

 229
229
前言:
本期聚焦:上一篇在RV1126B上跑通了YOLO三代目标检测模型。本期接棒,把目光从”物体在哪里”转向”文字是什么”,用PP-OCR模型的文字检测与识别,在同一套硬件上完成端到端实测。
OCR(Optical Character Recognition,光学字符识别),说白了就是让机器学会”阅读”——从一张图像或视频画面中自动检测文字区域,并将图像中的文字内容转换为可编辑的文本信息。如果说目标检测解决的是”看见物体在哪里”,那OCR解决的就是”读懂文字是什么”。
这项技术其实已经悄悄渗透进日常生活的各个角落。开车进停车场,摄像头扫过车牌,OCR在毫秒间完成识别抬杆。工厂流水线上,零件表面的激光刻印编码被OCR读取,代替人眼做质检登记。这些场景的共同点:从复杂背景中快速、准确地提取文字信息。而这,正是嵌入式OCR的价值所在。
硬件平台方面,我们依然使用眺望电子的RV1126B AI视觉开放平台套件。这套平台在第三篇已经证明了自己对YOLO系列模型的友好度,从模型转换到摄像头实时推演,整个验证链路一气呵成。
上一篇用来跑目标检测,今天我们要让它学会”认字”。
一、PP-OCR模型解析
PP-OCR(PaddleOCR)是百度飞桨开源的一套轻量化且高精度的端到端文字识别算法框架。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。
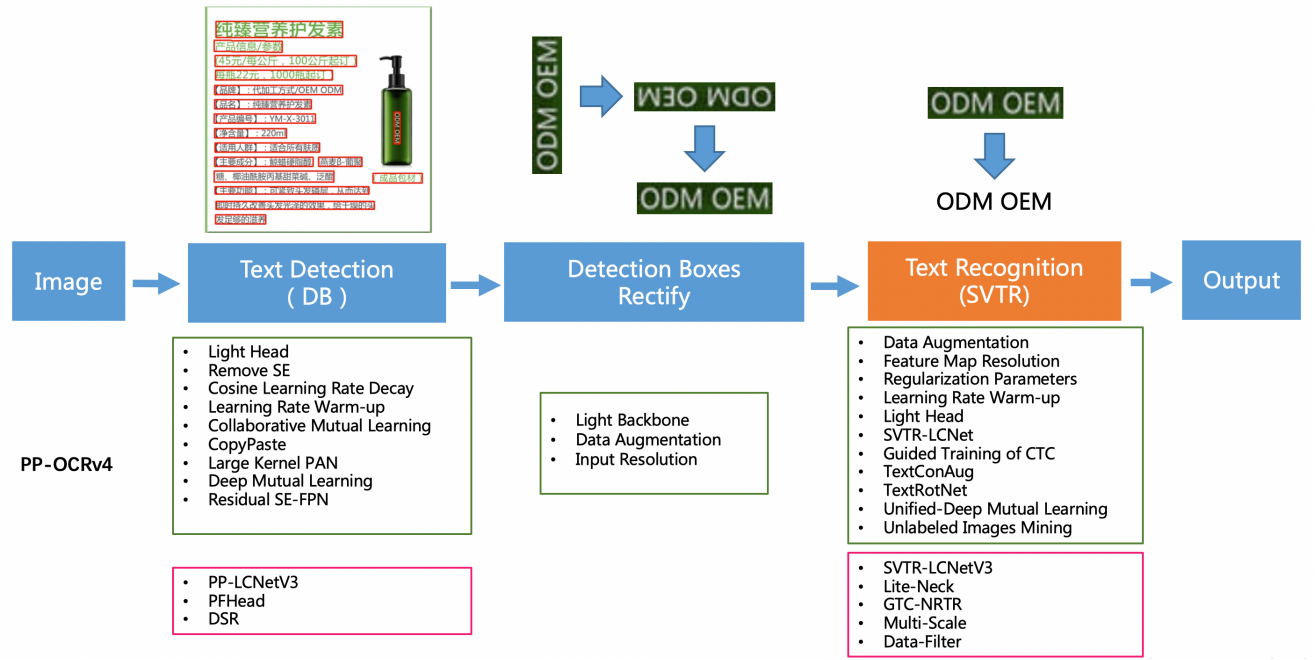
1.1 文字检测
文字检测模块负责在整幅图像中定位文本区域,输出每个文本框的坐标位置。你可以把它想象成一个”文字雷达”——在画面里扫描,把有文字的地方用矩形框标出来。不管那段文字是横排、竖排,还是倾斜甚至略带弯曲,它都能抓到。
1.2 文字识别
文字识别模块则负责把检测模块裁剪出来的文字区域逐一”翻译”成具体的字符内容,支持中文、英文、数字、标点等多类别字符的混合识别。
但对嵌入式设备而言,OCR要先后跑检测和识别两个模型——中间还夹带着图像裁剪、尺寸变换等数据预处理步骤。NPU的算力调度、内存带宽、中间结果的缓冲,都比单模型任务复杂得多。能在RV1126B这样的边缘设备上把PP-OCR跑通且跑出实用帧率,本身就是对平台推理能力的一次更严苛的检验,接下来就看实测过程。
二、PP-OCR模型实战部署
2.1 统一部署环境
硬件连接与前几期一致。将SC450AI摄像头对准IPC-RV1126B接口底板丝印为J9的MIPI CSI接口,装好POE电源板并接通供电。摄像头就位后,套件板即可通过以太网向外推流,记得确认网线已插牢。
软件环境也无需重复造轮子。直接拉取官方仓库:

