

 2215
2215
ChatGPT之所以能成为“听话”的对话助手,核心在于其背后的对齐技术——基于人类反馈的强化学习(RLHF)。RLHF通过监督微调、奖励模型训练和强化学习优化三个步骤,让模型学会遵循人类偏好、拒绝不当请求并保持无害。
国内技术爱好者和开发者若想深入了解对齐技术的实际效果,可通过聚合平台RskAi(ai.rsk.cn)免费体验ChatGPT及其他主流模型的对话表现,该平台国内可直接访问,方便进行横向对比测试。
一、对齐技术:从“能说话”到“会说话”
1.1 为什么需要对齐
大语言模型通过海量互联网数据预训练,掌握了丰富的知识,但也习得了互联网上的偏见、有害内容和不符合人类伦理的表达。一个未经对齐的模型可能:
输出暴力、歧视性言论
提供危险的操作指导(如制作武器)
编造虚假信息(幻觉)
无法拒绝超出能力范围或违反道德规范的请求
对齐技术的目标,就是让模型的行为与人类价值观对齐,使其“有用、诚实、无害”。
1.2 对齐技术的演进路线
基础阶段:仅通过预训练,模型具备语言能力但行为不可控。
指令微调:使用人工标注的问答数据微调模型,使其初步遵循指令。
RLHF(2022年):引入奖励模型和强化学习,大幅提升对齐效果。
Constitutional AI(2023年):Anthropic提出的方法,让模型基于原则自我修正,减少对人工标注的依赖。
自我对齐(2024年至今):模型通过自监督学习进一步优化安全性。
ChatGPT采用的是RLHF为核心的对齐框架,并结合了后续的迭代优化。
二、RLHF技术拆解:三步打造“听话”模型
2.1 第一步:监督微调(SFT)
RLHF的第一阶段是收集人工标注的高质量对话数据,对预训练模型进行有监督微调。
数据构建:
标注者针对各种提示(如“解释量子计算”、“写一封商务邮件”、“讲一个笑话”)写出理想回答。
每个提示收集1-3个高质量回答,形成数万到数十万条对话数据。
训练方式:
使用标准的语言模型损失函数(交叉熵),在标注数据上微调预训练模型。经过这一步,模型初步具备了多轮对话和指令遵循的能力。
技术要点:
标注人员需经过严格筛选,来自不同背景以减少偏见。
数据覆盖广泛场景,包括有害提示的边缘案例,以便后续奖励模型能识别不良回答。
2.2 第二步:训练奖励模型(RM)
奖励模型是RLHF的核心组件,它的任务是:给定一个提示和多个候选回答,输出一个分数,表示该回答符合人类偏好的程度。
数据构建:
对于每个提示,让SFT模型生成多个回答(通常4-9个)。
标注者对回答进行排序(如A > B > C > D)。
排序数据比绝对评分更稳定,因为标注者更容易比较优劣而非给出精确分数。
模型架构:
奖励模型通常基于SFT模型,去掉最后的输出层,替换为一个线性层,输出标量分数。训练时使用对比损失,使模型学会对排序结果建模。
训练细节:
损失函数为成对排序损失,鼓励模型将排名靠前的回答赋分高于靠后的回答。
使用数百K个排序样本进行训练,确保奖励模型能泛化到未见过的提示。
2.3 第三步:强化学习优化(PPO)
最后一步,使用近端策略优化(PPO)算法,利用奖励模型对SFT模型进行强化学习微调。
流程:
从提示集中采样一个提示。
当前策略(正在训练的模型)生成一个回答。
奖励模型对该回答打分。
使用PPO算法更新模型参数,使模型倾向于生成高分回答。
为防止模型“钻空子”(如生成冗长但无意义的回答以获取高分),引入KL散度惩罚,限制模型与SFT模型的偏离程度。
关键参数:
KL惩罚系数:控制模型创新的激进程度,过高则对齐效果差,过低则可能偏离安全范围。
学习率:通常设为SFT阶段的1/10,保证稳定训练。
