

 201
201
OpenAI正式发布GPT-5.4系列模型,这是其迄今为止能力最强、效率最高的专业工作前沿模型。与常规迭代不同,GPT-5.4在技术架构上实现了质的飞跃:首次将计算机使用能力原生内置、支持100万Token超长上下文、引入Thinking透明推理机制,并深度融合了此前分散在多个专用模型中的能力。本文将从技术底层拆解GPT-5.4的核心突破,解析其架构设计、性能优化与应用价值。
对于国内AI爱好者、开发者和内容创作者而言,GPT-5.4的发布意味着智能体应用已进入可规模化落地阶段。若需国内直接访问体验GPT-5.4及Gemini 2.0、Claude 3.5等聚合模型,可参考KULAAI(dl.kulaai.cn)等国内镜像平台。
一、架构革新:从“对话模型”到“原生智能体”
GPT-5.4的技术核心在于将此前分散的能力——GPT-5.3-Codex的编码优势、增强的通用推理能力、原生计算机操作能力——深度融合为统一系统。这一架构设计意味着模型不再依赖外挂工具或代理层,而是将计算机使用能力直接整合进模型权重中。
1.1 原生Computer Use:感知与决策的端到端整合
GPT-5.4是OpenAI首款具备原生计算机操作能力的通用大模型,支持智能体通过屏幕截图理解界面,直接输出鼠标点击、键盘输入、拖拽文件等操作指令。其核心技术机制可概括为“截图 → 分析 → 操作 → 验证”的闭环流程:
模型在看到屏幕截图后,能在同一次推理中同时完成视觉理解与操作决策
感知与决策的整合让AI Agent能更快速且连续地执行多步骤任务
降低了传统自动化工具中间转译与调用API的复杂度
这一能力的实现得益于OpenClaw创始人彼得·斯坦伯格(Peter Steinberger)的加入,其团队将桌面自动化技术深度整合进GPT-5.4架构。
1.2 工具搜索(Tool Search)机制
GPT-5.4引入了全新的工具搜索(Tool search)功能,使模型可动态查询所需工具定义,而非将所有工具定义预先包含在提示中。这一创新带来两大收益:
Token消耗降低约47%:在保持准确率的前提下大幅提升效率
保留缓存机制:请求更快、更便宜
对于开发者而言,这意味着模型在处理大型工具和连接器生态系统时,能够更高效地找到并使用正确的工具,而不牺牲智能。
二、核心性能基准测试数据
GPT-5.4在多项关键行业基准测试中刷新最优成绩,以下是核心数据对比
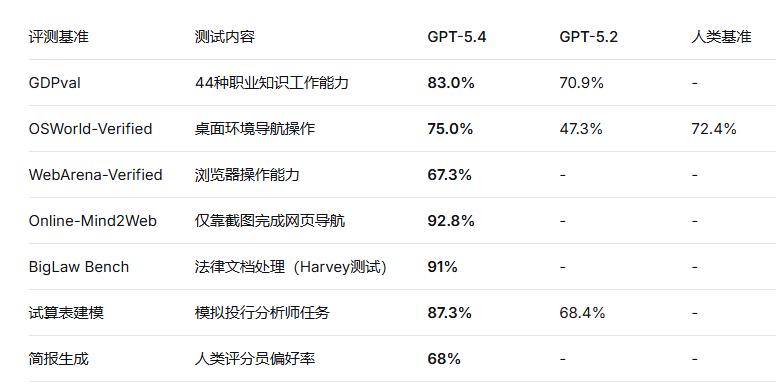
数据解读:
GPT-5.4在OSWorld-Verified中首次超越人类专家平均72.4%的表现,代表AI已具备在真实桌面环境中完成复杂任务的能力
Online-Mind2Web 92.8%的得分说明模型能处理未经优化的真实网站界面,视觉理解与操作能力达到相当成熟的水准
事实准确性显著提升:与GPT-5.2相比,单条陈述错误率下降33%,完整回复错误率下降18%
三、百万Token上下文窗口:从“阅读理解”到“全库分析”
GPT-5.4将API上下文窗口扩展至100万Tokens,与Google、Anthropic等厂商的顶级产品持平。这一突破意味着模型可以直接处理:
整本技术手册
数年的财务报表
整个项目的代码库
长周期智能体任务的规划、执行与验证
技术价值:过去开发者不得不把长文档切片、建立向量数据库、再进行RAG(检索增强生成),这种“打补丁”方式往往丢失全局语境。百万Token窗口使模型能够直接理解模块间的隐式依赖关系,对于企业级应用具有颠覆性意义。
坊间传闻:部分消息源透露,后续版本可能将上下文窗口进一步扩展至200万Tokens,并引入“状态化AI”(Stateful AI),实现跨会话持久记忆。
四、Thinking模式:透明化推理与实时交互
GPT-5.4 Thinking模式彻底改变了传统AI的“黑箱”交互方式,引入两大核心机制:
4.1 思考路径预展
AI在生成答案前先展示其问题拆解计划
用户可实时观察AI的推理逻辑,并在过程中随时调整方向
例如在解决复杂数学问题时,用户能看到AI如何分步骤推导,甚至中途修正错误假设
4.2 深度搜索增强
针对专业领域或细分查询,模拟人类专家行为进行多轮跨信源搜索
自动比对、合成高质量答案
在医疗诊断等场景中,能结合最新论文、临床指南和病例数据提供更可靠建议
OpenAI强调,这种实时可控性是与前代推理模型的显著区别——以往中途修正往往需要完全重启。
五、视觉能力升级与专业场景优化
5.1 视觉理解提升
GPT-5.4视觉能力显著增强,现在可以分析高达1024万像素的图像,或最大尺寸达到6000像素的图片。这意味着:
前端工程师可直接丢给模型极其精细的UI设计图
科研人员可上传高分辨率工程原理图
实现像素级的视觉分析,告别过去AI对着模糊压缩包“一本正经胡说八道”的体验
5.2 专业办公场景优化
GPT-5.4专为知识工作者设计,在以下场景表现突出:
试算表建模:模拟投资银行分析师任务得分87.3%,远超GPT-5.2的68.4%
简报生成:人类评分员偏好率达68%,原因在于更强美感设计、视觉变化以及有效运用图像生成工具
代码生成:继承Codex编程基因,能理解整个系统架构设计,处理复杂重构任务
六、技术局限与未来展望
尽管GPT-5.4实现重大突破,但实际应用中仍存在一些问题:
前端界面表现:逊于Opus 4.6和Gemini 3.1 Pro
现实世界背景理解:有时忽略显而易见的情境信息(如规划旅行忽略人潮拥挤)
任务完成稳定性:在OpenClaw中测试时,经常在完成任务前突然停止
OpenAI CEO山姆·奥特曼已回应将尽快解决这些问题。
API定价方面:
GPT-5.4:输入2.5美元/百万Token,输出15美元/百万Token
GPT-5.4 Pro:输入30美元/百万Token,输出180美元/百万Token
批量和灵活定价为标准API费率的一半,优先处理为标准费率的两倍。



