


















 2538
2538
超异构计算,作为具有划时代意义的算力技术革命,这个趋势已经非常明显。
最近在梳理一些巨头的超异构计算发展趋势,发现:Intel在做非常宏大的战略层面的布局,而NVIDIA则已经在执行层面全面行动。NVIDIA在云、网、边、端等复杂计算场景,基本上都有重量级的产品和非常清晰的迭代路线图。
1 从传统SOC到超异构的思考
1.1 向前进1%,创新+重构
经过漫长历史的演进发展,人类和黑猩猩的基因相似度依然高达96%。在某个历史分叉点,也许和黑猩猩基因差别只有不到1%的人类的祖先,开始直立行走,从此开启了人类新的篇章。
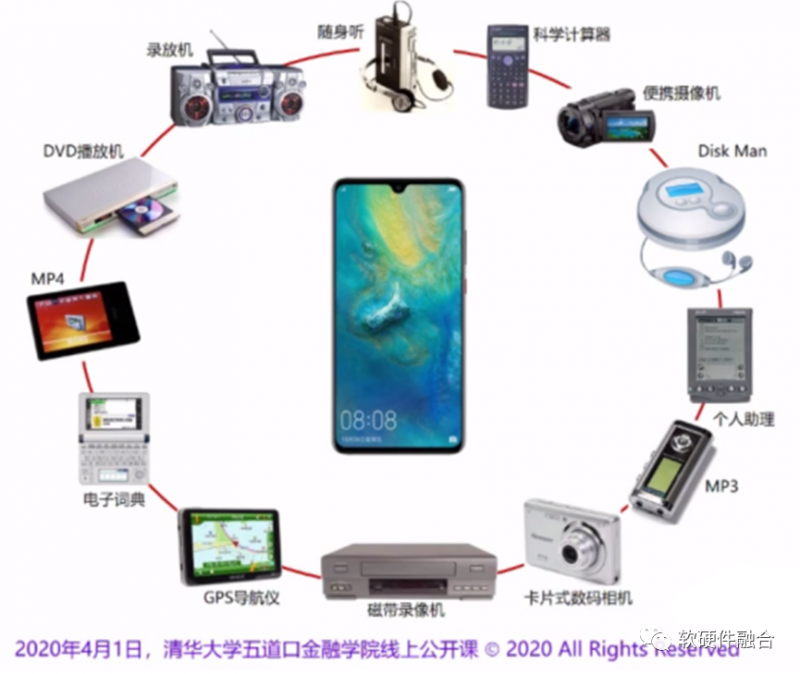
所谓的创新,一定是在历史积累的过程中,向前进了那么一点点。但这一点点,会决定整个事情的性质和特征,从而对我们的社会和生活产生剧烈的影响。
苹果重新发明了(智能)手机,iPhone所拥有的技术,基本上之前都存在。它真正做的,就是把这些技术重新整合到了一起,以及把这里的一些技术往前推进了那么一点点,“而已”!
1.2 从SOC到超异构,创新+重构
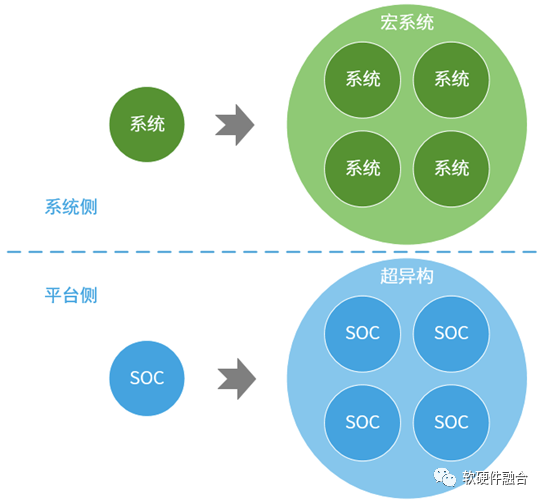
系统变得越来越庞大,系统可以分解成很多个子系统,子系统的规模已经达到传统单系统的规模。因此,都升级一下:系统变成了宏系统,子系统变成了系统。关于SOC和超异构(HPU即超异构处理器)的区别,我们总结如下:
