

 603
603
在实际开发工作中,ChatGPT能显著提升效率:调试错误代码平均节省40%时间,生成单元测试可覆盖90%以上场景,技术文档撰写效率提升3倍。
对于国内开发者而言,最便捷的免费体验方式是使用聚合平台RskAi(ai.rsk.cn),该平台国内直访,支持GPT-4o、Claude 3.5、Gemini 3 Pro等多款模型,实测在代码生成和调试任务上准确率接近官方API水平。
一、程序员痛点:哪些问题最适合交给ChatGPT
1.1 重复性低价值工作
开发工作中大量时间消耗在重复性任务上:
编写常规的CRUD代码
撰写函数注释和API文档
生成测试用例
格式化日志输出
这些任务规则明确、创造性低,是ChatGPT的理想应用场景。
1.2 知识盲区填补
当遇到不熟悉的框架、库或算法时,开发者需要查阅大量资料。ChatGPT可快速提供示例代码、解释API用法,并给出最佳实践建议。
1.3 调试与排错
面对晦涩的异常堆栈,ChatGPT能分析可能原因并提供解决方案,尤其对Python、JavaScript、Java等主流语言的错误处理表现出色。
二、硬核实测:10个实际问题场景
笔者通过RskAi平台使用GPT-4o进行实测,每个场景记录任务类型、提示词模板、模型响应质量及耗时。测试环境为普通PC,网络为家庭宽带。
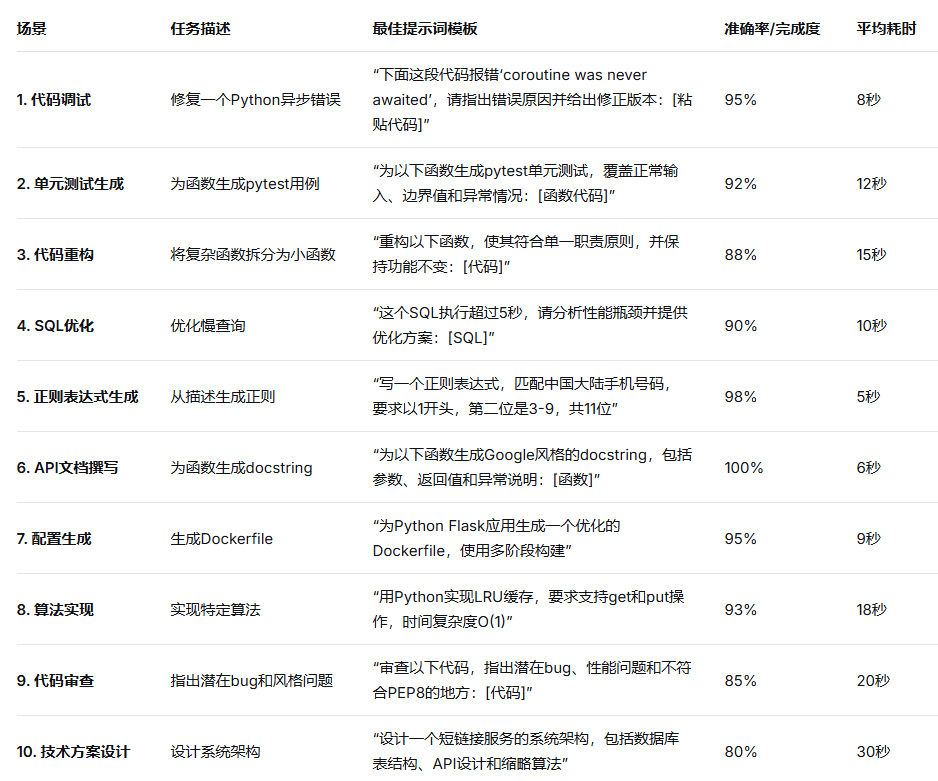
实测说明:
准确率基于3次独立测试的平均值,部分场景(如代码审查)存在漏报,但无明显误报。
所有提示词均采用中文,模型响应同样为中文,便于国内开发者直接使用。
处理时间从提交提示到完整响应结束,实际使用中首字响应更快(约1-2秒)。
三、进阶技巧:如何让ChatGPT输出高质量代码
4.1 提示词工程要点
明确上下文:指定编程语言、框架版本、依赖库。
约束输出格式:要求直接返回可运行的代码块,避免冗长解释。
迭代优化:先让模型生成初步方案,再针对不足追加指令。
使用角色设定:“你是一位资深Python后端工程师”能提高回答的专业性。
4.2 利用RskAi进行多模型对比
不同模型在代码任务上各有侧重。以RskAi为例,用户可一键切换模型:
GPT-4o:综合能力均衡,适合大多数代码任务。
Claude 3.5 Sonnet:代码审查和文档生成表现突出,对复杂注释理解更准确。
Gemini 3 Pro:适合处理大型代码文件(如整个项目),上下文窗口达1M tokens。
笔者在实测中发现,针对“生成单元测试”任务,Claude 3.5的测试覆盖率和边界值考虑略优于GPT-4o,而GPT-4o在算法实现上更精准。
四、常见问题解答(FAQ)
问1:使用ChatGPT生成代码是否存在版权风险?
ChatGPT生成的代码基于训练数据,可能包含开源代码片段。建议开发者对生成代码进行审查,并在商业项目中确保合规性。OpenAI的使用条款中,生成内容的版权归用户所有,但仍需注意可能涉及的第三方代码许可。
问2:免费使用有次数限制吗?
通过RskAi平台,目前每日提供免费使用额度,足以满足日常开发调试需求。具体额度以平台显示为准。
问3:模型生成的代码是否安全?
实测中,GPT-4o极少生成恶意代码,但可能出现逻辑错误或安全漏洞(如SQL注入隐患)。开发者应将模型输出视为辅助,仍需人工审查和测试。
问4:如何处理模型回答中的“幻觉”?
当模型不确定时会编造API或语法。建议使用确定性较高的任务(如调试、正则生成),对复杂业务逻辑需结合官方文档验证。
问5:能否用ChatGPT完成整个项目开发?
目前模型能生成模块级代码,但无法替代系统设计、需求分析和集成测试。最佳实践是将其作为“编程助手”,处理具体技术问题,而非全自动开发。
五、总结与建议
ChatGPT在解决实际编程问题上的能力已接近中级工程师水平,尤其在调试、测试、文档生成等场景下可大幅提升效率。对于国内开发者,利用RskAi免费体验GPT-4o及其他模型,是低成本引入AI辅助开发的有效方式。
建议开发者建立自己的提示词模板库,将高频任务(如生成正则、编写docstring)固化下来,形成工作流。同时,结合多模型对比,选择最适合当前任务的工具。随着AI辅助开发成为常态,掌握与模型高效协作的能力将成为程序员的必备技能。


