

 1.3万
1.3万
2024 年中国本土 AI 芯片品牌渗透率已提升至 30%,但高端市场仍由英伟达主导。随着某西方国家自2024年加强对华高端 GPU 出口限制,为国产替代创造了窗口期。
过去五年,中国 GPU 产业呈现快速增长态势,市场规模从 2020 年的 384.77 亿元快速增长到 2024 年的 1,638.17 亿元。未来,随着 AI 的应用不断开发,对于 GPU 等算力基础设施的需求预计将会出现爆发增长。根据弗若斯特沙利文预测,预计到 2029 年中国GPU市场规模将增长到 13,635.78亿元。
2025年6月,国产GPU龙头厂商摩尔线程披露了招股书,作为GPU的国产之光引起了广泛关注和讨论,标志着国产 GPU 企业进入资本加速期。今天,我们来对公司发展历程、股东和高管背景、主营产品,以及在性能和英伟达、AMD等产品的主要对比情况展开讨论,以便大家了解国产GPU发展现状。
一、公司介绍
1.1、发展历程
摩尔线程2020 年成立,采用 Fabless 经营模式,以自主研发的全功能 GPU 为核心,致力于为 AI、数字孪生、科学计算等高性能计算领域提供计算加速平台。
2020 年 10 月,摩尔线程正式成立。
2022 年 3 月,发布全新 MUSA 统一系统架构,推出第一代全功能 GPU 芯片“苏堤”及多款 MTT S 系列显卡、物理引擎 AlphaCore、DIGITALME数字人解决方案等。
2022 年 11 月,发布第二颗全功能GPU芯片 “春晓”,国内首款游戏显卡MTT S80、元计算一体机 MCCX、系列 GPU 软件栈与应用工具、AIGC 创作平台 “摩笔马良” 等。
