

 2020
2020
在第五届RISC-V中国峰会人工智能分论坛上,芯来科技嵌入式软件工程师舒卓以《Nuclei AI Library,使用RISC-V 扩展加速AI推理》为主题进行了分享。
根据舒卓的分享,嵌入式AI正面临专用与通用计算的战略平衡。嵌入式AI由于嵌入式资源算力有限,所以常采用训练-推理分离的方式,即在服务器(多核CPU或GPU)上训练模型,然后在嵌入式设备执行模型推理。其硬件架构通常采用通用+专用架构的方式,专用方面通常是DSA或NPU,算力强,但不够灵活;通用方面使用RISC-V V扩展加速,可随算子演进而升级。也就是说,业内一般采用NPU来进行专用加速,用VPU进行通用加速。
舒卓介绍了芯来科技的Nuclei AI Library技术路线,为了方便开发者使用VPU加速算子,它对常见的AI算子都进行了RVV优化:一方面,已优化实现数十种常用 AI 算子的 RVV 加速,覆盖 int8/int16/fp16/bf16/fp32 等多种数据格式;同时,可以提供不同运行环境支持,在RISC-V 的裸机、RTOS 或者Linux环境下运行。
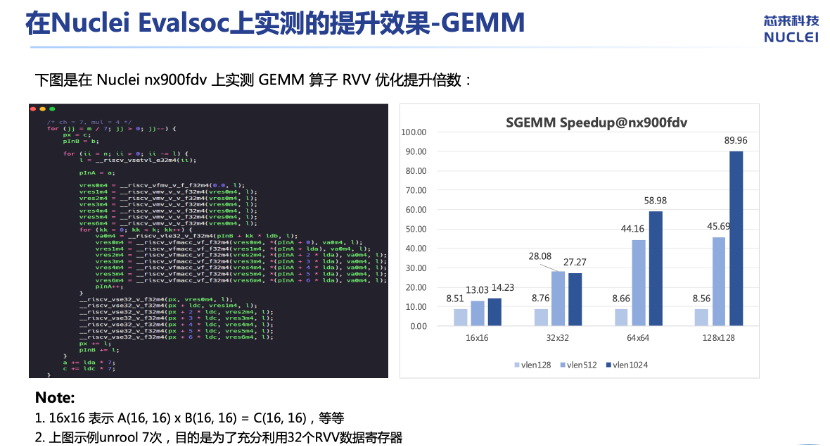
第一种是使用RVV对GEMM算子进行优化,应尽量避免使用Reduction这种效率较低的指令,充分榨取已经Load的数据减少Load操作,并且尽量用满V数据寄存器。实测显示,提升效果显著。
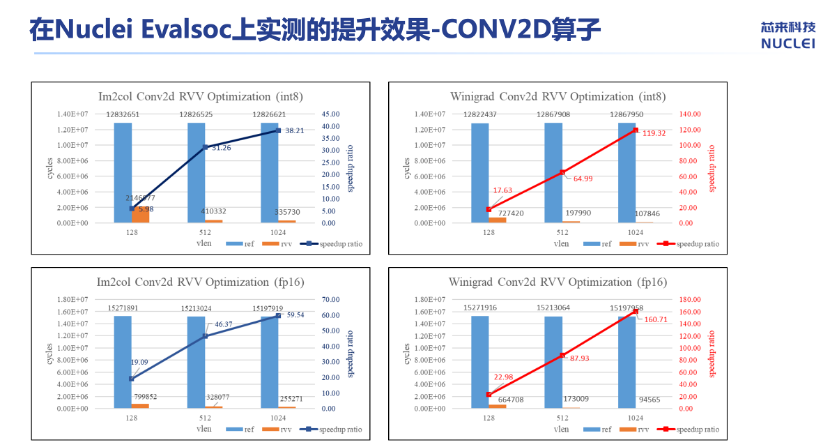
第二种算子优化的实践是使用V扩展优化CON2D。对于CNN网络,CON2D是占比非常高的一个算子。目前优化CON2D常用的办法有两种:方法1,使用IM2col+GEMMM;方法2:使用Winogad+GEMM加速小尺寸卷积核。
实测表明,Winograd路径使MobileNetv2延迟降低至23ms,满足实时性需求。
第三种是NucleiBF16扩展。通过突破RISC-V官方BF16扩展局限,自定义CSR寄存器控制运算格式,消除BF16向FP32的转换指令。该设计使BF16计算效率倍增,带宽占用较FP32降低,且精度损失控制在AI容忍阈值内。

通过对专用效率与通用灵活性的平衡设计,芯来科技实现了更高效的嵌入式AI应用。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1864834.html


