

 1036
1036
ChatGPT最近有多火,下面这张图说明一切。最近所有的媒体都在研究报道这玩意,连带着资本市场都被搅动,A股的ChatGPT概念股也节节攀升。
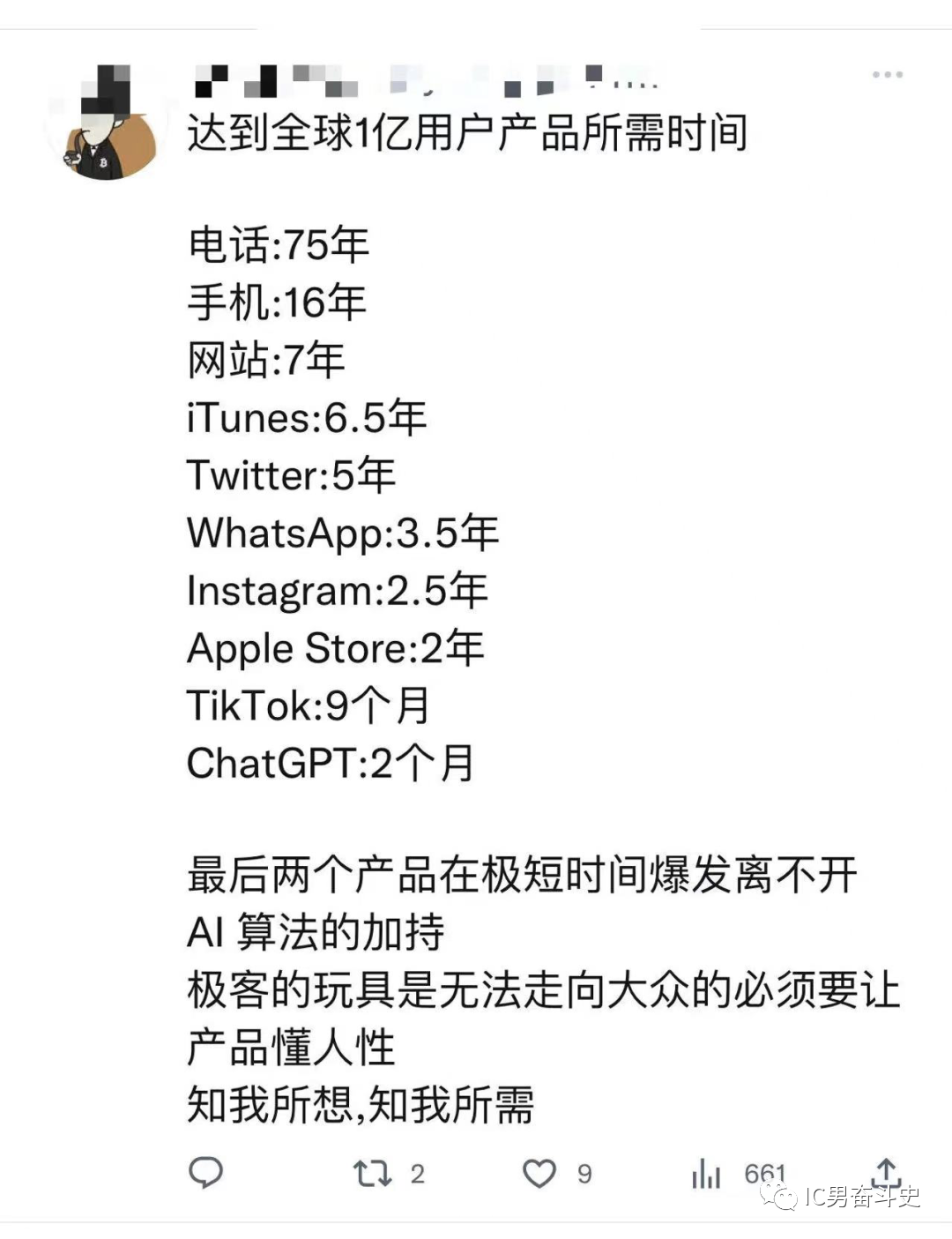
ChatGPT是什么以及它的发展历程,相信各位老铁们都已经很清楚,杰哥便不再赘述。大家都知道,杰哥是做AI芯片的,ChatGPT与杰哥的职业发展可谓是息息相关。今天杰哥想研究一下ChatGPT与AI芯片之间的关系。
有数据表明,ChatGPT训练需要消耗的算力大约为3640PF-days。也就是说,每秒运算一千万亿次的话需要运行3640天。假设我们有一个500P算力 (每秒可以进行500千万亿次运算) 的超算中心,完成ChatGPT训练需要花费7到8天时间。如果我们有7到8个这样的超算中心并行运算,完成训练就只需要花费1天时间。
参考近期超算中心的建设投资规模,一个算力约500P的超算中心总投资约为30亿人民币。要支撑ChatGPT的运行,至少需要7到8个这样的数据中心。也就是说,对于ChatGPT来说光基础设施的投入就要两百亿以上。
作为一家创业公司,OpenAI选择的还是一种相对轻快的数据存储和运行方法——上云。目前ChatGPT的训练都是基于微软的超算基础设施完成的。微软的超算设施主要是由英伟达V100和A100 GPU组成的高带宽集群。后续应该会升级到性能更强大的英伟达H100 GPU计算集群。
2023年1月23日,微软宣布向OpenAI追加100亿美元的投资,以支持其在ChatGPT领域的开发与拓展。2月3日,谷歌向人工智能初创公司Anthropic AI投资约4亿美元,后者正在测试ChatGPT的竞品Claude。ChatGPT背后巨大的算力需求将会给高性能计算领域带来巨大的市场需求,这其中收益最大的当属以英伟达为代表的云端AI芯片企业。
ChatGPT背后的AI芯片
英伟达目前能支持ChatGPT运行的主要产品有V100、A100和T100三个系列。同样的,国产AI芯片也拥有训练能力,也可以支持ChatGPT的运行。代表产品有寒武纪思元290、壁仞科技BR100、燧原科技的邃思2.0以及百度昆仑芯2代等。
1英伟达V100/A100/H100
V100:单颗芯片可以提供125TFLOPS的算力 (以FP16计算) ,可以使用新一代 NVIDIA NVLink技术以高达 300 GB/s 的速度连接多个 V100 GPU,从而打造出功能极其强大的计算服务器。
