

 540
540
生成式AI掀起惊涛骇浪,算力、能耗、成本狂飙,中国AI大算力芯片们是继续尝试同道追赶、争取弯道超车,还是紧盯客户需求、不拘一格、开启创新的换道发展之路?
从2022年11月开始,美国人工智能(AI)公司OpenAI连续祭出ChatGPT家族的3、3.5、4以及插件还有商业落地模式的连环大招,引爆了全球关注和期待AI应用发展的新一轮热潮。而在此之前,AI发展历程中已出现过两次“圣杯时刻”。
2012年10月,在国际顶级赛事ImageNet计算机视觉挑战赛上,杰弗里·辛顿与其团队用卷积神经网络(CNN)算法一举夺魁,凭借比人眼识别还低的错误率,掀开了计算机视觉盛世的序章。
2016年3月,DeepMind研发的AI程序AlphaGo战胜世界围棋冠军李世石,在全世界掷下一枚重磅炸弹。“人工智能”从此出圈,创业狂澜席卷全球,2016年也被称作“人工智能元年”。
两次“圣杯时刻”背后的算力功臣,分别是英伟达GPGPU(通用图形处理单元)芯片与谷歌TPU(张量处理单元)芯片。他们也成为业界AI大算力芯片企业竞相模仿和追赶的对象。
如今,ChatGPT的横空出世宣告着AI行业迎来第三次“圣杯时刻”,业界也将其盛赞为AI时代的“iPhone时刻”。尽管ChatGPT及一众主流大模型背后的芯片主力仍是GPGPU,但严峻的挑战已经摆到眼前:一边是计算量爆棚的生成式AI与大模型发展热情高涨,另一边是即将触顶的算力增长空间与算力消耗所带来的惊人碳排放量。
正如马斯克所述,大多数人会用举一反三的类比推理来思考问题,即模仿别人做的事情再加以小幅更改,可如果想做出新的东西,必须敢于打破常规、积极质疑旧的经验知识,探究问题本质,层层推演,进而创造出新的解决方案。
中国AI大算力芯片的创新之路,大抵亦是如此。
当ASIC、GPGPU发展道路面临底层技术与产业需求的双向夹击,“换道”也许能开辟新的可能。谁能率先填补大模型算力需求的缺口,谁就有机会抢占新一轮AI芯片抢位赛的前排。
国产AI大算力芯片的三波创业浪潮与三大技术流派
ChatGPT引起的算力焦虑,已经将提高能效比与算力利用率的迫切性推到台前。
在产业前景、战略重要性、自主可控等多重因素驱动下,一批批中国AI芯片企业立足于不同的技术路径,前赴后继地进入AI大算力芯片领域,并形成群雄逐鹿的三大技术流派。
第一波浪潮是基于ASIC架构,也可以划定为中国AI大算力芯片落地的技术1.0。