2023 年 5 月,推出 DirectX 11 驱动、整机 “智娱摩方”、MCCX VDI 云桌面一体机,发布 MUSA Toolkit 1.0 软件工具包及代码移植工具 MUSIFY 等。
2023 年 9 月,发布新一代全功能 GPU 芯片 “曲院”,推出大模型智算加速卡 MTT S4000 和 KUAE 夸娥千卡计算集群、算力管理平台 MCCPlatform等。
2023 年 12 月,首个全国产千卡千亿模型训练平台——KUAE 夸娥智算中心揭幕,宣告国内首个以全功能 GPU 为底座的大规模算力集群正式落地。
2024 年 7 月,重磅宣布其 AI 旗舰产品夸娥 (KUAE) 智算集群解决方案实现重大升级,从当前的千卡级别大幅扩展至万卡规模。
1.2、股东结构
公司上市前股权结构显示,张建中为实际控制人持股11.06%,与南京神傲(持股 14.55%)和杭州华傲(持股 6.73%)构成一致行动人,对摩尔线程进行控制。此外,杭州京傲(持股 2.01%)、杭州众傲(持股 2.01%)也在股权结构中,其余 63.64%股份由其他股东持有。
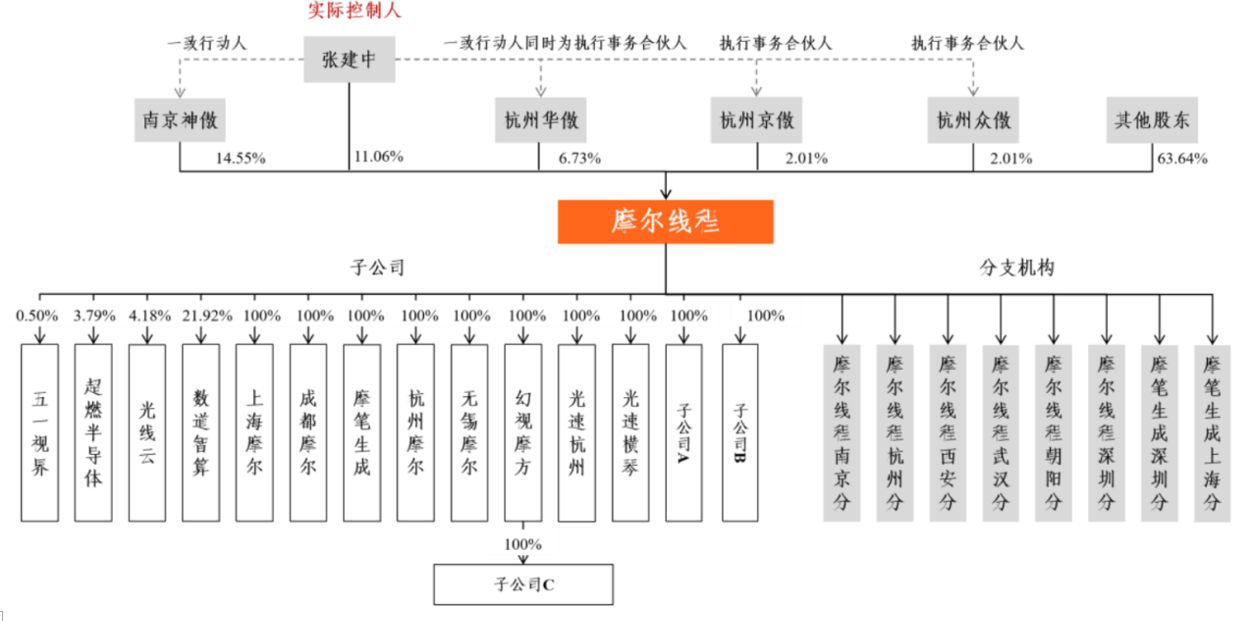
图|公司主要股东及子公司
来源:公司招股书
1.3、高管团队
摩尔线程高管团队专业背景深厚、行业经验丰富。创始人张建中曾任冶金自动化研究设计院高级研究员,后在戴尔、英伟达担任要职;联合创始人张钰勃先后在英伟达任 GPU 架构师、在 Pony AI 任主任工程师;副总经理杨上山曾就职于上海贝尔阿尔卡特、爱立信、英伟达GPU 架构师;芯片研发部总经理马凤翔有中星微电子、地平线工作履历;云计算与人工智能事业部总经理王华曾任职于威睿、华为、深信服,他们共同为摩尔线程发展助力。
1.4、主要产品
