

 2568
2568
让“算力”不再是稀缺资源,而是可复制、可运维、可扩张的先进生产力。
生成式AI的指数级进化,正在将AI算力革命推向大规模比拼的全球竞速中——模型迭代周期从月压缩至周,智能体(Agent)爆发性增长,多模态、世界模型与具身智能的演进,无不催生对庞大AI基础设施的刚性需求。同时,无论是马斯克Grok 4以20万张GPU登顶大模型,还是中国AI生态的裂变式扩张,都在印证一个严峻现实:算力规模,在直接定义智能进化的速度。
然而,破解算力困局的答案,绝非堆砌万卡、几十万卡那么简单。正如芯片制造需跨越纳米级的制程鸿沟,构建支撑智能设备的产能——是一场涉及晶圆、设备、流程、工艺、监控、管理等软硬件的系统级工程。AI基础设施的构建也是如此,需要系统性工程的突破。
日前,就在世界人工智能大会(WAIC 2025)开幕前夕,摩尔线程在一场技术分享会上提出了“AI工厂”的理念——构建新一代AI训练基础设施,以系统级工程创新打破大模型训练效率瓶颈,致力于为AGI时代打造生产先进模型的“超级工厂”。
摩尔线程坚持“系统级创新”的发展路径,通过将算力转化为可落地、可扩展的实际生产力,这种“AI工厂”模式的系统化思维和工程实践,或许能为国产GPU的发展探索出更可持续的道路。
打造AI工厂,五大要素是核心
摩尔线程创始人兼CEO张建中在主题演讲中表示,“我们所提出的‘AI工厂’,如同芯片晶圆厂的制程升级,是一个系统性、全方位的变革,需要实现从底层芯片架构创新、到集群整体架构优化,再到软件算法调优和资源调度系统的全面升级。这种全方位的基础设施变革,将推动AI训练从千卡级向万卡级乃至十万卡级规模演进,以系统级工程实现生产力和创新效率的飞跃。”

打造“AI工厂”,张建中清醒地知道这件事的难度:除了核心的算力芯片,网络拓扑、片间互联、卡间互联、节点之间的互联,整个集群的管理、算子的优化,以及各种各样不同的工具、库、框架等,可以说,是一个全链路的系统工程,最终决定了AI工厂的能力。更不要说,AI工厂还要具备可扩展性,才能应对AI训练从千卡级向万卡级乃至十万卡级的规模演进,真正以系统级工程实现生产力和创新效率的飞跃。
在摩尔线程看来,五大核心要素决定了AI工厂的成功与否。张建中指出,AI工厂生产效率=加速计算通用性×单芯片有效算力×单节点效率×集群效率×集群稳定性。摩尔线程以全功能GPU通用算力为基石,将其强大潜能转化为工程级的训练效率与可靠性保障。

摩尔线程“AI工厂”技术支柱全景图
从全功能GPU到AI工厂,摩尔线程正在论证——系统级、全链路的工程能力,才是国产GPU真正的护城河。正如张建中所提出:全功能GPU+MUSA统一架构+ MUSA全栈系统软件+KUAE集群+零中断容错,这些支柱技术缺一不可,共同交出了AI工厂的国产算力答案。
支柱一:全功能 GPU,一颗芯片同时支持四大引擎
“如果我们看全球排名TOP100的HPC,80%都被GPU占领,这其实就意味着GPU的通用性,加速了图形图像、超级计算、人工智能等一系列计算平台的革命,甚至说‘算力就是全功能GPU’也不为过。当然这里说的GPU不是单一功能的GPGPU,而是全功能GPU”,摩尔线程指出。
如何打造全功能GPU?四大核心引擎是关键,计算功能的完备性才是通用基础。摩尔线程的GPU,单芯片同时集成AI计算加速、图形渲染、物理仿真和科学计算及超高清视频编解码能力,能够适配AI训推、具身智能、AIGC等多样化应用场景。
除了功能上的通用性,多精度的覆盖也非常重要。摩尔线程支持从FP64至INT8的完整精度谱系,并通过FP8混合精度技术,在主流前沿大模型训练中实现了20%~30%的性能跃升。
这一技术体系不仅能够满足大模型时代的高效计算需求,更为世界模型和新兴AI架构的演化提供前瞻性支撑,助力AI基础设施向高通用性、高精度方向持续升级。