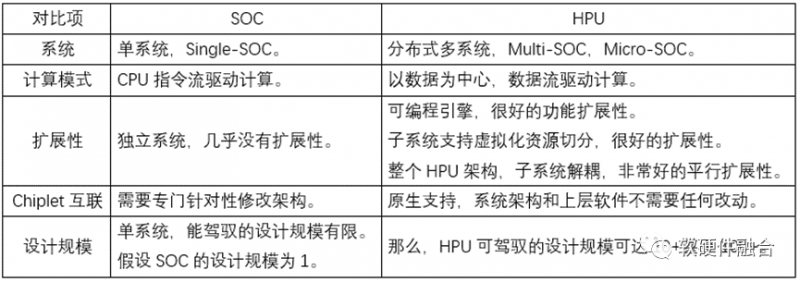
从SOC到超异构Multi-SOC,不是简单的集成,而是要把整个系统先解构,然后重新整合重构。只有这样,才能构建满足未来更高要求的超异构宏系统。
1.3 超异构计算,具有划时代意义的算力技术革命
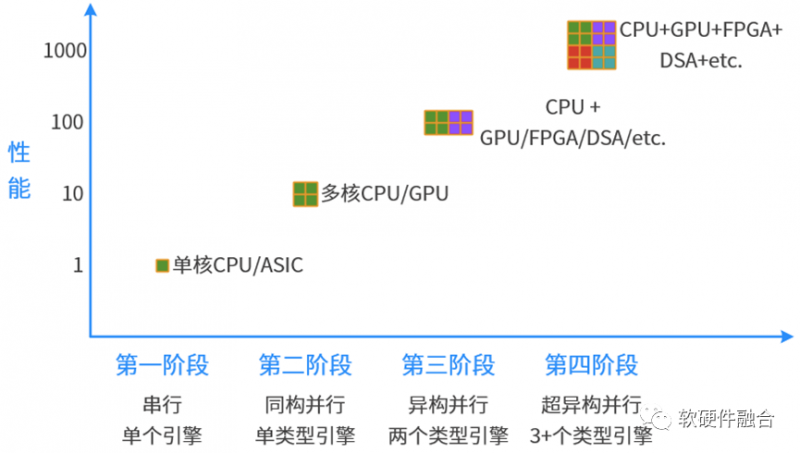
从单核到多核,从同构到异构,都可以算是具有划时代意义的计算架构创新。
到了异构计算之后,更多是受限于编程的复杂度,以及CPU的性能仍然在快速提升,因此在异构这里大家停留了很久。通过xPU的各种架构创新,包括DSA架构的出现,都是为了更好地提升xPU的性能和通用性,以此来优化异构计算的性能/灵活性。
但异构计算局限在某一个特定领域,每个领域的异构计算都是一个个孤岛。
世易时移,新的划时代意义的架构创新的时机到来,那就是计算从异构开始走向超异构。
关于超异构的论述,可以参看公众号之前的相关文章。
2 NVIDIA在云和边数据中心芯片的布局
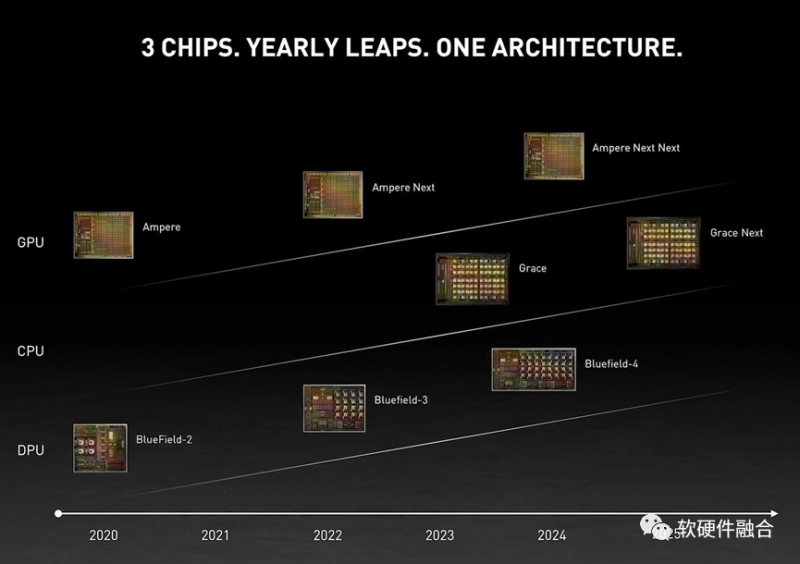
图 NVIDIA 数据中心CPU、GPU、DPU的roadmap
NVIDIA GPU从Ampere到下一代,也就是目前已经正式发布的Hopper。即将推出基于ARM Neoverse架构的Grace CPU芯片。而Bluefield DPU则是大概两年一个版本。

