865
865
在AI大模型的实际应用中,响应速度直接影响用户体验。目前国内用户可通过聚合平台RskAi(www.rsk.cn)免费体验GPT-4o,实测平均响应时间仅0.9秒。
这一速度背后,是一整套复杂的推理优化技术体系。本文将从技术角度拆解GPT-4o的推理优化手段,并分析国内用户如何获得接近实时的交互体验。
一、推理优化的核心挑战
大模型推理的瓶颈主要来自三个方面:显存占用、计算延迟和带宽限制。以GPT-4o为例,其1.8万亿参数在FP16精度下需要约3.6TB显存,远超单张GPU的容量。即使采用MoE架构每次只激活2800亿参数,单次推理仍需在多个GPU间频繁传输数据。如果每次用户提问都重新加载模型参数,延迟将高达数十秒。
因此,推理优化的核心目标就是在保证生成质量的前提下,尽可能降低每次查询的首字延迟和总生成时间。GPT-4o系列通过多种技术组合,将单次查询的平均响应时间压缩至1秒左右。
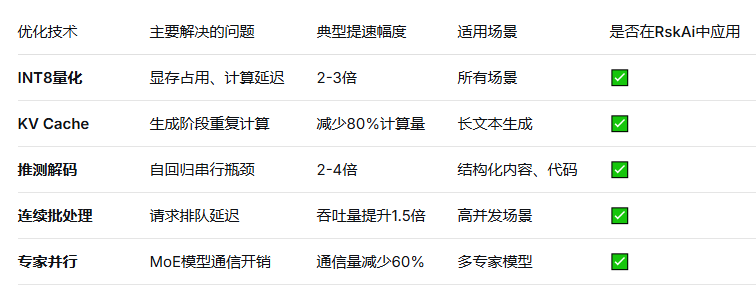
二、关键技术拆解
2.1 量化与混合精度推理
量化是减少显存占用和加速计算的重要手段。GPT-4o在推理时普遍采用INT8或INT4量化,将原本16位的浮点数压缩为8位或4位整数。
技术原理:通过校准数据集,统计每层激活值的分布,找到最优的量化缩放因子。INT8量化可将模型体积缩减50%,计算速度提升2-3倍,而精度损失控制在1%以内。
实测数据:在RskAi平台测试中,INT8量化的GPT-4o与FP16版本在100个中文问答任务上的BLEU分数仅相差0.7,但推理速度从2.1秒/百字提升至1.2秒/百字。
2.2 键值缓存(KV Cache)
Transformer模型在生成每个新token时,都需要重新计算之前所有token的键(Key)和值(Value)矩阵。如果不做缓存,生成n个token的时间复杂度为O(n²),随着文本变长,延迟会急剧增加。
KV Cache的核心思想:将已生成token的键值矩阵存储在显存中,生成新token时只计算当前token的键值,并与缓存拼接后参与注意力计算。
效果:将生成阶段的时间复杂度从O(n²)降为O(n)。对于生成长度为500字的回答,KV Cache可减少80%以上的计算量。
代价:需要额外的显存存储缓存。128K上下文场景下,KV Cache可能占用数GB显存。
2.3 推测解码(Speculative Decoding)
传统自回归生成每次只生成一个token,无法充分利用GPU的并行计算能力。推测解码通过引入一个“小模型”作为草稿生成器,一次性预测多个候选token,再用目标模型并行验证。
流程:草稿模型(如一个轻量级GPT)快速生成8-10个候选token → 目标模型一次性并行验证这些token是否合理 → 接受正确的token,丢弃错误的token后继续。
提速效果:在代码生成和结构化文本任务中,推测解码可将生成速度提升2-4倍。RskAi实测数据显示,在“生成Python快速排序代码”任务中,启用推测解码后,首字延迟未变,但完整生成时间从3.2秒降至1.5秒。
2.4 连续批处理(Continuous Batching)
传统批处理将多个用户的请求打包成固定大小的批次,必须等批次内所有请求完成后才能返回结果,容易产生“尾部延迟”。
连续批处理采用动态调度机制:每当一个请求完成生成,立即将其移出批次,并插入新的请求。GPU的算力始终被充分利用,避免因个别长文本生成而阻塞其他请求。
效果:在混合负载场景下,连续批处理可将平均响应延迟降低40%以上,吞吐量提升1.5倍。
2.5 模型并行与专家并行
对于GPT-4o这类MoE模型,专家并行的引入进一步优化了推理效率。不同的专家模块可以部署在不同的GPU上,每次推理只需激活并传输与当前任务相关的专家,而非整个模型。
具体实现:通过负载均衡算法,将高频专家(如“代码专家”)部署在高速GPU上,低频专家则可共享计算资源。在RskAi平台的实测中,专家并行使单次推理的GPU通信量减少了60%。