公司主要产品包括:AI 智算产品、专业图形加速产品、桌面级图形产品以及智能 SoC 类产品。2020年以来,公司已成功推出四代 GPU 架构,并拓展出覆盖 AI 智算、云计算和个人智算等应用领域的计算加速产品矩阵。
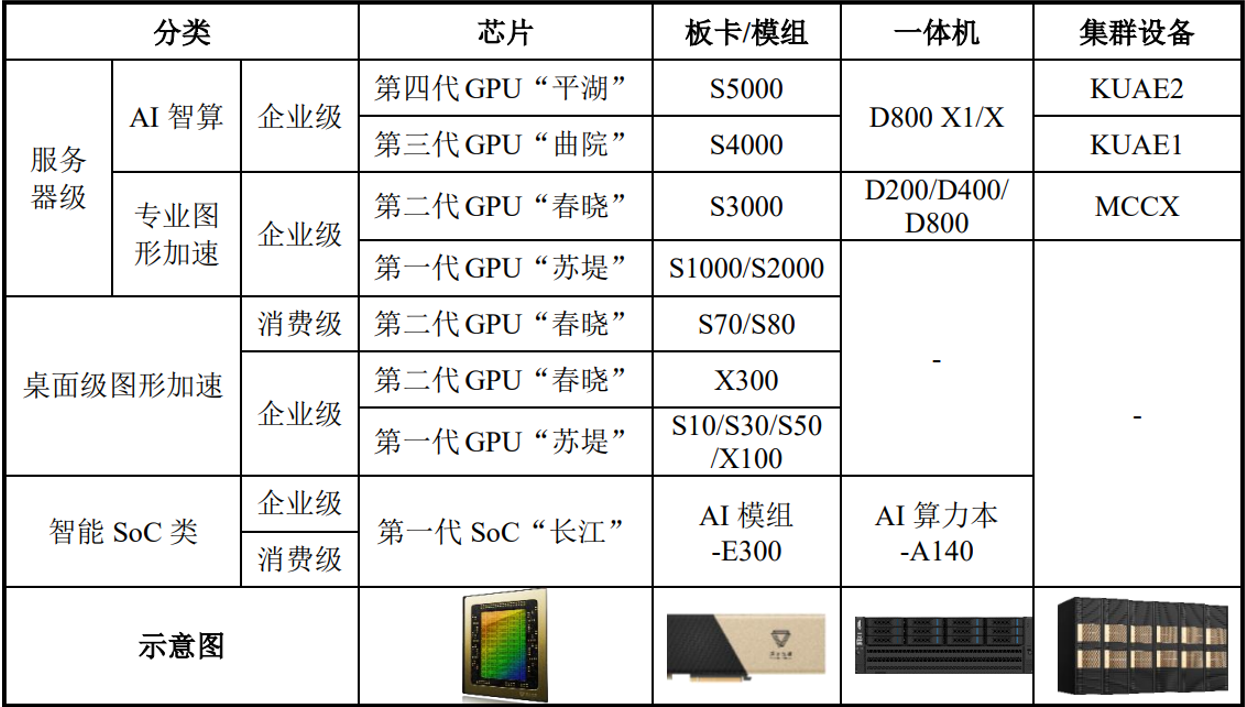
图|摩尔线程主要产品
来源:公司招股书
1.4.1、AI 智算产品
公司AI 智算产品线涵盖 AI 训练智算卡、AI 推理卡、AI 超节点服务器及夸娥(KUAE)智算集群等,为 AI 计算中心、云服务平台等打造,满足从大模型预训练及后训练、推理部署到 GPU 云服务等场景应用需求。
基于自主研发的 MUSA 架构,公司目前已推出四代 GPU 架构芯片。
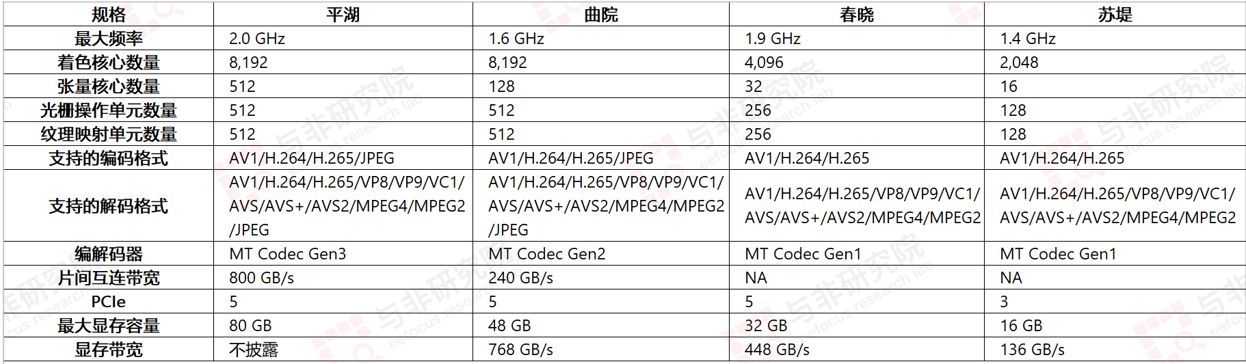
图|摩尔线程主要产品
来源:与非研究院整理
夸娥(KUAE)是以全功能 GPU 为硬件核心,软硬一体化、完整的系统级算力解决方案,旨在为大规模 GPU 算力的建设和运营管理提供系统级支持。该系统主要包括以下组成部分:以 GPU 计算集群为核心的基础设施、夸娥集群管理平台(KUAE Platform)以及夸娥大模型平台(KUAE ModelStudio)等。
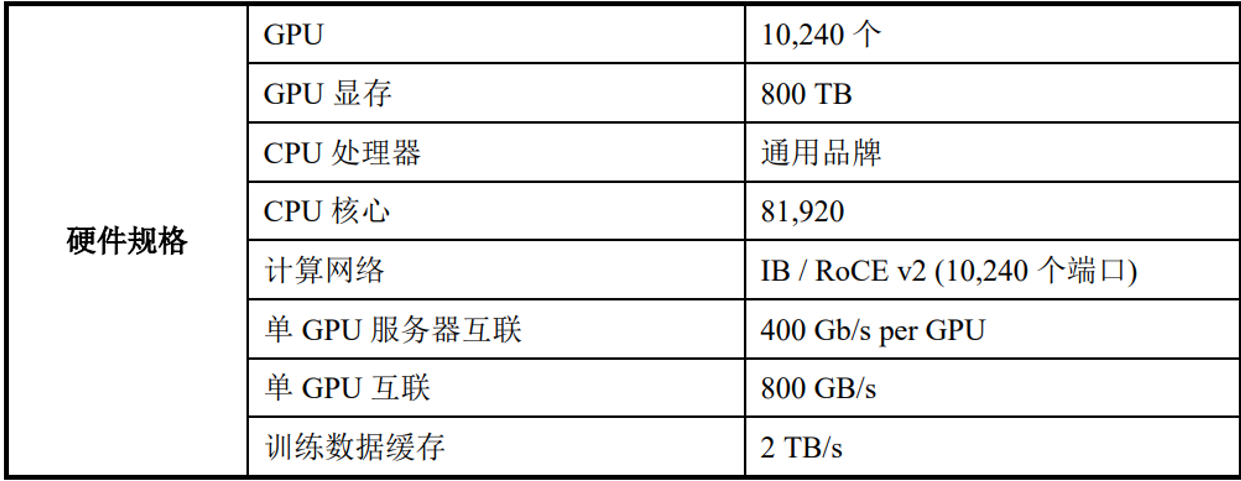
图|主要产品规格
来源:公司招股书
1.4.2、专业图形加速产品
主要应用于工业设计、高清视频编辑、数字孪生、AI 云电脑等高端场景的GPU及相关产品系列,涵盖 MTT S3000/S2000/S1000 等系列显卡,以及基于前述显卡打造的一体机等解决方案。
1.4.3、桌面级图形加速产品
