

 1073
1073
Gemini 3是Google DeepMind迄今为止在AI架构层面最具颠覆性的产品,其核心突破在于将MoE(混合专家)稀疏架构与“思维签名”机制深度融合,实现了从“概率性文本生成”到“可验证深度推理”的代际跨越。
对于国内开发者和技术研究者,聚合平台RskAi(ai.rsk.cn) 提供了Gemini 3系列模型的国内直访入口,可免费体验其思考模式与多模态能力,实测复杂推理任务的首字延迟控制在2-3秒以内。
一、MoE架构演进:从稠密到稀疏的算力革命
Gemini系列架构演进的底层逻辑,是Jeff Dean在斯坦福演讲中反复强调的理念——让AI像大脑一样工作,每次推理仅激活所需的部分网络。
1. 从Gemini 1.0到3.0的架构跃迁
Gemini 1.0采用稠密Transformer架构,总参数量虽大,但每次推理需激活全部参数,计算效率较低。Gemini 1.5首次引入MoE架构,用“专家网络”替代标准FFN层,实现了参数容量与计算成本的解耦。
MoE的核心公式可以表达为:对于输入token x,输出y是k个激活专家输出的加权和。其中Ei(x)是第i个专家的非线性变换,gi(x)是路由权重,仅对选中的top-k专家非零。
Gemini 3在此基础上升级了动态路由机制,通过强化学习优化门控网络,使专家分配更精准。Jeff Dean在演讲中展示的数据显示:用同样的计算预算,MoE架构可以训练出效果提升8倍的模型。这意味着Gemini 3在保持响应速度的前提下,有效参数量远超同类产品。
2. 上下文窗口的指数级扩展
Gemini 1.5首次将生产环境上下文窗口扩展至100万token,实验环境达到1000万token。在“大海捞针”测试中,Gemini 1.5在100万token长度下取得了99%的召回率。
Gemini 3延续了这一优势,Pro版本支持100万token输入、6.4万token输出。这意味着开发者可以一次性上传整个代码库(约10万行代码)或3小时长视频,模型仍能保持对开头信息的完整召回。这对遗留代码分析和视频内容理解场景是质的飞跃。
二、原生多模态:从“看图”到“理解空间”
Gemini与同类产品的本质区别在于“原生多模态”设计理念——从一开始就统一训练图像、音频、视频和文本数据,而非后期拼接。
1. 早期融合架构
Gemini的技术报告明确指出,模型在图像像素块、视频时序帧、音频波形图和文本token层面进行联合嵌入,投影到统一的潜在空间。这种“早期融合”使模型能在每一层注意力机制中自然实现跨模态信息整合,而非依赖外挂的视觉编码器。
音频处理方面,Gemini直接从原始波形中提取特征,保留了语调、音色和背景噪声等声学细节——这是Speech-to-Text转录系统会丢失的关键信息。
2. 像素级空间定位能力
Gemini 3 Pro在视觉理解上的核心突破是像素级空间定位。模型可以输出物体在图像中的精确边界框坐标([y_min, x_min, y_max, x_max]),这一能力直接打通了“看到”与“操作”之间的桥梁。
在UI自动化测试场景中,开发者只需上传界面截图,Gemini 3即可返回“提交按钮”的精确坐标供脚本点击,无需解析DOM树。在机器人操控场景中,模型可以输出“按用户手册中的图示,拧紧螺丝A”的像素坐标序列,指导机械臂执行。
3. Agentic Vision:主动操作图像
2026年1月,Google DeepMind为Gemini 3 Flash推出了Agentic Vision能力——模型不再被动接收像素,而是主动编写Python代码来操作图像。
这一能力引入“思考-行动-观察”闭环:模型先分析用户查询和初始图像,制定多步计划;然后生成并执行Python代码来裁剪、旋转、标注图像或运行计算;变换后的图像被追加到上下文窗口,供模型在生成最终答案前再次检查。
实测效果令人印象深刻:在处理微处理芯片上的序列号或远处模糊路牌时,传统模型只能“猜”,而Gemini 3 Flash会主动放大局部区域,精准读取细节。这一能力使模型在各类视觉基准测试中实现了5%到10%的性能跨越。
三、思维签名与推理机制:让AI的思考可验证
如果说MoE和多模态是Gemini的“肌肉”,那么思维签名机制就是它的“神经系统”——确保每一步推理都逻辑严密、可追溯。
