

 210
210
还在玩ChatGPT?已经有自动驾驶算法能告诉你“我在干嘛”。
基于视觉和神经网络的自动驾驶算法,虽然能通过传感器数据,以及学习人类的驾驶行为,自主决策并控制车辆。
但是,算法基于什么做出的决策?特别是出现故障,也就是决策错误的时候,算法是怎么想的?这些一直被称为自动驾驶算法里的“黑匣子”,让算法缺乏透明度和可解释性。
不过,现在有这么一个模型,既能预测车辆控制行为,还能自己解释“我停车是因为红灯亮了,并且有行人在过马路”。
模型论文入选ICRA 2023,相关模型已开源。
那么,是一个什么样的算法?
ADAPT:驾驶行为感知说明大模型
这是一种叫ADAPT(Action-aware Driving Caption Transformer)的端到端算法,也是目前第一个基于Transformer的驾驶行为描述框架,可以感知和预测驾驶行为,并且输出自然语言叙述和推理。

直白一点说,输入车辆视频后,这个算法可以判断车辆行为并告诉你:车在做什么,为什么要这么做。

在论文作者提供的测试视频里,这个算法最终上车的效果是这样的。(红色字是车辆行为,蓝色字是解释)
“车在向前开。因为路上没有车。”

驾驶行为变化后,算法也能及时感知:“车靠左边停下了。因为要停车。”

“车开始移动并且靠右行驶。因为路左边停着车。”
算法不仅能识别路口,也能识别骑着车的人。
“车在十字路口停下了。因为要避开街上骑着自行车的人,”
这是怎么实现的?
多任务框架下的联合训练
ADAPT框架可以分为两个部分:车辆行为描述(DCG,Driving Caption Generation)和车辆控制信号预测(CSP,Control Signal Prediction)。
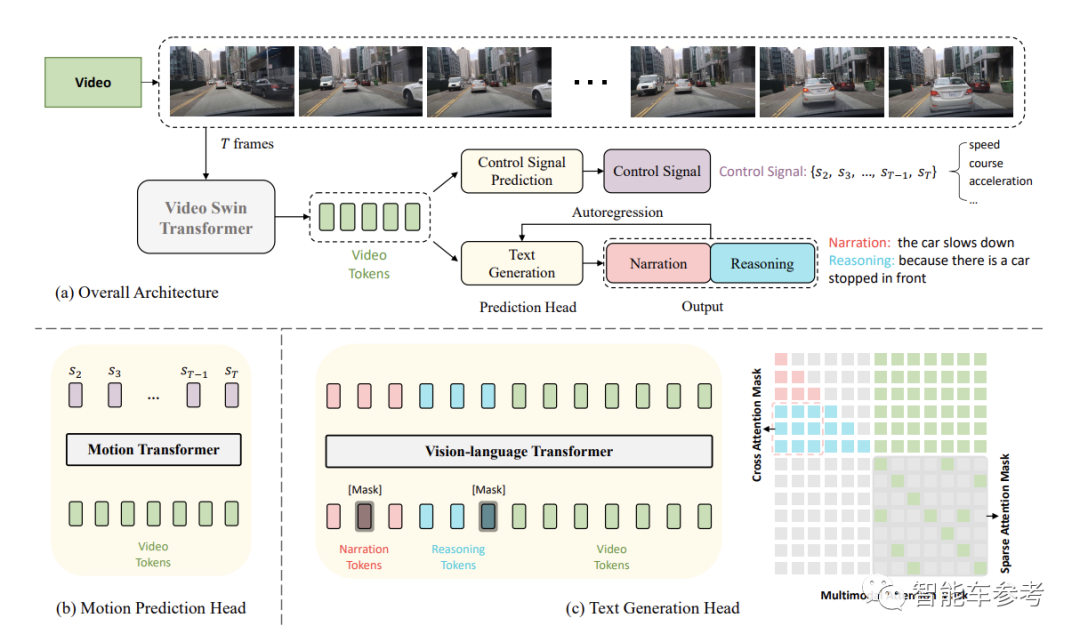
