

 2758
2758
首款18A数据中心CPU——“激进”的革新、“保守”的命名
18A所具备的成熟度和稳定性,已经在两款最新处理器上得到了验证。先来看首款Intel 18A数据中心处理器至强6+(Clearwater Forest),其性能飞跃,不仅源于内核创新,更得益于先进且成熟的制程与封装技术。

Clearwater Forest最震撼的是将288个能效核集中在单个CPU内部,相比于上一代Sierra Forest 6700E,相当于直接翻倍了——一些业内人士认为核心密度从144到288的提升,将会在各个层面实现颠覆性的变化,可以说是跨时代的升级。同时,它将内存速度推高到8000MT/s DDR5(几乎是已知最高的服务器产品内存速度)。末级缓存表现也很亮眼,最高可支持最高576MB。
正如上篇文章所说,由于18A是业界首个将PowerVia与RibbonFET集成的制程节点,二者结合使芯片单元利用率提高10%,并在相同功耗下带来约4%的性能提升。
通过创新的先进封装和模块化设计,英特尔实现了为云原生时代量身定制的、高度先进且复杂的处理器Clearwater Forest,其核心目标是在提供巨大算力密度的同时,实现最优的能效表现。
再来看下封装层面的创新,首先,Clearwater Forest广泛采用了Foveros Direct 3D先进封装。其铜对铜键合支持的凸点间距可达微米量级。该技术的核心在于其有源硅基板,它不仅承担了晶粒间互联的桥梁作用,更可集成逻辑与存储单元,从而显著提升互联带宽并扩大三级缓存容量。整个设计相当于在非常小的尺寸空间里堆叠了29个芯片,实现了高算力和高密度。

其次,12个计算单元通过混合键合与下层采用Intel 3工艺的3个有源硅基板相连,同时,基板与两侧I/O单元则通过EMIB实现2.5D互联,共同构成一个高密度的3.5D系统级集成架构。
得益于这些设计,Foveros Direct 3D 能够以高密度、低电阻的方式连接不同晶片,其能效表现卓越,每比特能耗可低至 0.05 pJ,约为传统2.5D封装技术能耗的十分之一。并且值得注意的是,Clearwater Forest使用的I/O单元和至强6的性能核处理器是一致的,因此可以实现平台兼容性的无缝升级。
再来看下内核的提升。Clearwater Forest 搭载新一代 Darkmont 内核,相比上一代Sierra Forest的Crestmont内核,通过大幅拓宽指令流水线与翻倍算力单元,在同等功耗下实现了高达 17% 的IPC 提升,带来整体性能 1.9 倍 的飞跃,并在全负载范围内实现 23% 的能效优化。
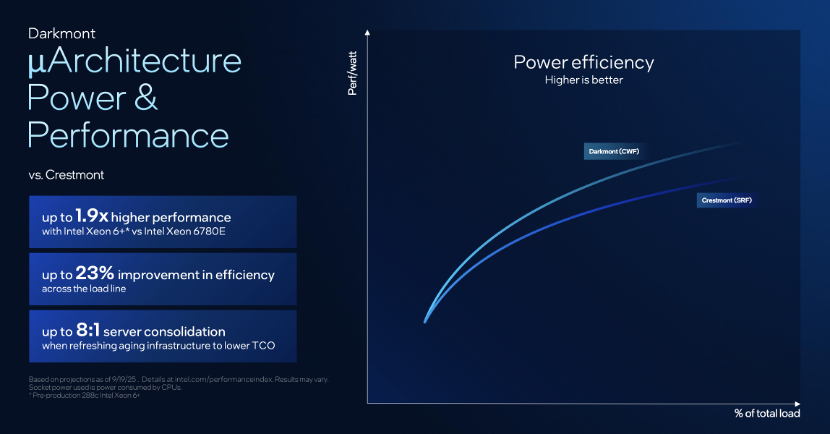
Clearwater Forest和第二代至强处理器对比,可以实现20台机架180台Clearwater Forest服务器替代70个机架1400台第二代英特尔至强服务器的效果,也就是说,实现相同算力的目标下,Clearwater Forest可以达到8:1服务器整合的效果,同时降低整机功耗750kW,降低71%的数据中心占用空间,同时提升3.5倍的性能/功耗比,每台机架上也可以增加2.3倍的虚拟机部署数量。
从至强6开始,英特尔在产品路线图上做出了一项重要调整:在原有的性能核基础上,新增了能效核产品线。性能核产品(代号Granite Rapids)在保障良好能效的基础上,着力提升单核性能,更适合计算密集型工作负载;而能效核产品(代号Sierra Forest)则在满足基本性能要求的前提下,专注于优化每瓦性能与核心密度,更适用于需要快速横向扩展和高吞吐量的场景。
Sierra Forest能效核处理器自去年六月发布以来,已获得业界广泛认可,并与多家主流云服务商及5G/6G核心网运营商展开大规模部署。根据实测数据与合作伙伴反馈,至强6能效核处理器的每瓦性能提升至之前的3.8倍,单台服务器吞吐量提升高达5倍。

