比,实现了1.7倍的整体AI性能和效能提升,可在多租户环境中提供一致、可预测的性能。

Spectrum-4作为全球首款专为AI网络打造的51.2Tb/s以太网交换机,可以实现无损RoCE网络的大规模、可扩展和高性能,与主机端的 BlueField-3 DPU和NVIDIA LinkX线缆及模块相互协同,构建起一个专为AI云优化的端到端400GbE网络。
NVIDIA Spectrum-4 单台交换机即可实现突破性的 128 个 400Gb/s 端口的连接,使用两层叶脊拓扑可以连接超过 8,000 个400G 端口,以支持 AI 云的增长和扩展,同时保持极高的性能和极低的网络延时。
驱动Spectrum-X的加速软件在交换机端包括Cumulus Linux、开源SONiC和NetQ等,共同助力该网络平台的性能实现。在主机端包括BlueField-3 DPU的核心软件—— NVIDIA DOCA软件框架以及其它加速软件等,便于开发人员构建软件定义的云原生AI应用。
重塑数据中心计算和网络架构
面对激增的数据量,数据中心越来越需要整体运作。以往单一的、简单的应用,可能只需调用几台服务器即可,甚至一个VM就可以满足需求。但是,随着AI驱动的负载规模越来越大,甚至需要调动整个数据中心资源协同工作来完成一项工作,也就是说,整个数据中心越来越成为一台“大计算机”,这就需要从底层对数据中心整体架构进行重塑,保证数据中心整体的效率和性能,而计算和通信网络架构是两大核心。

据NVIDIA网络技术专家崔岩介绍,依据集群中的GPU数量和所支持的应用负载,可以将数据中心应用场景分为三大类:传统的云计算场景、生成式AI云、以及AI工厂。
其中,AI工厂是NVIDIA面向大规模、大算力、高性能场景下,创造的新的网络应用场景,最近的一些大语言模型都是基于NVLink+InfiniBand这种无损网络架构实现的;第二种是多租户、工作负载多样、且需要融入人工智能和生成式AI的场景,可以用最新推出的Spectrum-X以太网架构;第三种是传统云计算场景,基于传统以太网架构。
“加速计算和生成式AI的结合创造出了一个新的数据中心市场,我们需要重塑数据中心的计算和通信架构。NVIDIA提出了整体的加速计算架构,GPU、CPU、DPU的三U一体,就是NVIDIA提供的多样性高性能硬件计算平台和网络通讯平台。”崔岩表示,“此外,NVIDIA 全新推出的Spectrum-X以太网网络架构,区别于原来的面向企业应用的以太网(负载效率不太高,有长尾延时和大量抖动情况等),是专门为生成式AI量身打造的以太网平台,针对RoCE进行了端到端的优化,并且可以对端到端网络进行编程,在大规模、高负载环境下能够提供更好的性能,很好地满足了新型生成式AI云对高性能网络的需求。”
如何满足生成式AI所需的网络能力?
NVIDIA网络亚太区高级总监宋庆春指出,大模型参数规模的扩大,导致GPU训练集群越来越庞大。当一个大模型跑在几百、几千、上万个GPU集群上时,性能不仅取决于单一GPU、单一服务器,也取决于网络性能,一定要有非常高的通信效率。如果网络利用率不高,就会直接导致GPU通信效率不高,使得GPU集群能效受限。
此外,AI训练不允许任何数据丢失情况的发生,使得无损网络变得非常重要,这就需要对传统以太网进行改造。
崔岩介绍,NVIDIA通过BlueField-3 DPU 和Spectrum-4交换机的端到端优化设计,采用基于优先级的流量控制机制,实现了无损以太网,通过主机端 BlueField-3 DPU 和Spectrum-4交换机的配合,创新地实现了在无损RoCE网络上的逐包动态路由,大幅提升了网络通信效率。而在传统以太网上,对于一条流来演,选好一条转发路线后就顺序进行发包,即使出现拥塞或其他特殊情况,也无法动态改变。
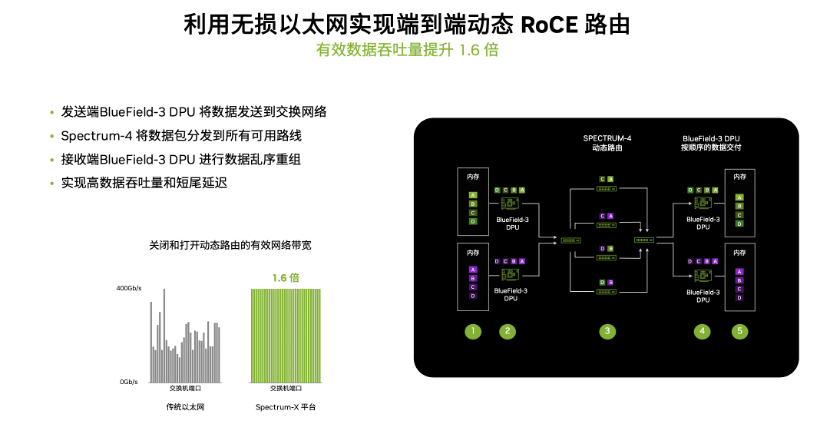
如上图所示,绿色和紫色分别代表两个工作负载,都拆分为A、B、C、D四个数据包。在动态路由机制下:在发送端由BlueField-3 DPU将数据包传给Spectrum-4交换机,由Spectrum-4交换机将数据包分发到所有可用路线(执行的是对数据包逐包进行最佳路径的选择);当数据包通过不同路径到达接收端时,再由接收端的BlueField-3 DPU进行数据乱序重组。这样一来,可以充分利用交换机之间的链路,让数据包能够走不同的最优路径到达接收端,从而提升整体网络性能。
从上图左侧的性能对比可以看出,传统以太网的带宽起伏非常大,而基于Spectrum-X无损网络端到端的动态路由机制,每条链路都得到充分利用,可以提升1.6倍有效带宽。
此外,通过可编程拥塞控制实现的业务性能隔离技术也非常关键。在云端跑多个训练任务时,不同工作负载会影响彼此性能,而通过任务性能隔离,能够优化总体性能,让每个工作负载都达到理想的性能。

