

 1763
1763
开放标准的指令集架构正在重塑人工智能计算的底层规则。随着RISC-V芯片年出货量突破百亿级,尤其在AI加速器领域呈现指数增长,一场关于架构的探讨引起了计算产业的关注。
“RISC-V最激动人心的便是其在AI加速器方面的部署和贡献”,在第五届RISC-V中国峰会人工智能分论坛上,SiFive联合创始人、首席架构师Krste Asanovic表示。作为RISC-V发明者之一、开放指令集架构的奠基人,Krste Asanović的演讲聚焦于RISC-V应对AI计算的关键创新——从向量到矩阵的扩展指令设计。

Krste Asanović首先提出了一个趋势,AI往往需要对小型、专门的数据类型进行大量计算,这推动了数据类型的小型化趋势并显著增加了内存需求,促使业界专注于压缩参数大小、优化参数量化管理以缓解内存瓶颈;同时,巨大的内存占用与密集计算的结合要求极高的内存带宽。在此背景下,RISC-V因其通用计算模型(支持标量、向量及矩阵运算)而受到关注,其优势在于能兼顾处理通用任务与作为技术组件集成于AI应用的需求。
RISC-V内核的通用性(支持标量/向量/矩阵指令组合)为AI模型的快速迭代提供了极具灵活性的基础支持。
“尽管矩阵计算受关注,但大量核心步骤仍需向量引擎实现,凸显RISC-V在通用与专用计算间平衡的架构优势”,Krste Asanović指出,“关键向量扩展(RVV)不仅支持多数据类型,且对AI工作流至关重要。”这也是为什么,在2023年,关于RISC-V的矩阵扩展一度成为行业的关注热点。通过加速矩阵乘法关键操作,能够显著提升AI应用性能,覆盖从小到大各种规模的应用场景。
与此同时,AI的生态多样性也在催生大量矩阵乘法实现方案,不过函数复杂度远低于向量计算(向量库可能有成千上万的函数,矩阵库函数仅为十至数百的数量级)。为了提高性能,需要引入专用矩阵引擎(如图示红色模块),核心优化包括集成乘法累加器(MAC)等硬件,通过融合乘加操作减少数据搬运,直接提升计算效率。
面对AI计算中关键的矩阵运算需求,KrsteKrste Asanović指出,当前的矩阵扩展主要聚焦于4种技术路径,这些方式由基础到高级构成了完整的技术矩阵。
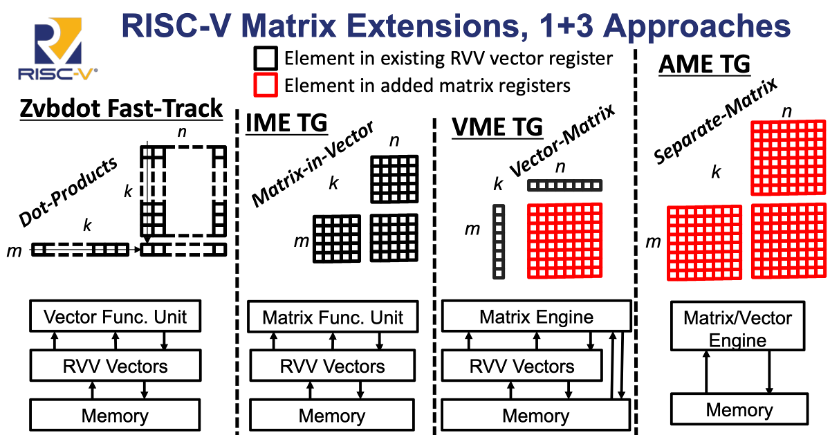
首先是专用矩阵与向量引擎:需要更多矩阵和向量引擎加持,通过新增大矩阵累加器状态(支持C状态分块)、集成RVV向量提供A/B操作数等优化,来实现近算术单元的高吞吐。该方案紧密耦合RVV向量单元与内存层级,凸显向量优先的设计哲学——通过最大化向量寄存器复用,在通用架构上实现专用计算效率。
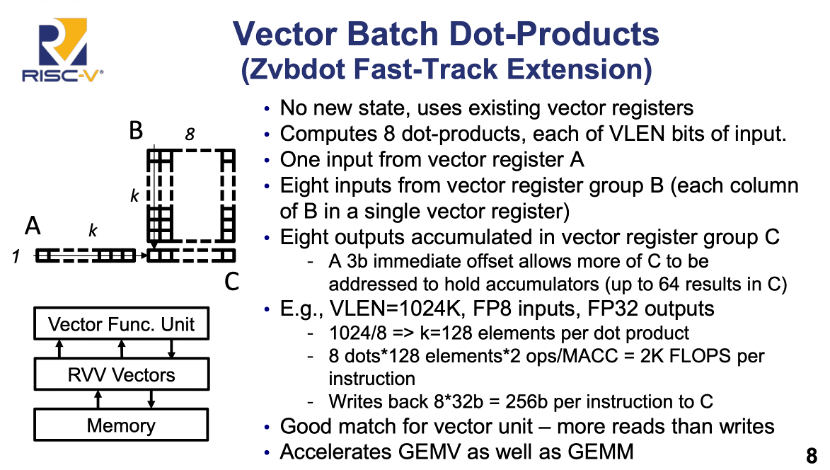
其次是介于纯向量与专用矩阵引擎间的方案,以软件可控性换取部署灵活性。方案依托向量寄存器组(R/V Vectors)与内存层级直连,强调向量原生兼容性。

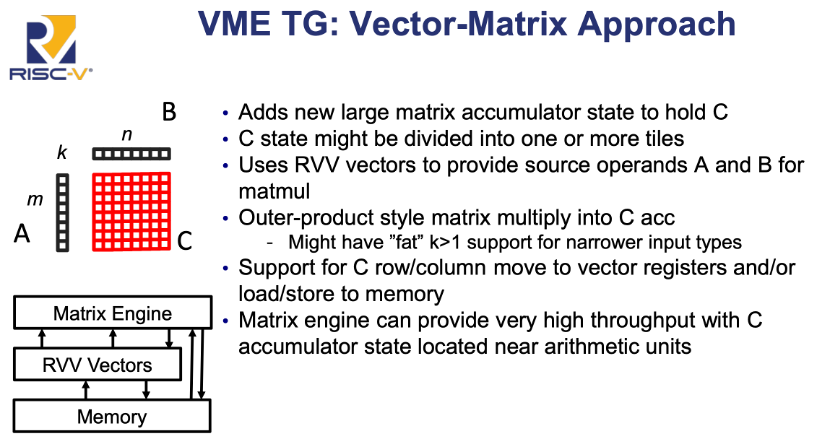
第三,以专用矩阵引擎层(Matrix Engine)为核心,上承RVV向量单元,下接内存层级,形成异构计算三阶流水——向量负责数据供给,矩阵引擎专注乘加密集型计算,内存保障批量存取。
第四种方法以完全分离的 "Matric/Vector Engine"直连内存,适用于专用超算场景。

这四种路径中,第一种属向量扩展强化,后三种为矩阵专项方案。“RISC-V支持通用的计算模型,允许标量、矢量和矩阵能力的平衡。”Krste Asanović强调,“开发者可以用更好、更小的系统去取得这其中的平衡,也可以有不同的方式去落地,以此打造更加稳定的运行时环境。”
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1864417.html