英特尔方面透露,新一代Clearwater Forest之所以命名为“至强6+”而不是“至强7”,是强调其作为至强6平台的兼容性升级版本,属于同一产品家族的自然延伸,旨在为客户提供平滑的升级路径和差异化的产品体验。不过,从这代产品本身的性能飞跃来看,这个命名还是略显“保守”了:)
“至强6+”将专注于能效核与高核心密度,契合5G核心网、Web服务等高吞吐、高并发场景,通过规模化扩展显著提升性能。目前,核心合作伙伴如爱立信已将其应用于其云原生基础设施与双模5G核心网中,并取得了显著成效。
Panther Lake “Buff叠满”,AI PC和边缘应用的“六边形”算力方案
代号为Panther Lake的酷睿Ultra处理器(第三代),是首款基于Intel 18A制程工艺打造的客户端 SoC,是英特尔在客户端与边缘侧落地的关键产品,承接了 “以工作负载为中心” 的开发理念和 AI规模化的战略方向。它站在英特尔多个前沿技术平台的肩膀上,通过“博采众长”实现了“Buff叠满”,旨在为AI PC、游戏设备和边缘应用提供一款强大的“六边形”算力方案。
先来概述一下Panther Lake的三大特征:增强的架构灵活性、全负载性能扩展、以及领先的能效,其战略意图在于:通过灵活性来扩大市场覆盖面;通过全工作负载性能确保在各类应用(尤其是AI应用)中提供顶级体验;通过能效领先来构筑在移动和边缘计算领域的核心优势。
下图先感受一下Panther Lake的完整画像,我们再从最核心的架构特性、GPU提升、AI性能等一一解读。

首先,Panther Lake融合了Lunar Lake的高能效和Arrow Lake的高性能。二者优势合一,让它成为一个兼具出色能效、性能和强大扩展性的产品系列。并且与Lunar Lake和Arrow Lake相比,Panther Lake还有一个很大的特点就是规模化,它有望深入到各个不同的细分领域,让OEM客户充分发挥终端产品优势,在PC、机器人、手持设备等领域都能发挥强大实力。

从整体结构来看,Panther Lake就像是一款高度异构的“全能战士”。它采用了Foveros-S工艺,在封装内集成了专用的GPU单元和平台控制器,以满足终端设备对图形、AI、能效和外围连接的全方位需求。
它主要具备四大特点:首先,核心架构上采用无IP依赖和可灵活分区的通用架构,支持多种模组灵活集成;其次,依托成熟的2.5D Foveros-S封装工艺,在芯片内可以实现高效堆叠和低延迟互连;第三,具备独立的GPU单元,支持图形性能按设备需求做扩展;第四,集成I/O和平台功能模块统一集成,简化系统设计,能够提升平台的一致性。