主要应用于AI PC、游戏PC及办公PC等场景的GPU及相关产品,包括 MTT S80/S70/S50/S30/S10/X300/X100 等系列显卡,以及基于前述显卡打造的工作站等。该类产品支持Windows、麒麟KylinOS、统信UOS、openEuler等多款国内外主流操作系统,以及 Intel、AMD、海光、飞腾、鲲鹏等多款国内外主流CPU平台。
GPU 板卡通常由 GPU 芯片、显存、显卡板、散热器和输出端口等组件构成, 其核心部件即为 GPU 芯片。
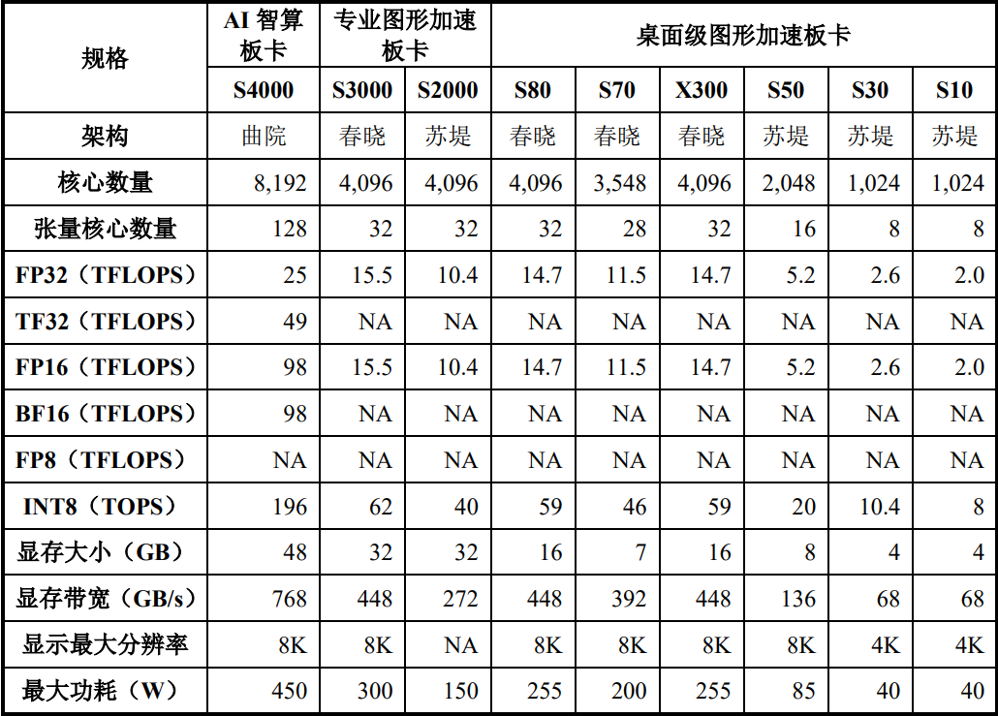
图|部分产品性能
来源:公司招股书
1.4.4、智能SoC类产品
主要应用于 AI PC、边缘智能、具身智能、智能汽车和低空经济等众多场景,包括基于SoC 芯片的 AI 算力本-A140、AI 模组-E300 等产品。该类产品可以广泛服务于C端和B端客户,满足上述行业对于端侧和边缘类 AI 场景的需求,同时可与公司的 AI 智算产品结合,形成云–边–端一体化解决方案,赋能客户实现AI的训练-推理需求。公司智能 SoC 芯片“长江”,是集成了“全功能 GPU + CPU + NPU + VPU”等异构算力单元的片上系统芯片。
二、与国际同行对比
2.1、架构对比
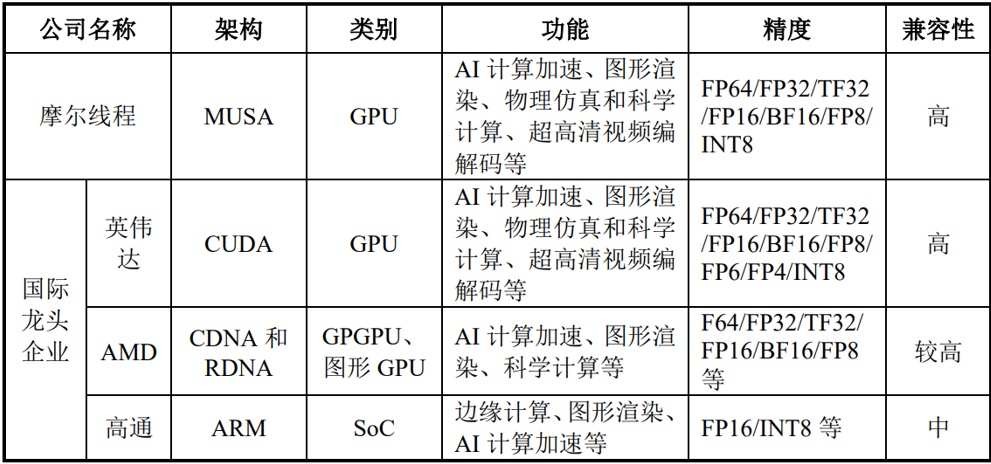
图|摩尔线程与同行对比
来源:公司招股书
摩尔线程:采用 MUSA 架构,是其自主研发的特色架构,在国内 GPU 领域积极探索创新架构设计。英伟达:CUDA 架构成熟且应用广泛,是 GPU 通用计算领域的主流架构之一,生态丰富,有大量基于此架构开发的软件和工具。AMD:拥有 CDNA 和 RDNA 架构,CDNA 面向高性能计算和 AI 领域,RDNA 专注图形处理,双架构策略满足不同应用场景需求。高通:基于 ARM 架构打造 SoC,ARM 架构以低功耗、高性能在移动及边缘计算领域占据重要地位。