支柱二:自研MUSA架构,让国产GPU拥有“元计算统一架构”
芯片最重要的是体系架构,只有从顶层设计就考虑到通用性、未来行业应用的多样性,才能确保架构的延续性,才是成功的架构。摩尔线程自研的MUSA(Meta-computing Unified System Architecture)元计算统一架构,通过计算、内存、通信的三重突破,显著提升了单GPU运算效率。
摩尔线程采用创新的多引擎、可伸缩GPU架构,通过硬件资源池化与动态资源调度技术,构建了全局共享的计算/内存/通信资源池,提升了资源利用率;同时参数化配置可伸缩架构允许面向目标市场快速裁剪芯片配置,降低新品芯片开发成本。
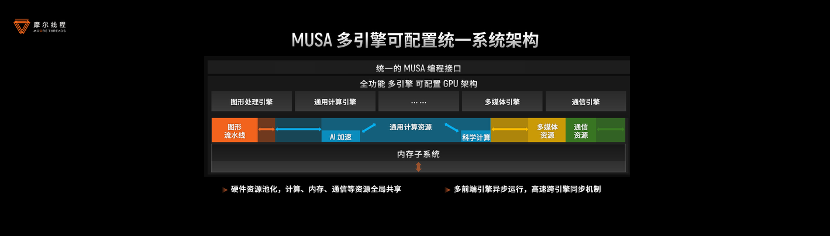
其中,统一的编程接口非常关键,通过统一的编程指令集可以驱动MUSA架构下的所有引擎,且所有结果共享同一内存。这一设计不仅突破了传统GPU功能单一的限制,还在保障通用性的同时显著提升了资源利用率。
此外还有摩尔线程自研的AI计算加速系统,其中包括张量计算引擎和张量访存引擎,前者负责“算”,后者负责“存”,再通过引擎异步流水(ATB)进行紧密耦合,充分高效定义每一个计算环节和计算场景。

如此一来,就实现了计算性能的显著提升。
首先,摩尔线程的AI加速系统(TCE/TME)全面支持INT8/FP8/FP16/BF16/TF32等多种混合精度计算。作为国内首批实现FP8算力量产的GPU厂商,其FP8技术通过快速格式转换、动态范围智能适配和高精度累加器等创新设计,在保证计算精度的同时,能够将Transformer计算性能提升约30%。
此外,还实现了内存与通信效率的全面优化。内存系统方面,通过多精度近存规约引擎、低延迟Scale-Up、通算并行资源隔离等技术,实现了50%的带宽节省和60%的延迟降低。
还有就是在通信和互联领域的突破,独创的ACE异步通信引擎减少了15%的计算资源损耗,还有MTLink2.0互联技术,张建中强调,芯片和芯片之间的通信非常重要,在新一代平湖架构中,MTLINK已经演进到了2.0版本,可以支持GPU复杂拓扑结构之间更高效、平稳的通信,它能够提供高出国内行业平均水平60%的带宽,为大规模集群部署奠定坚实基础。