图 NVIDIA融合加速器(Converged Accelerators)
NVIDIA从2020年10月正式宣布DPU以来,就从板卡层级,把DPU和GPU通过PCIe相连接,做了一个融合DPU和GPU的解决方案。

图 NVIDIA DPU Roadmap
再来详细看看NVIDIA DPU的Roadmap,NVIDIA计划从Bluefield第四代开始,把DPU和GPU两者集成一个单芯片。
NVIDIA DPU和GPU集成了,也已经有了独立的Grace CPU。那么,在Chiplet技术已经成熟的情况下,再把CPU集成进来,构成CPU+GPU+DPU的超异构芯片,还会远吗?(不远,因为在自动驾驶端已经有了。)
3 NVIDIA在自动驾驶(终端)的布局

图 NVIDIA 自动驾驶芯片roadmap
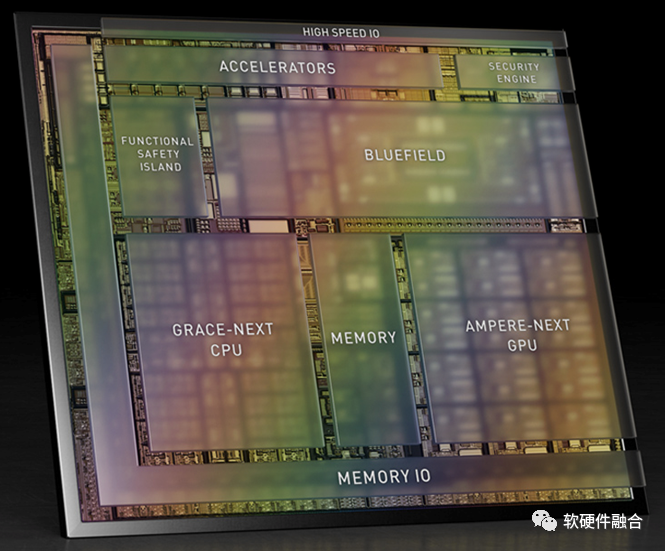
图 NVIDIA计划2024年推出的自动驾驶芯片Atlan
NVIDIA在自动驾驶领域的芯片发展,也基本上是2年一代产品。
- Parker是一颗典型的SOC,包括CPU、GPU和其他一些相关的加速引擎以及I/O设备。Parker SOC包括:256核Pascal架构GPU,6个CPU核(4个ARM Cortex A57和2个 ARM Denver),这是英伟达面向车规级的第一颗SoC芯片。
- Xavier则拥有8核ARM 64 CPU(Carmel)和512核Volta架构GPU。Xavier专为自动驾驶系统设计,还搭载了深度学习加速模块DLA和向量处理单元PVA。DLA主要用于推理,PVA主要用于加速传统视觉算法,这是英伟达首次采用CPU+GPU+DSA的技术路线。并且在Xavier的基础上,推出Pegasus板级平台:由2颗Xavier芯片和2颗单独的Turing架构的GPU(4680CUDA Core+576 Tensor Core+RT Core)组成,可以实现320 TOPS的算力。
- Orin芯片包含8-12核的ARM Cortex A78 CPU,以及2048核的Ampere架构GPU,以及DLA,以及视频编解码等其他加速引擎。DRIVE AGX Orin平台,由2颗Orin SoC芯片和2颗 Ampere架构的GPU组成,最高算力达到2000 TOPS,功耗800W。
- 而到了2024年要发布的Atlan芯片,则完全变成了集成ARM Neoverse系列的Grace CPU、有可能是Hopper架构的GPU以及Bluefield DPU,可以单芯片达到1000 TOPS。
从量变到质变,Atlan从SOC到超异构,随着集成单元的增多,随着性能需求的上升,随着系统复杂度的上升而对芯片的通用灵活可编程能力要求上升,都需要全新的架构,全新的整合重构。
4 NVIDIA观点:网络视角的DPU发展趋势
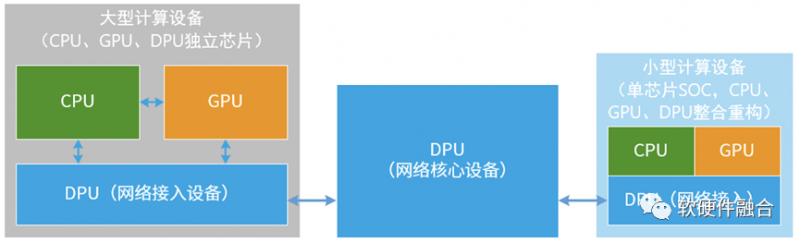
整个互联网是通过网络把设备连接起来组成的,站在网络视角,设备主要有两类:
在传统视角下,计算和网络是相互独立的,各自关心自己的事情。但随着云计算、边缘计算的不断发展,网络也越来越复杂;在应用需求的推动下,计算所需的性能在急速增长,但随着CPU性能瓶颈摩尔定律失效,需要通过各种方式进行计算加速,使得问题变得非常的复杂。
网络和计算都遇到了瓶颈问题,单独地以各自的方式解决各自的问题,难度都很大。而把两者融合起来,用网络的方式解决计算的问题,用计算的方式解决网络的挑战,却是非常的高效。未来的一个重要趋势是,计算和网络在不断融合:
- 计算的很多挑战,需要网络的协同,来更高效地解决。网络设备也加入到计算集群中,成为计算的一部分。
数据量越来越大,而数据在网络中流动,计算节点也是靠数据的流动来驱动计算,计算的架构从以计算为中心转向了以数据为中心。所有的系统本质上就是数据处理,那么所有的设备就都可以是Data Processing Unit。
未来,以DPU为基础,不断地融合CPU和GPU的功能,DPU会逐渐演化成数据中心统一的超异构处理器。

 下载ECAD模型
下载ECAD模型






.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)

.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