A100:单颗芯片可以提供624TFLOPS的算力 (以FP16计算) ,与 NVIDIA NVLink、NVIDIA NVSwitch、PCIe 4.0、NVIDIA InfiniBand和NVIDIA Magnum IO SDK 结合使用时,它能扩展到数千个A100 GPU。2048个A100 GPU可在一分钟内成规模地处理 BERT之类的训练工作负载,这是非常快速的解决问题速度。
H100:单颗芯片可以提供2000TFLOPS=2PFLOPS的算力 (以FP16计算) ,使用 NVIDIA NVLink Switch系统,可连接多达256个 H100来加速百亿亿级 (Exascale)工作负载,另外可通过专用的 Transformer引擎来处理万亿参数语言模型。与上一代产品相比,H100 的综合技术创新可以将大型语言模型的速度提高30倍,从而提供业界领先的对话式AI。
2寒武纪思元290
思元290:单颗芯片可以提供256TOPS (以INT16计算),寒武纪玄思1000智能加速器整机在2U机箱内集成了4颗思元290智能芯片,最大可实现1PetaOPS (以INT16计算) AI算力。目前寒武纪思元290芯片的下一代产品还在研发中,根据公开信息,算力预计与英伟达A100相当。
3壁仞科技BR100
BR100:单颗芯片可以提供960TFLOPS(以FP16计算),最高可以实现8张卡全互连。其组成的性能强大的海玄服务器,可以实现单节点峰值浮点算力达到 8PFLOPS(每秒8000万亿次运算)。
4燧原科技邃思2.0
邃思2.0:单颗芯片可以提供128TFLOPS(以FP16计算),云燧智算集群搭载多个邃思2.0芯片,在典型配置下每个单元可以实现8PFLOPS AI算力,并且支持按需横向扩容,可支持超千卡规模集群。
5百度昆仑芯2代
昆仑芯2代:单颗芯片可以提供256TOPS@INT8或者128 TFLOPS@FP16的算力。搭载8个昆仑芯2代芯片的AI服务器,单机可提供高达1PFLOPS的AI算力和256G显存。基于多芯片间高速互联K-Link技术,可构建大规模并行计算集群、支持超大型模型训练和推理的需求。
总结下来,国产AI芯片与英伟达产品的差距在硬件性能上差距不大,基本上也就是半代到一代之间的差距。例如寒武纪和壁仞科技的最新款云端训练芯片思元590和BR100在算力都接近甚至超过英伟达A100,但是要落后于英伟达下一代产品H100。所以,国内发展类似于ChatGPT这样的机器人模型在硬件支持上是具备国产化的条件的。
国内高性能计算AI芯片的发展在硬件上与国外顶尖企业的差距其实并不大,反而在软件生态上的差距很大。国内AI芯片企业要真正达到国外巨头的水平,还有很长的路要走。



-1-%E5%89%AF%E6%9C%AC.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)