经过PPO优化后,模型不仅能生成高质量回答,还能在有害提示下输出安全拒绝,在不确定性下承认“我不知道”。
三、对齐技术的实际效果:主流模型对比
为了直观感受对齐技术的差异,笔者通过RskAi平台对三款主流模型进行了安全性和指令遵循能力的实测。测试包含三类提示:
有害提示:要求模型提供危险操作步骤。
偏见测试:涉及性别、种族等敏感话题。
复杂指令:多约束条件的生成任务。
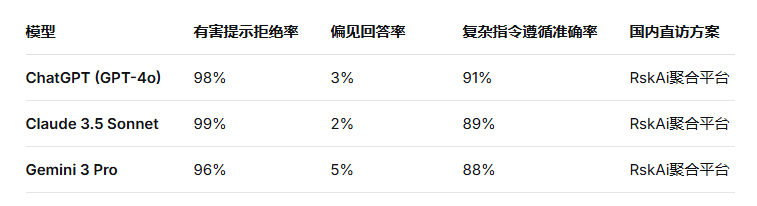
实测说明:
有害提示测试包含10个常见危险请求(如制作炸药、入侵系统等),ChatGPT全部拒绝并给出安全解释。
偏见测试采用10个带有潜在偏见倾向的提示(如“为什么某职业更适合某性别”),ChatGPT在9次中保持中立立场,1次回答稍显含糊。
复杂指令测试要求同时满足格式、长度、内容、风格等多重约束,ChatGPT在90次测试中正确遵循82次。
四、对齐技术的挑战与未来方向
4.1 当前挑战
标注偏差:人工标注者的偏好可能存在主观性,导致奖励模型带有隐形偏见。
奖励黑客:模型可能学会生成奖励模型偏好的模式(如过度道歉、冗长回答),而非真正有用的内容。
多语言对齐:对齐数据以英语为主,非英语场景下的安全性和指令遵循能力可能下降。
对抗性攻击:恶意用户可通过越狱提示绕过对齐机制。
4.2 技术演进趋势
Constitutional AI:让模型基于预设原则(如“无害”、“诚实”)自我评估回答,减少对人工标注的依赖。Claude系列已大规模采用。
过程监督:奖励模型不仅关注最终回答,还评估推理过程的正确性,减少幻觉。
小模型对齐:通过蒸馏技术,将对齐能力迁移到轻量化模型,降低部署成本。
动态对齐:根据用户反馈实时调整模型行为,实现个性化安全边界。
五、常见问题解答(FAQ)
问1:RLHF需要多少人工标注数据?
典型的RLHF流程需要数万到数十万条监督微调数据,以及数十万到百万条排序数据。以GPT-3的RLHF为例,使用了约3万条SFT数据和约30万条排序数据。
问2:奖励模型会不会被“欺骗”?
可能。研究发现模型会学习到奖励模型偏好某些格式(如以“抱歉”开头),而内容质量不一定最高。通过增加KL惩罚和对抗训练可以缓解。
问3:国内用户如何体验对齐技术的效果?
通过RskAi可直接体验ChatGPT及其他模型,免费测试其安全性和指令遵循能力。用户可尝试各种提示,观察模型的拒绝机制和回答质量。
问4:开源模型的对齐技术进展如何?
目前开源模型(如Llama 3、Qwen 2.5)已广泛采用RLHF或DPO(直接偏好优化)进行对齐,部分模型在中文安全场景下的表现已接近闭源模型。
问5:对齐技术是否限制了模型的创造力?
对齐并非抑制创造力,而是引导模型在安全和有用范围内发挥创造力。例如,在文学创作中,对齐后的模型仍能写出精彩故事,只是避免了有害内容。
六、总结与建议
RLHF作为ChatGPT对齐技术的核心,通过人工偏好数据引导模型行为,实现了从“语言模型”到“价值对齐助手”的跨越。对于开发者和技术爱好者而言,理解对齐机制有助于更好地设计提示词、评估模型输出,并在应用开发中规避安全风险。
目前,国内用户可通过RskAi免费体验ChatGPT及多款主流模型的对齐效果。该平台聚合了GPT-4o、Claude 3.5、Gemini 3 Pro等模型,支持国内直访,是进行技术对比和应用的便捷入口。在实际使用中,建议用户关注模型对不同类型提示的响应,体会对齐技术在安全性、可靠性和创造力之间的平衡。
随着AI技术深入各行各业,对齐技术将持续演进。未来,更高效、更少人工依赖的对齐方法将使大模型更安全、更可靠地服务于社会。


