

 1991
1991
“2022年全球人工智能市场规模约为869亿美元,而到2030年,这一数字有望攀升至1.3万亿美元,人工智能(AI)或将成为未来5-10年最大的发展风口,从而催生几万亿,带动十几万亿,甚至几十万亿的庞大市场。” 这是是德科技大中华区高速数字市场部经理李坚在近日“Keysight World Tech Day 2025”上提到的数据。

的确,这两年伴随着大模型技术的快速迭代,不管是生成式AI,还是人形机器人、智能汽车等端侧AI都进入了爆发式发展阶段。于是常常有人问,AI时代的“杀手级应用”是什么?
是德科技高级副总裁兼通信解决方案事业部总裁 Kailash Narayanan告诉与非网的答案是:融合尖端科技的智能终端——它将集成AI模型、高性能计算引擎,搭载5G/6G无线芯片,并支持超短距离无线通信,在用途上可成为我们生活的强大助力。
事实上,在AI改变生活的道路上,每一台智能终端设备的惊艳表现,都离不开云、边、端的完美配合,离不开数据中心这个"幕后大脑"的强大支持。根据IDC的数据,全球算力需求正在以每3.5个月翻一番的速度增长。因此,我们看到2023年全球数据中心建设投资达到了980亿美元,同时2024-2025年间,数据中心领域的吸金能力只增不减。
然而,在AI数据中心快速建设的过程中,我们却发现动辄几百亿元建设的数据中心,其投资回报率(ROI)却常常差强人意。为什么这么说呢?下面分析几个常见的原因。
-
GPU闲置率超过60%
如今,数据中心中跑的已经不再是早期单向的中小模型,对算力的要求极高。以GPT-4为例,其训练参数量达到了1800B,OpenAI团队使用了25000张A100 GPU,并花了90-100天的时间才完成了单次训练,总耗电在2.4亿度左右,成本约为6300万美元。
不算运维中的电费消耗,仅硬件投入中,GPU的成本无疑是最高的一部分。然而,有数据表明,GPU并非时刻都在“工作”,在模型训练的过程中,GPU的等待时间超过了50%。
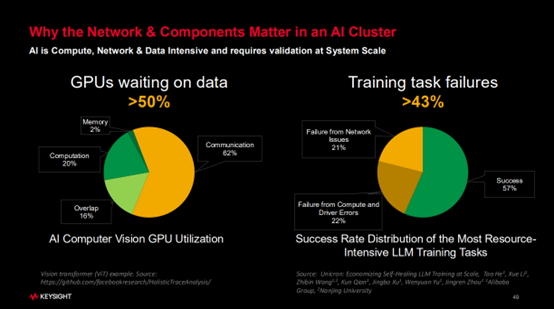
通过进一步分析,GPU的计算时间仅占20%,Overlap时间占16%,Memory时间占2%,而剩下62%的时间GPU都处于等待状态。
那么,导致GPU利用率低的原因是什么呢?很简单,因为GPU没有收到数据,自然无法进行计算。那为什么数据没有及时给到呢?这是因为宽带网络在数据交换的时候遇到了各种各样的阻碍。
我们知道,传统数据中心主要采用请求与响应的Client/Server架构,网络流量大多是 “南北向流量”,而在当下的算力中心中,大量GPU之间、节点之间以及超级节点之间都需要交换数据,于是产生了大量的“东西向流量”。
当网络流量发生变化时,特别是脉冲型流量的存在,原本用于构建数据中心网络的交换机就容易出现问题。这时,就需要引入新的流量管控和调节机制来支撑网络。如果流量调节机制不够完善,GPU就会大量时间处于等待数据的状态。这就好比道路上的红绿灯设置不合理,必然会导致交通拥堵。而这里的“红绿灯调节机制”,对应的就是交换机和网卡里的算法。
-
硬件/软件故障,导致训练跑偏
前面提到,OpenAI团队花了90-100天的时间才完成了GPT-4的单次训练,而今天的大模型比GPT-4还要大,所以其训练往往需要耗费数周甚至数月的时间。
有数据显示,当我们把数据输入系统并启动训练后,一次就能顺利完成任务的概率大概只有57%。那为什么训练任务常常无法顺利完成呢?这是因为在训练过程中,会出现各种各样的硬件或软件故障,尤其是硬件故障。
对此,李坚解释道:“如今,数据中心速率提升非常快,很多器件已经接近其物理极限。在高温、高速且24小时不间断的工作环境下,很多器件其实已经不堪重负,于是网络可靠性问题频发。”
“以NVIDIA的NV72大机柜举例,里面光是线缆就有五千多根,光缆和光模块也有上百块,一旦任何一个器件出现故障或问题,整个系统就有可能无法正常运行,必须停机、重启、恢复。如果我们不采取一些特定措施,比如断点保护和断点重启,那么即使之前花费大量时间进行训练,其数据可能也会全部报废。” 李坚补充道。
基于对以上问题的认识,产业界正在携手合作,来提升数据中心基层硬件和软件的指标。
李坚透露,是德科技也一直在密切关注AI产业发展面临的行业性痛点,并已经开始通过合作,来及时察觉网络中可能潜藏的各种问题,从而疏通网络流量,让网络运行变得更加有效。
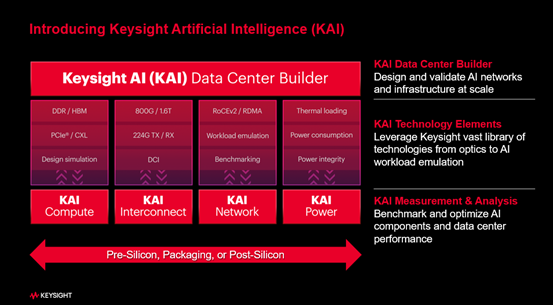
在这个过程中,是德科技在过去的两三年时间里,逐步梳理了自身产品线,并针对AI市场重新定义了AI产品矩阵,将其统一命名为“Keysight AI”,简称“KAI”。
“KAI”产品矩阵分为四大板块:KAI Compute(KAI高速计算)、KAI Interconnect(KAI互连)、KAI Network(KAI网络)和KAI Power(KAI能效),这四个板块都与网络结构直接相关,可覆盖从底层算力板卡到顶层网络架构的全栈测试需求。
-
KAI Compute(KAI高速计算)
数据中心的底层基础是算力板卡,其可能集成多个GPU(如四GPU、八GPU配置),并包含存储、GPU、CPU等组件,存在大量高速器件及接口和走线。为评估这些接口和走线,是德科技针对人工智能领域快速迭代的走线需求,推出“KAI Compute” 解决方案,涵盖算力板卡相关的所有测试手段,以此助力打造更稳定、可靠的算力。
-
KAI Interconnect(KAI互连)
数据中心的算力板卡需通过电缆、光模块、光缆等无源或有源的器件连接,形成节点或超级节点。这些高速率工作的器件数量众多,质量必须有保障。为此,是德科技推出“KAI Interconnect” 解决方案,包含网络分析仪方案、光模块采样示波器验证方案及高速误码仪等产品,确保互连部分的稳定性和可靠性。
-
KAI Network(KAI网络)
在数据中心中,为了将超级节点组成更大的算力网络,需要通过网卡、交换机等设备进行连接。在此过程中,从网络层到应用层都需要进行全面测试。为此,是德科技花16亿美元并购了Ixia,基于Ixia的技术沉淀,推出了“KAI Network”解决方案,来为网络端测试提供强大的技术支持。
-
KAI Power(KAI能效)
数据中心因高功耗被称为“电老虎”,一个集成十万板卡的算力中心耗电量甚至超过百万人口城市的用电量。其内部有大量高密电力器件,涉及交流转直流、直流转直流等转换,功率转换效率直接影响硬件成本、投资和运营成本。为此,是德科技推出“KAI Power”解决方案,来助力优化电力转换效率,降低数据中心能耗与成本。
值得一提的是,就在今年四月份举办的光网络与通信研讨会及博览会(OFC)上,是德科技围绕其市场战略推出了三款新品,分别为224G的单通道和双通道采样示波器N1093A/ N1093B、网络互连与网络性能测试设备INPT-1600GE和网络工作负载仿真器KAI数据中心构建器。
这三款产品各自有什么特点,又是针对哪些客户群体的呢?对此,李坚进行了详细介绍。