首先,传感器端输入视频,Video Swin Transformer对车辆视频进行编码,得到的视频特征会输入进各任务模块里。
在DCG模块,算法利用Vision-Language Transformer生成两个自然语句,也就是上文中提到的车辆行为描述和原因解释。
相同的视频特征也会输入进CSP模块(类似一般基于视觉的自动驾驶系统),输出车辆实际的控制信号序列,并利用Motion Transformer输出模型预测的控制信号,比如速度、方向和加速度。
在单个网络中,作者利用车辆实际的控制信号序列和模型预测的控制信号序列,两者的均方误差作为CSP模块的损失函数。
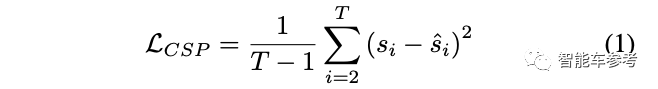
而在多任务框架下,通过联合训练DCG和CSP,可以减少车辆决策和文本描述之间的差异,提高控制信号预测的准确率。
论文里,作者们在包含控制信号和车辆视频的大规模数据集BDD-X上,利用机器评测和人工评测验证了ADAPT的有效性。
机器评测方面,使用的是BLEU4、METEOR、ROUGE-L和CIDEr(对应缩写分别为B4、M、R、C)等多种语言任务常用的指标。
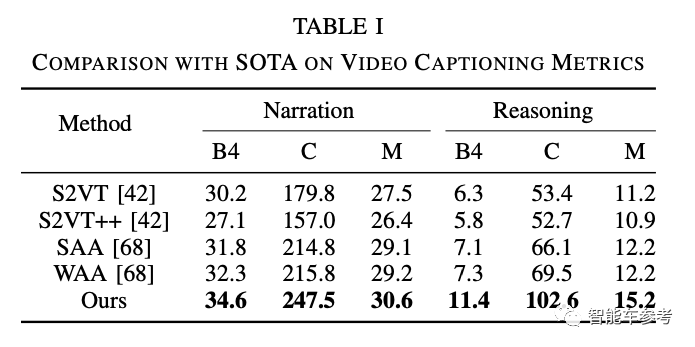
最终显示ADAPT达到了当前最优(State-of-the-Art)的结果,ADAPT在动作描述方面比原有先进方法CIDEr高出31.7,在原因解释方面高33.1。
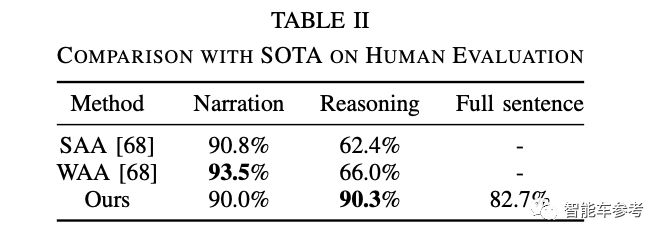
人工评测分为动作描述、原因解释和全句三个部分。通过人工判断,ADAPT在这三部分的准确性分别达到了90%,90.3%和82.7%,证明了ADAPT的有效性。