2.1.1、 类别对比
摩尔线程、英伟达、AMD 产品均涉及GPU 类别,专注于图形处理、计算加速等领域。其中 AMD 还细分出 GPGPU(通用计算 GPU)和图形 GPU,功能定位更细化。高通的 SoC(片上系统)集成了多种功能模块,不仅有图形处理、AI 计算加速等能力,还涵盖了通信等其他功能,是高度集成化的芯片解决方案。
2.1.2、功能对比
都具备 AI 计算加速和图形渲染功能,顺应了当前 AI 和图形密集型应用(如游戏、虚拟 / 增强现实)的发展需求。
摩尔线程和英伟达功能更为全面,还强调物理仿真、科学计算、超高清视频编解码等功能;AMD 突出科学计算;高通聚焦边缘计算,符合其在移动和物联网边缘设备应用的定位。
2.1.3. 精度对比
摩尔线程和英伟达支持的精度类型最为丰富,涵盖 FP64(双精度浮点数)、FP32(单精度浮点数)、TF32(张量浮点 32 位)、FP16(半精度浮点数)、BF16(脑浮点 16 位)、FP8(八位浮点数)、INT8(八位整数)等,能满足科学计算、深度学习等不同场景对计算精度的多样需求。
摩尔线程、AMD仅支持到FP8、INT8,相比英伟达少了FP6/FP4,英伟达精度更高。摩尔线程在 FP8 技术研发上取得系统性突破,是国内少数掌握该项技术的 GPU 厂商,在全球与英伟达保持技术同步。
高通主要支持 FP16/INT8 等,在精度支持上相对有限,不过满足其面向的边缘计算、移动设备等应用场景的一般需求。
2.1.4. 兼容性对比
摩尔线程和英伟达兼容性为 “高”,意味着它们在与各类软件、硬件系统协同工作方面表现出色,能适配众多现有开发环境和平台,利于推广应用。