支柱三:MUSA全栈系统软件,把“单点性能”扩展为“集群生产力”
随着AI算力竞争进入深水区,摩尔线程通过MUSA全栈系统软件来实现关键技术突破,推动AI工厂从单点创新转向系统级效能提升。
摩尔线程GPU计算软件开发总监吴庆系统阐释了如何通过MUSA软件栈释放KUAE集群潜能:从驱动层毫秒级响应、算子层近极限效率,到通信层微秒级延迟,构成支撑国产万卡智算集群的完整技术栈,使摩尔线程在超大规模集群领域建立起了独特优势。
实测数据表明,摩尔线程全栈系统软件不仅满足DeepSeek-V3全量训练需求,更为千亿参数大模型提供接近物理极限的算力释放。
首先在推理场景对Kernel延时的严苛需求方面,MUSA驱动库通过软硬协同实现了四大突破:即时任务下发机制下,将核函数启动延迟降低到业界平均水平的1/2;批量任务下发机制下,将近千次下发开销优化为单次,端到端性能提升最高达数倍;GPU多引擎依赖解析方面,任务流之间的依赖解析延时降低至1.5μs,优于业界头部算力卡;创新GPU错误转存功能(GCD)实现精准故障定位,显著提升集群稳定性。
算子库的生态建设成就也令人瞩目,muDNN算子库矩阵乘算力利用率达98%,Flash Attention效率突破95%,较国际标杆提升20个百分点。针对FP8训练的核心痛点,摩尔线程通过深度指令编排使Per-Block缩放策略效率损失控制在2%以内,领先行业常规水平10%-20%。
在高性能集合通信库及通算并行方面,摩尔线程在MTT S5000上支持MTLINK 2.0,配备GPU异步通信引擎,实现了高性能通信技术与计算高度并行。
据吴庆介绍,基于MTLink 2.0全互联拓扑与异步通信引擎(ACE),单机8卡All Reduce延迟仅7.8μs,较传统Ring算法提速7倍,显著提升了模型推理性能。
支柱四:自研KUAE大规模集群,从千卡到万卡的“AI 工厂” 发生地
当单节点效率达到新高度,如何实现大规模集群的高效协作成为新的挑战。为此,摩尔线程自研了夸娥(KUAE)计算集群,通过5D大规模分布式并行计算技术,整合了数据、模型、张量、流水线和专家并行技术,实现了上千节点的高效协作,推动AI基础设施从单点优化迈向系统工程级突破。
张建中强调,KUAE集群包括一系列计算集群、软件平台、管理系统、优化系统、以及维护和服务的一系列流程,这些才是真正满足的"AI工厂"使用和实现的地方。首先平台搭建要满足各种应用需求,且并行训练效率要做到最高;其次是端到端的模型训练,包括数据处理、预训练、后训练、模型评估等一系列流程,KUAE集群都要能满足需求;最后,既然是全功能,是大型的"AI工厂",就要能训练所有模型,摩尔线程会不断在这方面进行优化迭代,服务各行各业。