英特尔Foveros封装工艺可以带来更加极致的密度和能效,为高性能计算和AI加速提供高效互连,其中,Foveros-S在2019年就进入规模生产,迄今为止已经是一项成熟技术了。
此处略微对比一下Panther Lake和Clearwater Forest在封装技术上的差异:由于应用场景不同,前者面向客户端与边缘设备,旨在打造高性能、高能效,后者面向数据中心服务器,追求极致的每瓦性能、核心密度和吞吐量。
体现在封装复杂度方面,Panther Lake采用相对标准的Foveros 3D堆叠,而Clearwater Forest采用相对更复杂的 3.5D混合封装,结合了Foveros Direct 3D和EMIB 2.5D,实现了前所未有的核心密度。
Panther Lake架构可衍生出不同配置,例如8核(基础型号)、16核(高性能型号)、以及16核+12Xe 核显的高端型号。
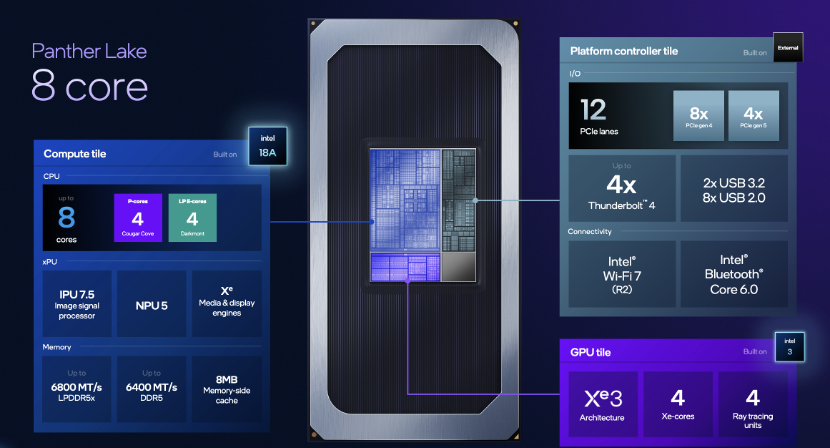
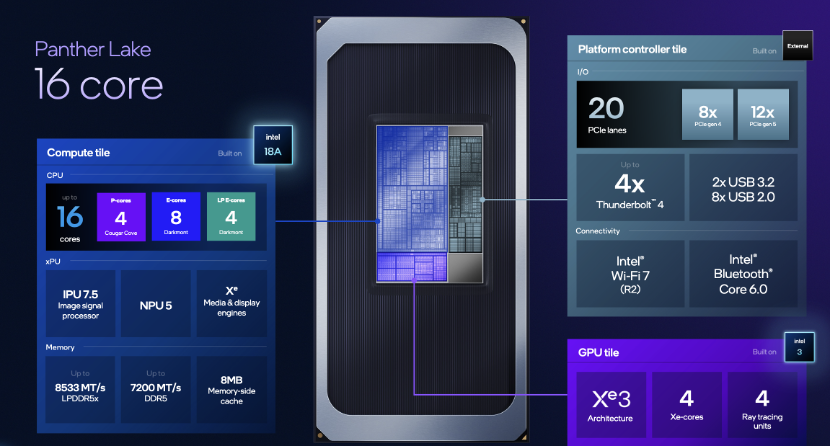

补充一下英特尔客户端混合架构方面的演进情况,自Meteor Lake起确立了P核(性能核)、E核(能效核)与LPE核(低功耗能效核)三级核心协同策略,持续演进。发展到Panther Lake,该架构实现了全面强化,实现了50%的性能提升以及30%的功耗降低:性能核升级为Cougar Cove,L3缓存增至18MB,引入AI驱动的电源管理,提升响应与能效;能效核升级为Darkmont,兼顾多线程性能与能效,适用于游戏与内容生成;低功耗能效核则专注于持续优化日常功耗表现。
再来看GPU,Panther Lake采用全新的Xe3架构,并且将GPU单独部署在专用的图形模块当中。可以根据不同的应用场景来调整GPU的规模,实现按需定制,同时通过die to die的互连技术,让图形模块和计算模块之间形成了超高带宽、超低延迟的互连。

Panther Lake的GPU提供两种规格:入门级的4Xe GPU,以及英特尔有史以来性能最强、规模最大的12Xe GPU。
其中,4Xe GPU的基本配置:包含4个Xe核心、32个XMX引擎、4MB L2缓存和1个几何管线等。12Xe Core GPU配置则具备更强的计算能力,包含12个Xe核心、96个XMX引擎、16MB L2缓存、2个几何管线、12个采样器、12个光线追踪单元和4个像素后端,计算能力、后端像素处理能力以及缓存能力都更为强大。