在AI训练任务的数据传输过程中,往往存在发送端和接收端是多对一的情况,如果是传统的、没有拥塞控制的网络,就会导致接收能力不足,在末端的交换机发生拥塞。如上图中,因为紫色数据包是排在绿色数据包之后,由于绿色拥塞,导致紫色数据包变成牺牲流。如果是两个租户,就会因为一个工作负载影响另一个工作负载。
而基于Spectrum-X端到端平台,BlueField-3 DPU可以对于网络中遥测数据进行探测,通过主动采集Spectrum-4遥测机制生成的拥塞状况数据,在拥塞发生的早期阶段就提前调节以什么样的速率发送数据。通过实时检测拥塞点,用可编程拥塞控制技术,来监控和控制数据流,从而实现不同工作负载之间的性能隔离。从实际的性能对比可以看出,性能隔离技术可以将NCCL ALLREDUCE带宽提升2.5倍。
“这就好比是通过高德地图看到入口已经堵车,那么就减缓到那里的速度或者减少车流量,让拥塞得到缓解;或者发生‘堵车’前就通过BlueField-3 DPU进行控制,保证所有的数据都可以正常地在不拥堵的情况下到达接收方。”崔岩说道。
打造全球最大的Spectrum-X集群
目前,Spectrum-4 交换机、BlueField-3 DPU 和 400G LinkX 线缆/模块现已上市,可提供NVIDIA Spectrum-X 方案的公司包括戴尔科技、联想和超微。
基于最新发布的Spectrum-X平台,NVIDIA构建了生成式AI云超级计算机 —— Israel-1, 实现基于Spectrum-X网络平台的生成式AI云。在其中投入了256 台基于NVIDIA HGX平台的Dell服务器,共包括2048个GPU,并且,配备了2560个BlueField-3 DPU、80 多台 Spectrum-4 以太网交换机。
据介绍,Israel-1 Spectrum-X生成式AI云将是全球性能排名靠前的AI超级计算机之一,峰值 AI训练性能可达8 EFlop/s (8000PFlop/s)。根据已公开信息,业界尚无厂商进行这样规模的投资。
宋庆春指出,数据中心的网络已经成为一个非常重要的计算单元,其中既包括计算能力,也包括通信能力,更重要的是,如何让计算和通信更好地得到融合 —— 这是NVIDIA始终强调端到端优化的原因。并且,NVIDIA在努力推动网络计算技术的发展,将整个AI工作负载的各个组件重新洗牌,重新定义各项工作应该在GPU、交换机还是DPU来运行;通过重新定位每项工作,将其放在合适的位置、创建全新的计算平台,才能让未来算力平台达到最高效、能耗最低。
他强调,在推动Spectrum-X时,NVIDIA身先士卒,打造了Israel-1 生成式AI云。这会是全球最大的基于Spectrum-X的集群之一,且是全球最大的基于以太网的AI云集群之一。NVIDIA相当于打造了一个超大的参考模型来进行新技术验证,通过运行生成式AI或者其它工作负载,将持续优化云端采用Spectrum-X的网络平台,并将经验分享给NVIDIA的Spectrum-X用户,希望用户能看到和用到这些创新的潜能,真正满足未来大规模计算的性能需求。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1553597.html

 下载ECAD模型
下载ECAD模型