在可视化结果里,也能看出ADAPT可以准确识别车辆行为以及决策原因。并且在黑夜、阴雨天等场景下,ADAPT也能保证准确度;即使有雨刷器干扰,ADAPT也可以识别道路上的停止标识。
为什么需要ADAPT?
自动驾驶行为的可解释性
在基于视觉的自动驾驶算法里,比较常见的解释图有视觉注意图(Attention Map),或者成本量图(Cost Volume),但不熟悉自动驾驶算法的人容易对这些图造成误解。
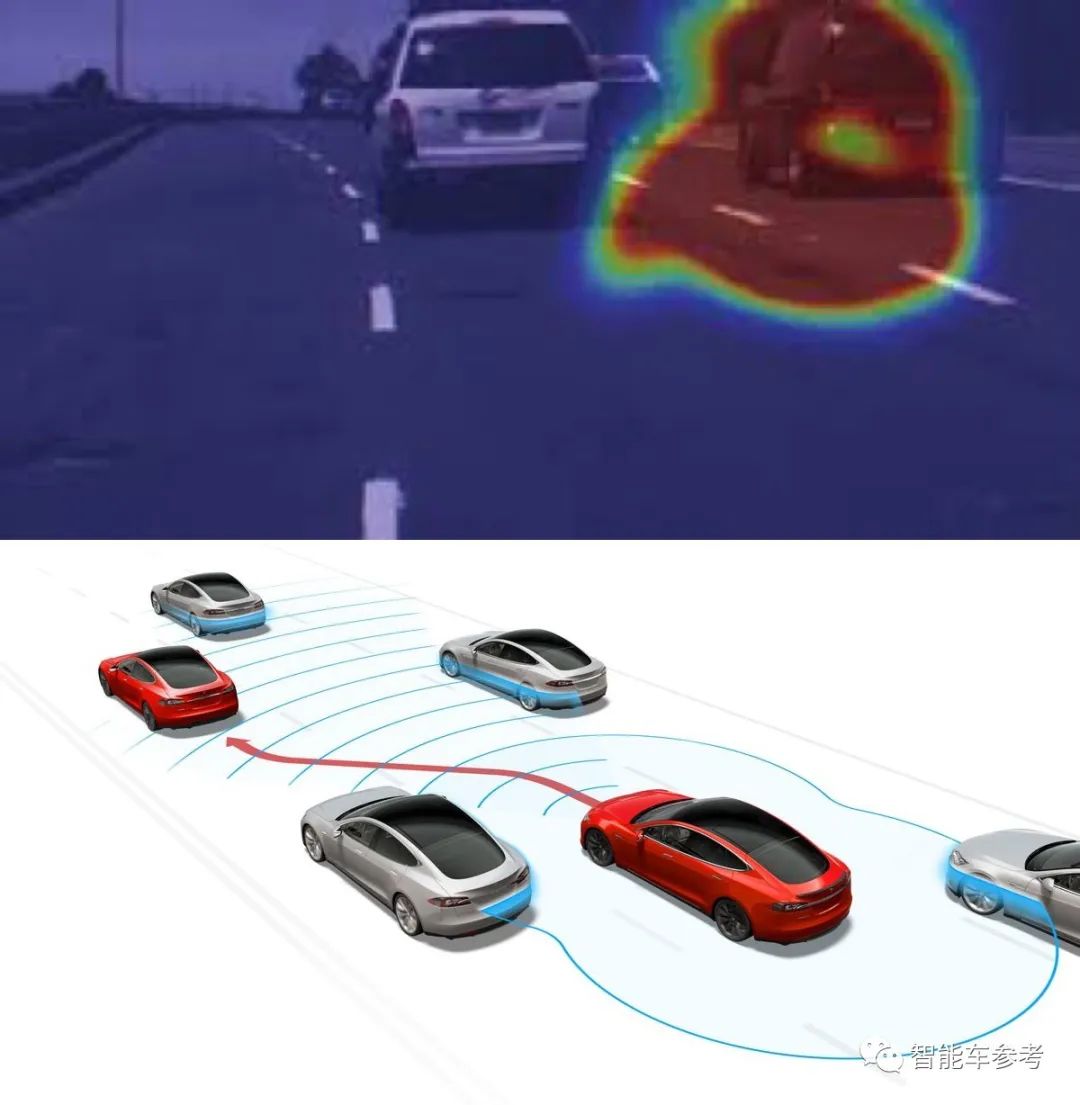
△上:视觉注意图;下:成本量图
因此,ADAPT这种能够生成自然语言、“说人话”的算法,能够帮助用户更好地理解自动驾驶算法在做什么、为什么要这么做,同时还能让用户更信任自动驾驶技术。
而对于算法工程师和研究人员来说,当发生极端情况时、或者发生故障(比如判断错误)时,ADAPT可以帮助他们获得更多信息,进而改进算法。
作者们将进一步研究如何在模拟器和实际车辆上如何部署ADAPT,以及如何利用文本转语音技术,让生成的句子转化为语音,帮助普通乘客,特别是视力障碍乘客使用。
本文作者来自中国科学院自动化研究所、清华大学人工智能产业研究院(AIR)、北京大学、英特尔中国研究院、西安电子科技大学、南方科技大学和北京航空航天大学。

论文一作晋步和三作郑宇鹏是来自中国科学院自动化研究所的研究生,晋步主要研究方向为多模态学习、视觉语言模型等。
通讯作者为刘新宇,清华大学自动化系学士和硕士,长期从事软件研发工作,著有《算法新解》。
作者之一李鹏飞是AIR在读博士生,本科毕业于中国科学院大学,主要研究智慧交通、机器人、计算机视觉等方向。
另一位作者赵昊是AIR助理教授,本博毕业于清华大学电子工程系,曾任英特尔中国研究院研究员和北京大学联合博士后,研究方向为几何与认知层面的场景理解及其在机器人中的应用。
另外,本文的模型已经开源,感兴趣的可以去试试看~