AMD 兼容性 “较高”,在大部分主流场景下能良好适配,但相比前两者可能在部分小众或特定场景存在兼容性差异。
高通兼容性为 “中” ,由于其产品特性及应用领域相对聚焦,在跨领域、跨平台的兼容性上相对受限。
2.2、图形渲染层面
在高性能 GPU 图形计算领域,摩尔线程依托自主研发的新一代统一图形计算架,成功突破多项关键核心技术。
在微架构层面,公司设计了自主可控的高效能通用计算单元、新型缓存层次结构及优化的内存子系统,实现了 14.7 TFLOPS 的单精度浮点性能,处理器规格达到与英伟达 RTX 3060 同等水平。

图|图形渲染产品对比
来源:公司招股书
2.3、智能 SoC 层面
摩尔线程自主研发的新一代片上智能计算系统(智能 SoC),通过创新性地在单芯片上融合 CPU、GPU、NPU、VPU(视频)、DPU(显示)等多异构计算核心,实现了性能与功耗的双重突破。
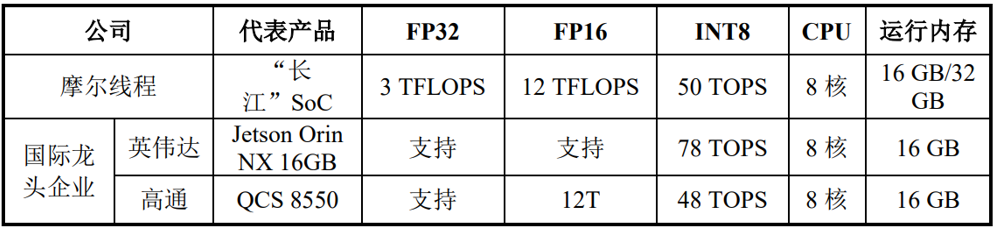
三、财务分析
3.1、营收和利润分析
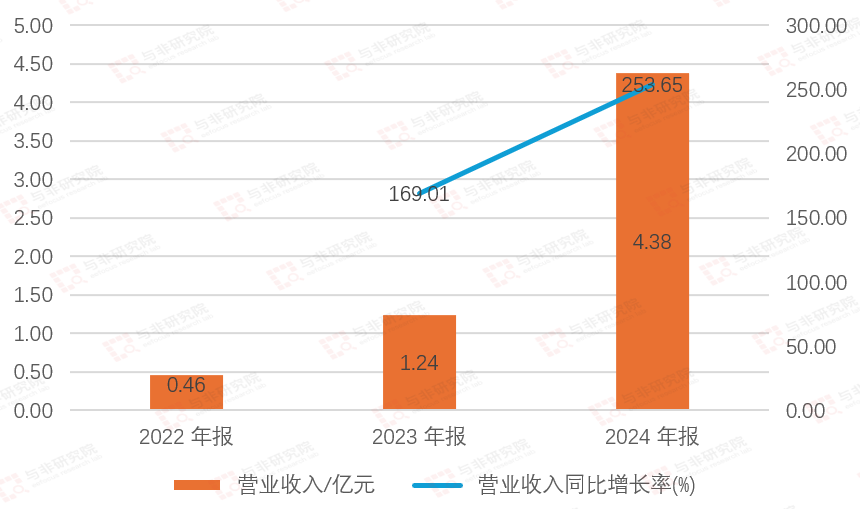
图|营收及增长率
来源:与非研究院整理
公司成立2年后贡献营收,由2022年0.46亿元增长至4.38亿元,2023、2024年分别增长169.01%、253.65%。
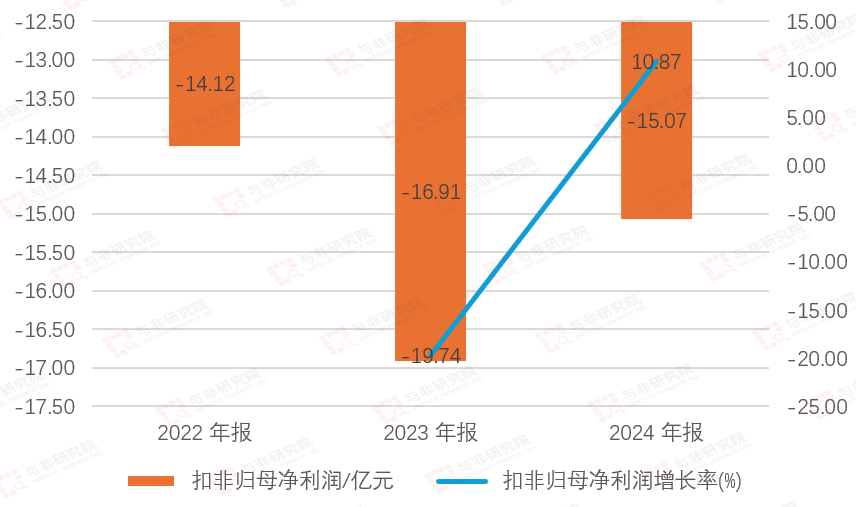
图|扣非归母及增长率
来源:与非研究院整理
扣非净利润2022-2023年分别为-14.12亿元、-16.91亿元、-15.07亿元,2023-2024年增速分别为-19.74%、10.87%。
3.2、毛利率、净利率分析