这也意味着,Panther Lake的GPU已经成长为一个高性能、高能效且功能全面的集显方案,用户可在不依赖独立显卡的情况下,就能在AI PC上获得流畅的游戏体验、高效的视频剪辑能力,以及强大的本地AI应用支持。

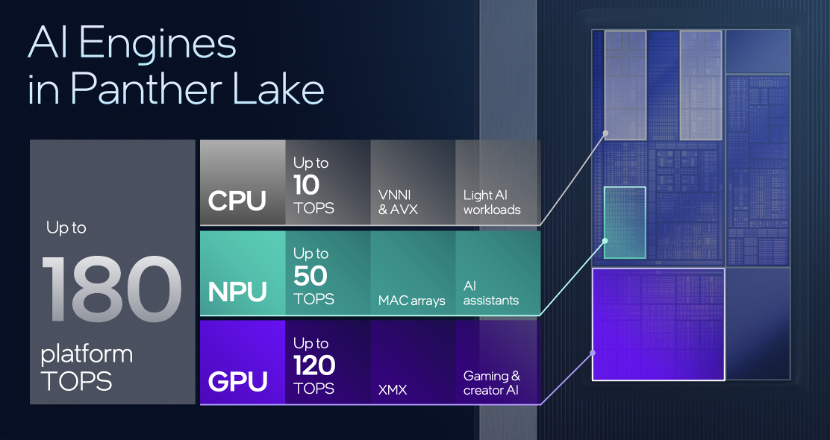
Panther Lake所搭载的新一代NPU 5也实现了性能的飞跃,50 TOPS的AI算力与Arrow Lake-H的NPU相比,提升了3.8倍;与Lunar Lake的NPU相比,每单位面积的TOPS(计算密度)提升超过40%。此外,新增了对FP8数据格式的支持,这对于AI推理而言是关键特性,因为FP8在保持精度的同时,能够显著降低内存占用、提高计算效率,从而进一步提升实际AI应用的性能和能效。NPU 5的升级其实是全方位突破,在算力、计算效能、AI智能等方面都能够带来更强的本地体验。
此外,Panther Lake在无线连接方面,通过高度集成的设计和新一代技术标准,带来了更高效、稳定和智能的连接体验。主要包括全新的Wi-Fi 7 R2、蓝牙6.0与LE音频等,以及无线软件套件ICPS 5.0,能够通过 AI 感知技术动态优化网络。
IPU方面,Panther Lake 集成了新一代 IPU 7.5,通过深度整合与AI能力,实现了影像处理在画质、能效及功能上的全面突破。

首先,集成IPU的优势是可与系统共享内存,支持无限分辨率的高级时域处理,并能直接调用CPU、GPU、NPU进行协同AI处理,相比分立方案效率更高。其次,IPU 7.5全新功能包括:一是增强型HDR,用于更宽的动态范围;二是基于AI降噪,在弱光环境下能实现更清晰的图像;三是AI驱动的局部色调映射,可智能优化局部对比度。
从平台算力来看,Panther Lake最高可达180TOPS,其中CPU贡献10TOPS,NPU贡献50TOPS,GPU贡献120TOPS。当然,算力提升并非简单的数字叠加,而是源于不同的硬件单元可被用在不同的负载上。其中,CPU主要支持轻量级AI工作负载,NPU用来支持持续性低功耗的AI负载,而GPU则服务于高吞吐量、高性能要求的负载。三者结合,可实现良好的协同效应。
据悉,Panther Lake将于今年开始进入大规模量产,首款SKU预计在年底前出货,并于2026年1月实现广泛的市场供应。
写在最后
英特尔ITT技术盛会,清晰地勾勒出它在AI时代的进击路径与底层逻辑。其意义远不止两款处理器的发布,背后更是英特尔对“制程-架构-封装”三位一体创新的系统化实践,是从“单一芯片”到“系统级芯粒”设计理念的转身,也是直面AI下半场“推理规模化”核心命题的算力答案。
18A也不仅是英特尔自身工艺的里程碑,更预示着芯片制造一种新范式的成熟:通过开放、异构与集成,在性能、能效与成本之间找到最优解,就能支撑AI规模化落地的多元需求。英特尔正以扎实的工程之本,以系统级的创新,探寻下一代智能计算更具弹性与效率的基石。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1902178.html




