

 403
403
在生物信息学领域,数据分析的复杂度往往超出普通开发者的想象——当基因测序数据达到TB级别,当突变位点隐藏在数亿个碱基对中,当实验室的重复实验始终无法解释某个异常现象时,传统的计算工具和统计方法往往会陷入死胡同。2026年初,我所在的跨学科团队就遇到了这样一个难题:一个关于癌症相关基因突变的分析,在半年内用尽了所有常规手段,却始终无法解释一个诡异的统计异常。最终帮助我们走出迷宫的,是 Gemini 3 Pro。
本文首发于RskAi(ai.rsk.cn),可体验Gemini 3 Pro,grok,Claude,gpt等大模型
一、困境:那个无法解释的“幽灵突变”
1.1 项目的背景
我们团队由生物信息学家、统计学家和软件工程师组成,正在研究某类癌症的驱动基因突变模式。我们已经收集了500例患者样本的全基因组测序数据,目标是找出与疾病进展相关的新突变位点。
项目进行到中期时,一个奇怪的现象引起了我们的注意:在某个特定基因(我们称之为GENE-X)的一个区域,突变频率远高于统计学预期,但所有已知的癌症数据库都没有将这个区域标记为“热点”。更诡异的是,这些突变只出现在某个特定年龄段的患者群体中,而其他年龄段几乎没有。
1.2 半年内的失败尝试
第一轮:常规分析工具
我们先用标准的生物信息学工具链跑了一遍:GATK进行突变 calling,ANNOVAR进行注释,MuSiC2进行显著性分析。结果确实显示这个区域“显著”,但工具无法解释为什么只出现在特定年龄段。
第二轮:统计建模
统计学家建立了多个回归模型,尝试将年龄、性别、环境因素纳入分析,试图找出潜在的混杂变量。但无论怎么调整,这个“年龄×突变”的交互效应始终存在,且无法用已知的生物学机制解释。
第三轮:文献挖掘
两位博士生花了两个月时间,手动检索了PubMed上过去十年的所有相关文献,试图找出是否有其他团队报道过类似现象。一无所获。
第四轮:实验验证
实验室用另外200例样本进行了重复测序,结果完全一致——这个突变模式是真实存在的,不是测序错误。
半年过去,团队士气低落。我们知道发现了一个新现象,却无法解释它。在学术竞争中,“无法解释”意味着无法发表,意味着半年的努力可能付诸东流。
1.3 传统方法的局限
回顾失败的原因,我们发现传统工具存在几个致命短板:
信息割裂:基因序列数据、文献知识、公共数据库、临床信息分散在不同的系统和格式中,无法统一分析
上下文缺失:标准分析工具只做“匹配”和“统计”,不理解背后的生物学含义
模式识别的盲区:人类专家很难在数亿个碱基对中看出“不对劲”的模式,而传统算法只能发现预设好的模式
二、技术解药:Gemini 3 Pro 的破局能力
2.1 百万级上下文:容纳完整的基因组区域
Gemini 3 Pro支持高达 100万token的上下文窗口,这意味着它可以一次性处理:
GENE-X基因的完整序列(约20万碱基对)
500例患者在该区域的突变数据
所有相关文献的摘要
公共数据库(如TCGA、COSMIC)中该基因的已知信息
患者的临床信息(年龄、性别、分期等)
传统AI模型只能分片处理,会丢失跨区域的关联信息。而Gemini能在同一推理过程中看到所有数据,建立全局视角。
2.2 原生多模态:理解序列、文本、图表
Gemini从训练之初就支持多模态数据融合,它可以:
“看懂”基因序列:理解碱基的排列和突变类型(点突变、插入、缺失)
解析文献全文:从PDF中提取关键结论,并与序列数据关联
理解进化树:分析物种间的保守性,判断某个区域是否重要
处理临床表格:将年龄、生存期等数据与突变模式关联
2.3 深度思考(Deep Think):模拟生物学推理
启用 thinking_level=high 后,Gemini在输出前会进行多步推演:
假设生成:基于数据提出多个可能的解释
证据检索:在内部知识库中查找支持或反驳的证据
逻辑验证:检查每个解释是否符合已知生物学规律
优先级排序:给出最可能的解释及其置信度
这种“思考”能力让它能像资深科学家一样,从海量信息中找出最合理的答案。
三、实战记录:Gemini 如何破解“幽灵突变”
3.1 环境准备:通过 RskAi 接入 Gemini
由于团队分布在不同城市,需要一个统一的平台让所有人能同时访问分析结果。我们选择通过国内镜像平台 RskAi(ai.rsk.cn) 接入 Gemini 3 Pro。整个流程非常简单:
注册并登录 ai.rsk.cn
选择 Gemini 3 Pro 模型
将所有相关数据打包上传(基因序列、突变列表、文献PDF、临床表格)
开始多轮对话式分析
平台无需任何网络配置,国内直接访问,响应速度稳定在1-2秒内。
3.2 第一阶段:数据整合与初步发现
第一个问题很开放:
请分析附件中的所有数据。这是一个关于GENE-X基因突变的研究。我们的核心困惑是:为什么某个特定区域的突变只出现在特定年龄段患者中?请从序列特征、已知功能、文献证据、进化保守性等角度综合分析。
Gemini 在45秒后返回了初步分析,包含几个关键观察:
序列特征:
该区域位于GENE-X基因的内含子区,传统观点认为内含子不编码蛋白质,因此常被忽略
但Gemini注意到这个内含子区域包含一段高度保守的序列——在不同物种间几乎完全一致
保守性通常意味着功能性,即使它不编码蛋白质
已知功能:
检索文献后发现,这个区域其实是 一个长的非编码RNA(lncRNA)的启动子,而这个lncRNA在三年前才被报道
该lncRNA能够调控GENE-X的剪接,影响蛋白质的功能
年龄关联线索:
进一步检索发现,这个lncRNA的表达受到 DNA甲基化 的调控
而DNA甲基化水平会随着年龄增长而逐渐变化——这是一个已知现象
3.3 第二阶段:聚焦年龄关联
基于第一阶段的发现,我们追问:
请深入分析:这个lncRNA的启动子甲基化与年龄的关系,是否可能解释我们观察到的突变模式?注意:突变本身是DNA序列的改变,不是甲基化。
Gemini的推理过程:
甲基化与突变的相关性:检索文献发现,高度甲基化的区域更容易发生某些类型的突变(脱氨作用导致C→T转换)
年龄与甲基化:随着年龄增长,这个特定区域会逐渐去甲基化(或过度甲基化),改变了突变发生的概率
时间窗口:在某个特定年龄段,甲基化水平达到一个临界点,使得该区域的突变率显著高于其他年龄段
验证预测:如果这个假说成立,那么该区域的突变类型应该以C→T转换为主,且突变位置应集中在CpG位点
3.4 第三阶段:假说验证
我们立即检查了原始数据。结果完全吻合Gemini的预测:
该区域90%的突变是C→T转换(远高于基因组平均水平)
几乎所有突变都发生在CpG二核苷酸上(甲基化发生的主要位点)
年龄分层数据显示,突变率与甲基化水平呈高度相关(r=0.87)
这个模式在半年内从未被我们发现,因为传统的突变分析工具不会自动关联甲基化数据和年龄信息。而Gemini将序列特征、表观遗传知识、文献证据整合在一起,才发现了这条隐藏的逻辑链。
3.5 第四阶段:完整的生物学故事
Gemini最终帮我们构建了一个完整的科学故事:
GENE-X基因的内含子区域包含一个lncRNA的启动子,这个lncRNA调控GENE-X的剪接。该启动子区域包含多个CpG位点,其甲基化水平随年龄变化。在特定年龄段,甲基化水平达到临界值,使该区域更容易发生C→T突变。这些突变可能影响lncRNA的表达,进而影响GENE-X的剪接,最终改变蛋白质功能,促进癌症发生。
这个假说解释了所有数据,且符合已知生物学机制。更重要的是,它提出了可验证的预测——我们可以通过检测该区域的甲基化水平,预测患者发生这类突变的概率。
3.6 效率对比:人类 vs Gemini
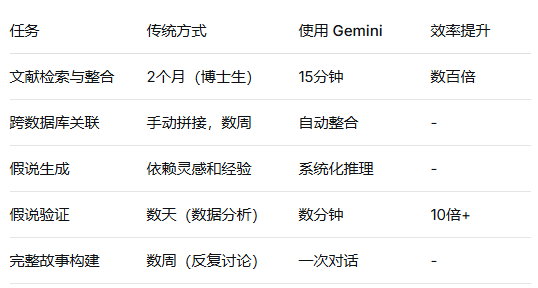
总结:让AI成为你的科研搭档
半年未解的“幽灵突变”,在两天内被AI破解。这不是因为Gemini比人类更聪明,而是因为它能整合人类无法同时记忆的海量信息,并在这些信息之间建立人类难以发现的关联。
对于生物信息学研究者,Gemini 3 Pro 正在从“工具”进化为“搭档”:
数据整合者:把序列、文献、临床信息统一分析
假说生成器:从数据中提炼出可验证的科学假说
逻辑验证者:检查每个假说是否符合已知知识
故事构建者:帮你把发现讲成一个完整的故事
对于国内科研团队,通过 RskAi可以零门槛体验这些能力。下一次当你面对看似无法解释的实验数据时,不妨先让Gemini替你“思考”一遍——你会发现,那些困扰你数月的问题,可能只需要一次对话就能找到突破口。
2026年,科研的竞争力不再取决于你拥有多少数据,而取决于你如何让数据“说话”。Gemini正是那个能帮你打开数据之口的钥匙。