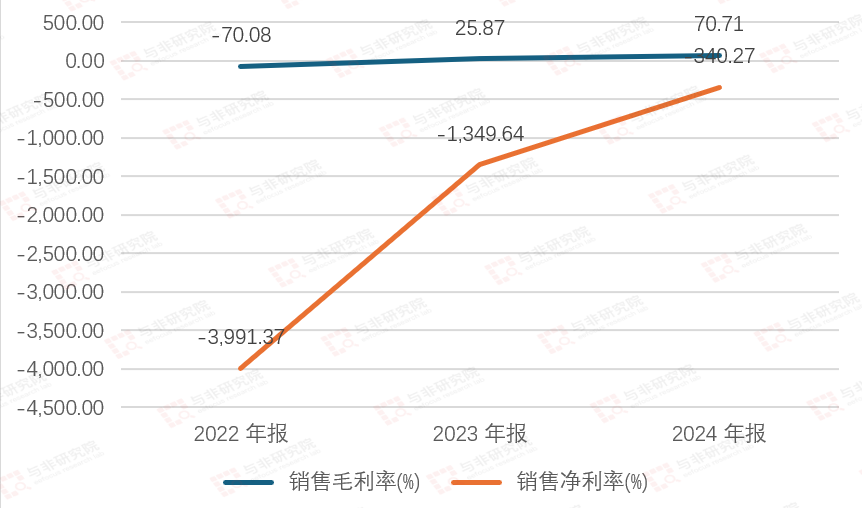
图|毛利率/净利率
来源:与非研究院整理
2022-2024年毛利率分别为-70.08%、25.87%、70.71%,净利率分别为-399.37%、-1349.64%、-340.27%。
3.3、营收结构
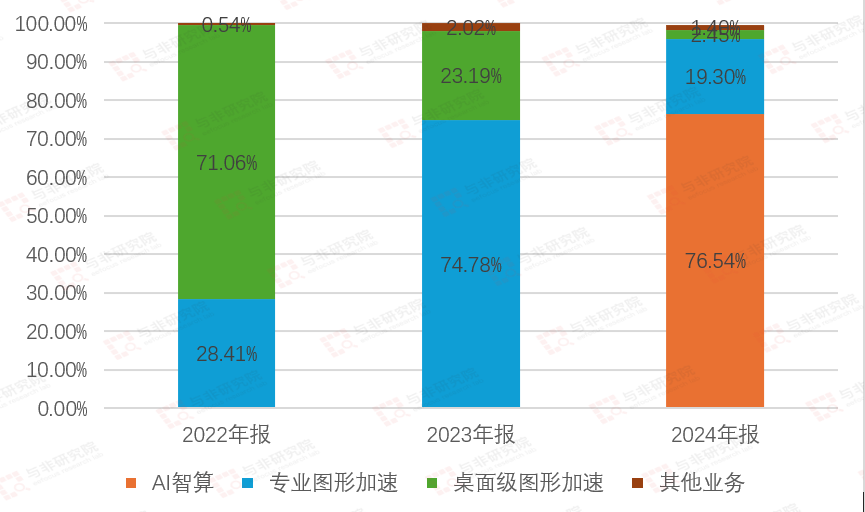
图|营收结构
来源:与非研究院整理
2022年桌面级图形加速占营收71.06%,专业图形加速占比28.41%,其他业务占比0.54%;2023年桌面级图形加速占23.19%,专业图形加速提升至74.78%,其他业务占比2.02%;2024年AI智算开始贡献收入占比76.54%,专业图形加速占比19.30%,桌面级图形加速占比2.45%,其他业务占比1.49%。
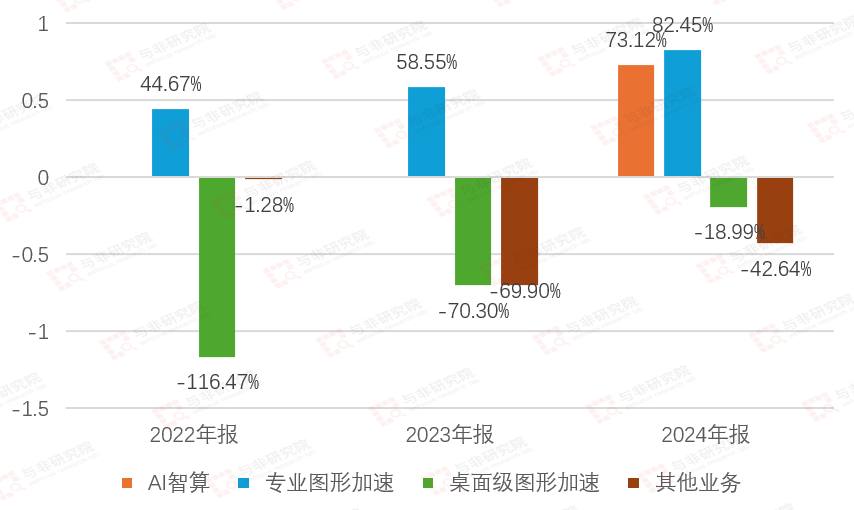
图|分产品毛利率
来源:与非研究院整理
2022-2024年,专业图形加速在毛利率为正,且持续提升,分别为44.67%、58.55%、82.45%;桌面级图形加速毛利率还为负值,但是持续收窄,分别为-116.47%、-70.30%、-18.99%;2024年AI智算贡献收入,毛利率为73.12%;其他业务占比较少,毛利还为负值。
桌面级图形加速产品主要为芯片、板卡产品,毛利率较低,主要由于中低端市场面临国际品牌的激烈竞争,面对国际知名公司的成熟产品,公司芯片、板卡 产品销售价格存在一定压力。随着产品不断发展,公司逐步拓展专业图形加速、 AI 智算等高性能、高毛利领域产品,毛利率逐渐上升。
3.4、研发投入分析
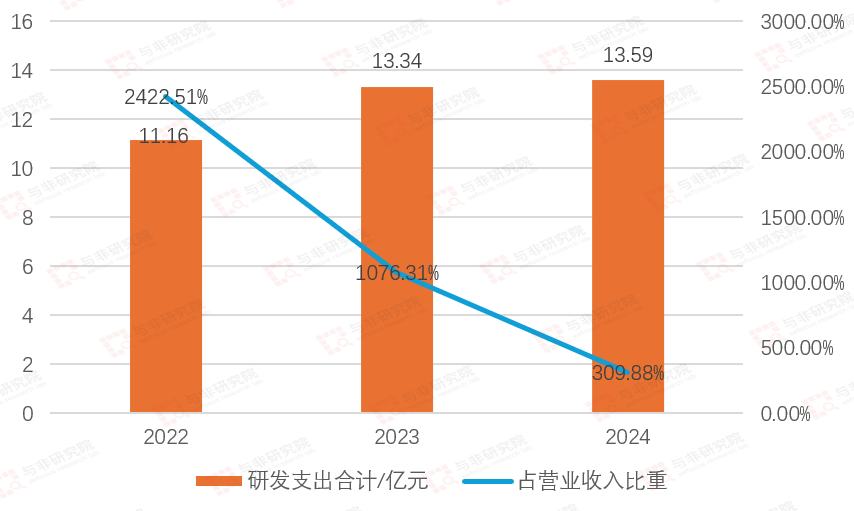
图|研发投入及营收占比