1. 思维签名:消除长链推理幻觉
传统的思维链(Chain of Thought)在长文本生成中容易出现逻辑漂移——模型在第50步推理时可能偏离第1步的假设。Gemini 3 Pro引入了思维签名机制:在推理的每一个关键节点生成加密的Hash签名,类似区块链的校验机制,确保长链推理的逻辑一致性。
对于开发者而言,思维签名带来了两个实际好处:一是复杂代码Debug场景下的幻觉率降低约40%;二是API可以返回思维摘要,让开发者理解模型“为什么这样决策”,而不仅是“决策是什么”。
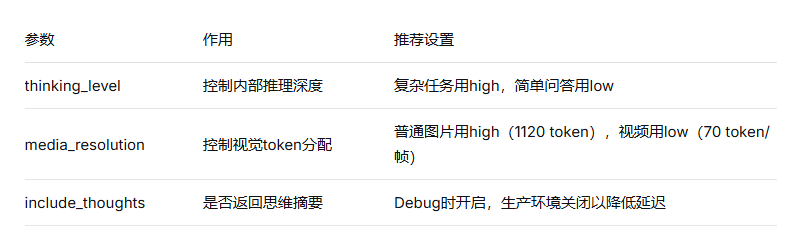
2. 可控的思考强度
Gemini 3 Pro通过thinking_level参数让开发者动态调节模型的“脑力”投入:
Low:适用于即时翻译、简单问答,延迟控制在500毫秒以内
Medium:适用于常规任务,平衡速度与质量
High:适用于数学证明、法律合同审查等复杂任务,包含多次自我反思与纠错,延迟可达10-30秒
这种设计使开发者可以在“响应速度”和“答案质量”之间灵活取舍,而非被动接受模型的默认行为。
3. Deep Think模式:并行推理架构
在thinking_level的基础上,Gemini 3 Pro还提供了Deep Think实验性增强模式。与传统的线性推理不同,Deep Think激活并行推理通路,同时探索多个假设路径,最后通过合成模块评估一致性并选择最优输出。
在ARC-AGI-2抽象推理测试中,Deep Think模式得分45.1%,比单线程模型快25%。在国际数学奥林匹克资格赛中,模型在时间约束下解决了8/10道题,达到金牌等效水平。
四、智能体能力:从回答问题到完成工作
Gemini 3最值得关注的转变,是从“回答问题”升级为“完成工作”。
1. Agentic架构
Gemini 2.0被Google定位为“智能体时代”的首个模型,Gemini 3则进一步完善了原生工具调用能力。模型可以主动调用Google搜索、Google Maps、代码执行环境、URL上下文获取等工具,形成完整的“感知-规划-行动-反思”循环。
Jeff Dean在斯坦福演示了一个真实案例:用户上传一堆家族食谱照片(有韩语手写、有英语、有折痕油渍),只说了一句“帮我做一个双语食谱网站”。Gemini 3自动完成了:扫描识别所有照片中的文字、翻译成双语版本、自动生成网站布局、为每个食谱配图。整个过程用户无需指导任何中间步骤。
2. 强化学习的突破
这种智能体能力背后的技术支撑是在可验证领域的强化学习。以编程为例:模型生成代码后,系统自动检查能否编译;如果能编译,进一步检查能否通过单元测试;每通过一层验证,就给模型正向奖励。数学推理同理:模型生成证明后,系统用证明检查器验证,正确就奖励,错误就指出具体步骤。
这一训练方法使Gemini在2025年国际数学奥林匹克竞赛中解决了六道题中的五道,获得金牌。要知道,三年前(2022年)最先进的AI模型在GSM8K小学算术题上的准确率只有15%。从小学算术到IMO金牌,这种跨越正是强化学习与智能体架构共同作用的结果。
五、开发者实战:API关键参数与调用示例
对于技术研究者而言,Gemini 3的核心价值在于其API提供的精细化控制能力。
关键配置参数
总结与建议
Gemini 3的技术拆解揭示了一个核心趋势:AI竞争正从“参数规模竞赛”转向“推理效率与工具调用能力”的较量。
MoE架构让模型在万亿参数规模下保持毫秒级响应;原生多模态与像素级定位打通了AI与物理世界的交互接口;思维签名机制解决了长链推理的幻觉问题;智能体能力将AI从“对话工具”升级为“任务执行系统”。
对于国内的技术研究者和开发者,深度体验这些前沿能力的最便捷途径是聚合平台。RskAi集成了Gemini 3系列模型,提供国内直访的免费入口,支持文件上传与联网搜索功能。无论是进行模型能力对比、技术验证,还是日常开发辅助,这类平台都能显著降低技术探索的门槛。
理解Gemini 3的架构本质,有助于更理性地选择和使用AI工具——它不再是一个“更聪明的聊天机器人”,而是一套能够感知世界、规划路径、执行任务的智能体基础设施。随着思考模式、Agentic Vision等能力的持续演进,这一架构将继续拓展AI应用的边界。



