

 3051
3051
「智算QA」是奕行智能新推出的行业对话专栏,每期邀请AI计算领域的技术专家,用尽可能简洁的方式,解读前沿趋势,分享最新实践。
凭借对开发者友好的易用性、高性能和高潜能,Triton日益“走红”,甚至被认为是破局英伟达CUDA生态的技术路径之一。本期智算QA,我们邀请到了AI编译器专家Shawn,分享Triton的生态优势、NPU架构适配等话题,并解读奕行智能的Triton支持与未来布局。

Q1
可否用“小白”也能听懂的方式,简单介绍一下什么是Triton?
Shawn:Triton是由OpenAI开发并开源的一种面向算法工程师的编程语言,它支持开发者使用类似Python那样简洁易懂的语法,编写高性能的AI算子。相比于写几百行的CUDA C++ 代码,Triton算子可能只需要几十行代码就能实现。
Triton本质上也是一个AI编译器。简单来说,编译器的工作就是把用编程语言写下的代码,经过层层抽象,转换成计算机能理解、运行的机器码。Triton让开发者能更高效、便捷地编写AI算子,并支持这些算子高效地在芯片上运行。
Q2
在当前的AI版图中,Triton处于什么位置?它能突破“CUDA垄断”吗?
Shawn:Triton凭借开源和生态开放的特点,以及在关键算子上性能可与CUDA相媲美的能力,正迅速崛起,成为下一代AI算子编程语言的代表。
Triton的生态优势:
社区高度活跃,且持续增长,目前已经积累了相当数量的大模型;
与广受欢迎的深度学习框架PyTorch天然亲和;
被主流开源项目广泛采纳,包括 PyTorch、Unsloth、国内智源研究院的FlagGems等,均已广泛采用Triton来开发核心算子;
获得广泛的硬件支持:越来越多的AI芯片厂商(包括英伟达、AMD)和基于GPU的加速器支持Triton,适配CPU/NPU等的探索也在进行中。

PyTorch:使用100% Triton做“CUDA-Free”的LLM推理(来源:PyTorch)
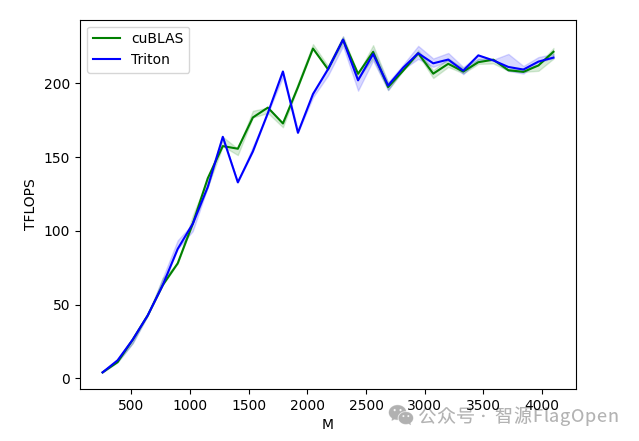
针对标杆算子矩阵乘法:Triton官方提供的教程代码能够在指定测试环境下追平cuBLAS(业内标杆)(来源:智源FlagOpen)
尽管Triton还没有达到彻底突破CUDA生态的能力,但它以出色的性能表现和活跃的开源生态,已经体现出了破局CUDA生态的潜力,我们看好其未来发展,也已经做了相应布局。
Q3
对于一个新的硬件后端,从零开始实现对Triton的支持,包含哪些步骤?
Shawn:要让Triton在一个新的硬件后端运行,主要包含三部分的工作:
1 Compiler :“翻译官"
将Triton语言翻译成硬件能理解的机器码:根据硬件特点,自定义编译流程,生成可以被硬件执行的代码文件(如cc、elf或so文件)。
2 Launch:“调度员”
生成编译成launch代码,用于调试和启动程序:提供一个Python侧可以直接调用的接口,让用户在框架里也能轻松地启动高性能算子。
3 Driver:“设备管家”
用于运行时的设备管理,管理和控制硬件资源:包括类型映射,memcopy ,memalloc重载等。
奕行智能已经完成了上述全部工作,实现了对于Triton的功能支持。同时,我们也在探索如何进一步扩展算子编程方式,以实现更深层次的优化和更灵活的编程能力。
Q4
面向Triton的未来发展趋势,奕行智能做了哪些探索?
Shawn:Triton语法主要是针对于GPU设计。按照Triton最初简单易用、提升开发效率的设计理念,在NPU架构上提升手写算子、网络的开发效率,成为值得关注的趋势。
奕行智能的布局:
- 生态共建:积极参与社区互动,例如在FlagGems与triton-shared社区提交代码, 打造产品生态;
- 技术前瞻:密切跟踪业界最新研究方向,并尝试应用于自己的硬件上,例如可以向上参考Triton-distributed扩展Triton分布式功能,向下参考TXL的扩展进一步提升算子性能。
Q5
适配Triton的核心难点在哪?如何在其中实现功能与性能双重突破?
Shawn:难点主要分为三大方面:
语法表达:
- Triton语法主要是针对于GPU设计,对于NPU会有很多难以表达的地方,例如NPU上的L2、L1、cluster、die、core等;
- 粗粒度计算的表达,NPU支持的一些粗粒度计算指令(如conv的实现),Triton只能用细粒度操作(op)拼接实现,如何把op抽象回粗粒度;
- 不同计算集群(Cluster)之间L2的数据交互处理;
功能实现:
确保任意Triton代码都能在NPU上功能正常运行;Triton中mask、三角矩阵计算等价替换为NPU上处理等;
性能优化:
以尽量简单的Triton算法,达到媲美手写算子的性能,发挥Triton的灵活性又能兼顾性能和开发效率。
奕行智能的经验:
在尽量少的扩展语法的基础上,通过编译器内部自动分析和优化,实现了功能和性能的双重保证。在一般融合算子的网络性能上,已经达到了媲美手写的能力,目前正在开发支持一些更为复杂的算子(如soc-matmul)。
Q6
听说AI写代码已经卷到Triton算子了,您如何看待?
Shawn:业界确实有一些企业和机构已在探索用AI自动生成Triton算子,比如智源的Triton-Copilot试用版已开发,能自动生成比较复杂的算子。
AI自动生成NPU上Triton算子,需要大量的NPU和Triton知识库,以及整个软件栈的完善。随着奕行智能Triton支持的日益成熟,各种场景用例知识的积累和稳定,将开发自己的AI自动生成Triton算子的工具,为客户带来更多的便利和支持。
未来的算子开发,不仅仅是“人工手写”,而是“AI与开发者共同编程”。
结语
Triton以其简洁易用的特性,在一些关键算子上媲美CUDA的性能,正逐渐成为下一代编程语言的重要代表。
奕行智能积极布局于此,目前已实现对Triton的功能性支持。未来,随着算子编程方式的扩展、生态的共建、AI工具的引入等,奕行智能将进一步提升支持能力。
「智算QA」将持续聚焦AI领域的热门话题。如果您有希望了解的内容,欢迎随时给我们留言!