来源:与非研究院整理
2022-2024年,研发投入分别为11.16亿元、13.34亿元、13.59亿元,研发占营收比例分别为2422.51%、1076.31%、309.88%。公司成立初期研发投入较大,营收较小,造成营收占比失衡。随着营收进一步增加,营收占比会趋于正常。
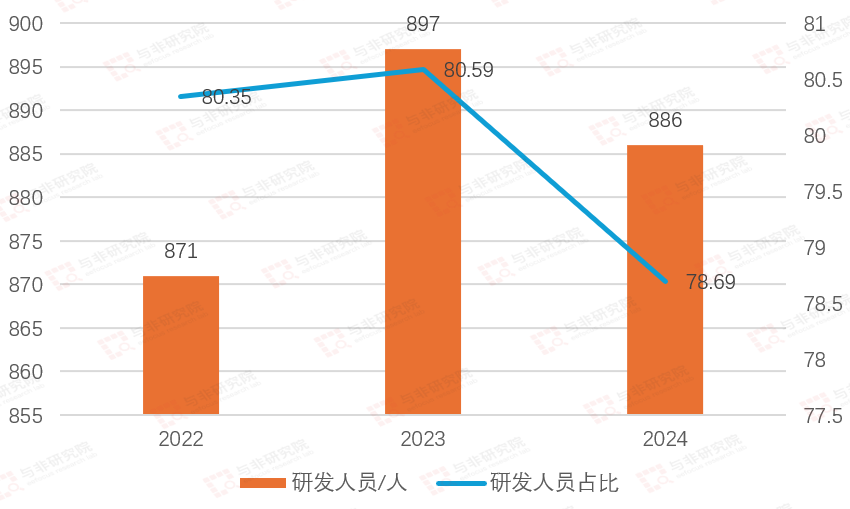
图|研发人员数量及占比
来源:与非研究院整理
2022-2024年研发人员数量变化不大,分别为871人、897人、886人;研发人员数量占比分别为80.35%、80.59%、78.69%,占比较高。
公司主要研发方向涵盖从第二代到第六代全功能 GPU 芯片,包括春晓、曲院、平湖、平湖 1S、华山芯片,还有高性能 SoC 长江芯片。应用方向涉及主流游戏、虚拟化(VDI),以及 AIPC、智能座舱、机器人等智能设备,还有AI大模型训练推理,适配 CUDA 生态等
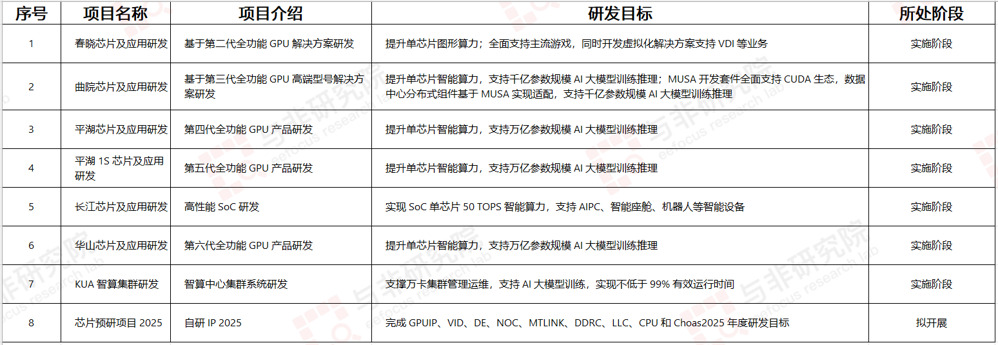
图|公司在研项目
来源:与非研究院整理
四、总结
摩尔线程成立仅5年,全面对标英伟达产品和技术路线,研发上持续提升单芯片图形算力和智能算力,从千卡集群到万卡集群,以及生态建设,实现了跨越式发展。在 GPU 技术迭代上,从第二代全功能 GPU出发,到着手第六代全功能 GPU 研发,迭代不断加快。
同时,我们也能看到摩尔线程和英伟达相比,还存在计算精度、KUDA生态上的一些差距,随着国产需求的大规模提升,公司产品会迎来更加快速的迭代和升级,支持国产GPU行业不断前行。
来源: 与非网,作者: 王兵,原文链接: https://www.eefocus.com/article/1860094.html