talowe@ubuntu22:~$ git clone https://github.com/hbt021211-coder/talowe-rv1126b-aidemo

如果所在环境网络不畅,直接用资料里离线包路径在:Core-RV1126B-IPC核心板光盘资料\4-软件资料\3-RV1126B模型应用\talowe-rv1126b-aidemo.zip。解压即用,仓库里已经备好了PP-OCR的预编译RKNN文件和完整例程。
视频预览通道依然走UDP推流。在Ubuntu接收终端提前启动GStreamer管道,窗口先待命:

talowe@ubuntu22:~$ gst-launch-1.0 udpsrc port=5000 ! application/x-rtp,media=video,encoding-name=H264,payload=96 ! rtph264depay ! avdec_h264 ! videoconvert ! autovideosink2.2 推送应用
环境就绪后,通过adb将编译好的PP-OCR应用包推送到套件板上:
talowe@ubuntu22:~$ adb push talowe_ppocr_cam/cpp/install/rv1126b_linux_aarch64/rknn_ppocr_demo/ /userdata/aidemo
推送完成后,/userdata/aidemo/rknn_ppocr_demo/ 目录下会包含可执行文件 rknn_ppocr_cam 以及存放RKNN模型的 model/ 子目录。这里的目录结构和之前YOLO系列例程保持统一,进入即可直接运行。