-
224G的高速采样示波器(N1093A/ N1093B)
当前网络正向224G演进,但目前大多仍处于112G或56G水平,少数领先厂商已达到224G。为满足这些厂商的需求,是德科技推出了全球首款224G采样示波器,目标客户为组件、光模块及光芯片厂商。
该产品支持单通道224G速率,多通道可达1.6T,核心指标噪点和抖动表现出色,主要用于光模块和电模块的物理层验证。
-
网络互连与网络性能测试设备INPT-1600GE
当光器件、光模块生产出来后,需要与网卡、交换机以及其他各个不同模块连通。在连接完成后,验证工作就不能仅仅局限于物理层,很多时候还需要在传输层和网络层进行验证,这就涉及到网络互连和性能的测试。
这款新产品支持高达1.6T的行业顶尖速率,不仅用于误码测试,还在传输层和网络层的验证中融入了层2 FEC统计的新功能。它具备极限性能测试能力,不仅能进行静态测试,还能在不同温度和链路条件下进行动态测试,验证模块的极限性能。所以说,它不仅是简单的“通过/不通过”测试工具,更是全面的性能评估设备。
-
网络工作负载仿真器
为了评估网络的有效性,数据中心的运维方需要仿真不同大模型运行环境下的各种流量,尤其是脉冲型流量,从而在网络上线前发现并解决问题优化网络架构,确保网络在高负载下的稳定性和效率。
为此,是德科技推出了一款运行在硬件平台AresONE上的软件KAI数据中心构建器,能够仿真真实网络中各节点可能出现的流量情况,包括计算结果传递和重新计算所产生的脉冲流量。
据悉,是德科技是行业内率先开展此类工作的公司,并已与北美领先厂商完成相关项目。
来源: 与非网,作者: 夏珍,原文链接: https://www.eefocus.com/article/1861518.html