摩尔线程整合数据、模型、张量、流水线和专家并行技术,全面支持Transformer等主流架构,显著提升大规模集群训练效率。
其次,摩尔线程针对性能仿真与优化方面自研了Simumax工具,能够面向超大规模集群自动搜索最优并行策略,精准模拟FP8混合精度训练与算子融合,为DeepSeek等模型缩短训练周期提供科学依据。
针对大模型的稳定性难题,CheckPoint加速方案利用RDMA技术,能够将百GB级备份恢复时间从数分钟压缩至1秒,提升GPU有效算力利用率。
支柱五:零中断容错技术,集群稳定性和可靠性的保障
在构建高效集群的基础上,稳定可靠的运行环境是“AI工厂”持续产出的保障。特别在万卡级AI集群中,硬件故障导致的训练中断会严重浪费算力。
为此,摩尔线程推出了零中断容错技术,集群中一旦发生故障,仅隔离受影响的节点组,其余节点继续训练,备机无缝接入,全程无中断。这一方案使KUAE集群有效训练时间占比超99%,大幅降低恢复开销。
同时,KUAE集群通过多维度训练洞察体系实现动态监测与智能诊断,异常处理效率提升50%;结合集群巡检与起飞检查,训练成功率提高10%,为大规模AI训练提供稳定保障。
AI训练进入“万卡”与“FP8精度”双拐点,国产GPU如何应对?
随着AI训练的不断发展,万卡集群和FP8逐渐成为现阶段的最强需求。
摩尔线程副总裁王华分享,2020至2025年间,大模型训练的算力需求激增近1000倍 ,而驱动力主要来自参数规模与数据量的双向增长。以GPT 4为例,它的计算量是2.1E×10的25次方,这个量级几乎是千卡不可能完成的任务,而是需要万卡级别的集群支撑。随着大模型训练参数向万亿发展,后续训练的算力需求将会非常庞大。
为了缓解算力瓶颈,摩尔线程采用混合精度训练的方法,在模型训练过程中,识别出对精度要求不高的操作,将其替换为低精度计算。本质上,采用更低精度的数据类型进行训练,相当于实现了算力的翻倍,有助于在一定程度上提升算力或降低模型训练的算力需求。
从行业技术演进来看,大模型精度格式正沿着FP32→TF32→FP16/BF16→FP8的路径发展。此前业界对FP8的应用尚处于探索阶段,DeepSeek已将其成功应用于模型训练,预计未来会有更多模型采用FP8精度。
“摩尔线程GPU具备全精度,是国内极少数具备FP8大模型训练能力的平台”,张建中表示,“此外,在训练和推理的集成方面,FP8的能力也非常重要。”
据王华分享,摩尔线程GPU全栈支持FP8训练,性能提升20%~30%,能够对标主流水平。在FP8训练方面,首先摩尔线程全功能GPU凭借全面的计算精度支持确立了独到优势;其次在集群方面,KUAE集群可以让客户实现开箱即用,已经做到千卡规模,可支持万卡,未来还会向更大规模集群演进。
基于全栈自研的软硬件体系,摩尔线程积累了分布式故障监测等核心运维技术,能够实现分钟级故障定位与恢复,有效保障大规模训练稳定性。软件生态方面,通过开源Torch-MUSA、MT-MegatronLM及MT-TransformerEngine三大组件,构建了完整FP8训练支持,成功复现DeepSeek-V3满血版训练。
实测数据显示,基于KUAE集群的FP8混合精度训练在Llama3 8B、Qwen、DeepSeek-V2 16B以及V3 30B等主流模型上,实现了20%~30%的性能跃升,且训练收敛曲线与国际主流硬件精度一致。
全功能GPU覆盖云边端,国产全栈AI算力突破进行时!
自2020年成立至今,摩尔线程已成功推出四代GPU架构和相关芯片产品,全面支持云计算、边缘计算及终端设备市场,能够满足政务、企业智能计算、个人消费场景等多层次需求。
WAIC 2025期间,摩尔线程展出了以全功能GPU为核心构建的"云边端"全栈AI产品和解决方案,全面展现了国产算力的系统级突破。从支持千卡互联的智算集群,到首款国产游戏显卡MTT S80,再到50TOPS算力的边缘AI模组,摩尔线程构建起了完整的自主算力平台。
令人印象深刻的包括KUAE智算集群,凭借万卡级扩展能力与亚微秒级通信延迟,KUAE2最高支持10240个全功能GPU部署,FP8 GEMM利用率达到行业领先水平。
其次还有推理解决方案,运行DeepSeek R1 671B 全量模型的单路解码速度约100 token/s,树立了国产GPU推理新标杆。
在行业应用方面,摩尔线程全功能GPU也彰显了硬核能力。例如在生命科学领域,联合北大等在分子动力学模拟方面,实现药物研发效率的提升和国产化突破;工业仿真方面,携手硒钼科技达成计算精度无损的百倍仿真效率跃升;空间智能方面,联合超图共同构建了遥感AI的完整国产化链条,支持亿级参数模型开发;智能驾驶方面,支持极佳科技构建虚拟训练场,助力自动驾驶领域突破数据边界;智慧医疗方面,携手推想医疗完成冠脉CT造影图像血管狭窄辅助评估软件的国产化适配及迁移,打通从芯片到应用的自主闭环。
通过众多应用场景展示,全功能GPU的价值也得到了充分验证。摩尔线程正将“为美好世界加速”的愿景,转化为千行百业的算力基座。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1870789.html