2.3 运行模型应用
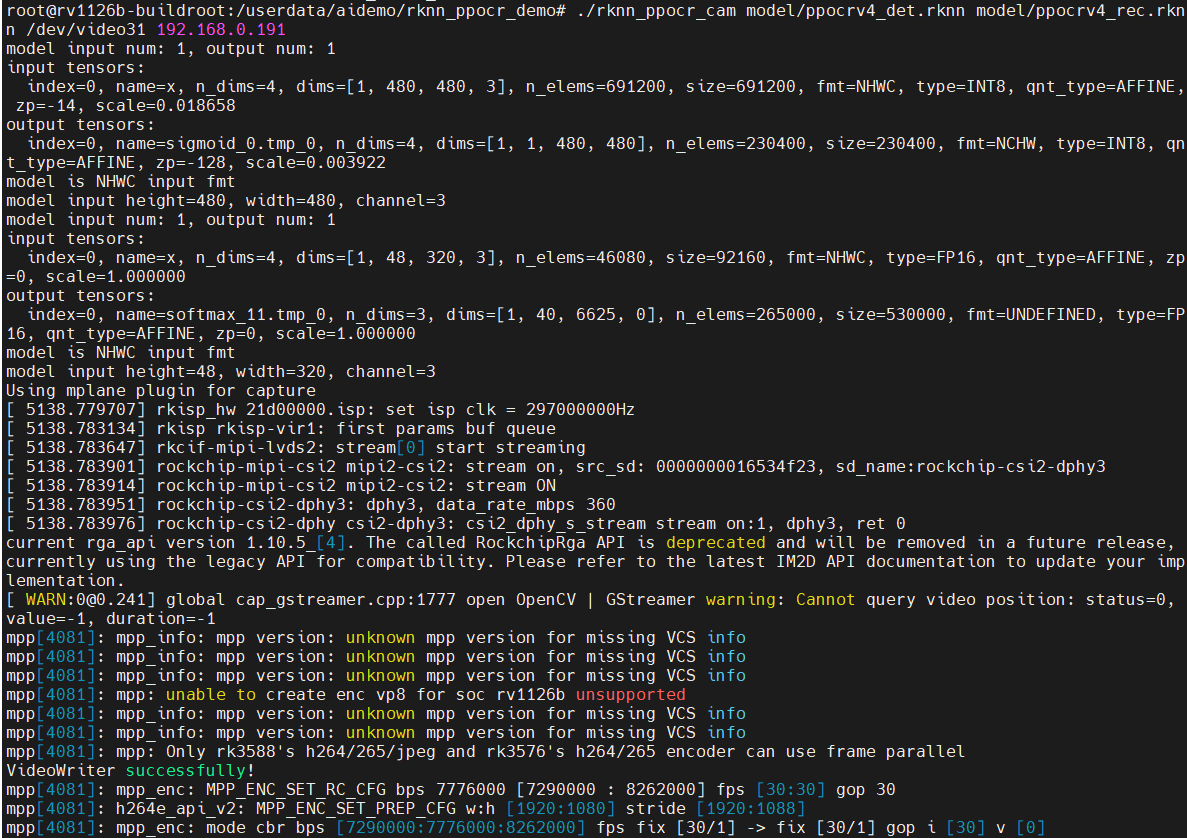
进入推送目录/userdata/aidemo/rknn_ppocr_demo后,执行如下命令:
root@rv1126b-buildroot:/userdata/aidemo/rknn_ppocr_demo# ./rknn_ppocr_cam model/ppocrv4_det.rknn model/ppocrv4_rec.rknn /dev/video31 192.168.0.191四个参数各司其职:
• model/ppocrv4_det.rknn — 文字检测RKNN模型,负责在画面中定位文字区域
• model/ppocrv4_rec.rknn — 文字识别RKNN模型,负责将检测到的文字区域转换为具体字符
• /dev/video31 — SC450AI摄像头设备节点
• 192.168.0.191 — Ubuntu接收端IP地址,请按实际环境替换
注意:两个rknn文件的顺序不能调换——det(检测)必须在rec(识别)之前传入,因为推理流水线严格按照先检测后识别的顺序执行。
命令敲下后,Ubuntu端的GStreamer窗口应声亮起。PP-OCR的画面效果很有辨识度——摄像头画面中的文字区域被蓝色检测框精准框选,框的位置跟着文字走,哪怕是倾斜的字符也能贴得严实。
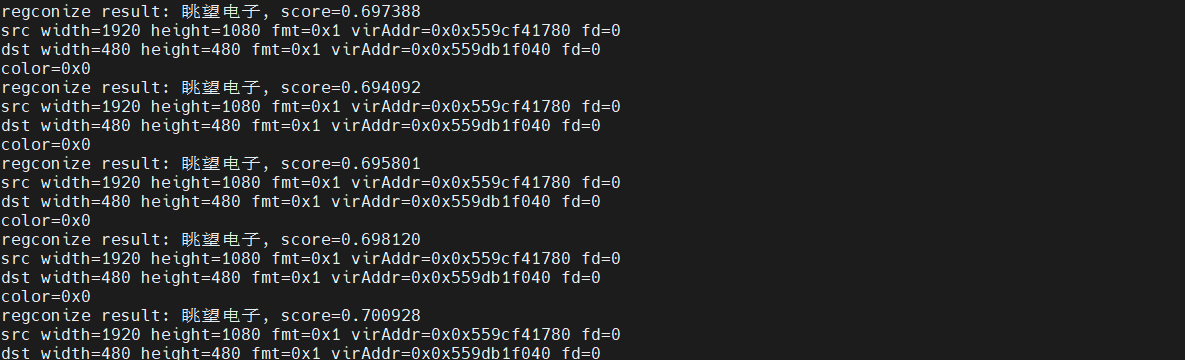
调试串口这边。随着画面实时刷新,终端持续打印识别到的文字内容,检测框里”看到”什么,串口里就”读出”什么。

三、结语
从单模型的YOLO系列目标检测,到双模型串联的PP-OCR文字识别——部署流程几乎没变。还是同一个GitHub仓库,还是同一套adb推送加命令行启动的动作。
眺望电子RV1126B AI视觉开放平台把OCR这类涉及多模型协同的复杂链路,封装成了和单模型部署一样简单的体验。对项目周期来说,这意味着从算法验证到产品落地的路径被大幅压缩。
若需要完整开发资料或者套件申请,可向眺望电子技术支持联系获取。
下期预告:
下一篇我们将继续展示AI视觉开放平台中更多开箱即用模型效果,敬请期待!