这可追溯至2015年-2016年,并称“天寒地鉴”的AI芯片四小龙云天励飞、寒武纪、地平线、深鉴科技,都是在此期间启动AI芯片研发。其中唯一的FPGA代表玩家深鉴科技于2018年被美国FPGA龙头赛灵思收购。寒武纪和地平线分别是领跑云端和自动驾驶国产大算力芯片落地的企业,都选择做ASIC(专用芯片)。
2016年5月,谷歌揭晓AlphaGo背后的功臣TPU,吹响了产业沿袭ASIC路线的号角。此后多家创企以及华为、亚马逊等云计算大厂均选择在ASIC芯片赛道安营扎寨。上海交通大学计算机科学与工程系教授梁晓峣告诉智东西,在算法较固定的情况下,专用芯片的性能和功耗优势明显,能够满足企业对极致算力和能效的追求。
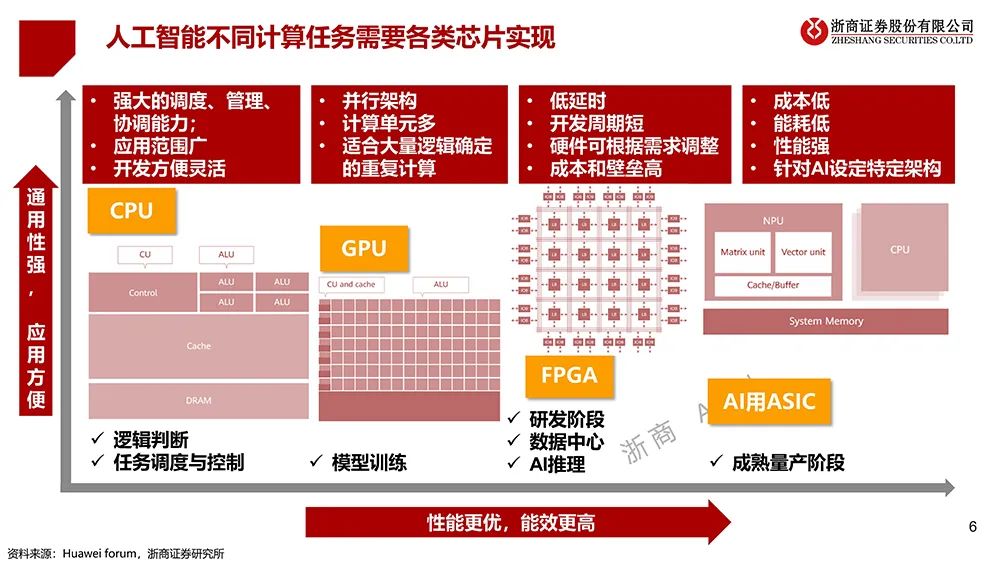
▲AI不同计算任务需要各类芯片实现(图源:浙商证券)
然而,下游AI算法的演进速度远超想象。根据顶级AI研究企业OpenAI在2018年发布的一份分析报告,自2012年到2017年,训练最大AI模型所使用的算力每3.4个月翻1倍。相比之下,按照芯片行业的“圭臬”摩尔定律,芯片上容纳的晶体管数量每18~24个月才会翻1倍,两者之间仅从翻倍的时间上,就产生了16-20个月的差距。
专用芯片在特定场景能实现更高算力和能效,但难以适应算法种类快速的增加以及迭代速度,因此通用性更强的GPGPU一直是AI芯片的主角。在2018年中美科技竞争大幕拉开后,国产替代的呼声越来越高,创业热点随之切换到英伟达雄踞多年的GPGPU(通用GPU)赛道。
这成为第二波浪潮中主流技术路径,也可以划定为中国AI大算力芯片落地的技术2.0。天数智芯、登临科技、壁仞科技、摩尔线程、沐曦集成电路等一批初创公司,大致都是2017年-2020年期间创业或启动自研GPGPU芯片的研发。
资本也蜂拥而至,逻辑很简单,GPGPU市场有英伟达珠玉在前,已经验证了成功的可能性。以英伟达上百亿美元年收入与跻身全球前十的市值来看,假若能切走英伟达在中国的市场份额,足以带给国产AI大算力芯片企业优渥的回报。
但无论是ASIC还是GPGPU,在应对生成式AI及大模型正对算力基础设施提出的新要求,都显得多少有些捉襟见肘。
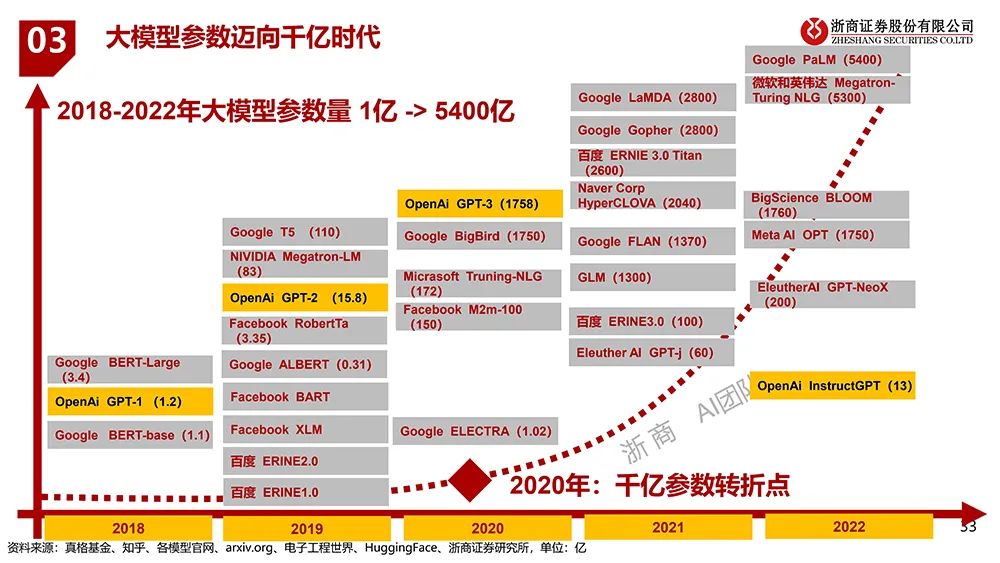
▲大模型参数迈向千亿时代,算力需求一路飙涨(图源:浙商证券)
眼见着摩尔定律身陷边际效用递减的困境,ASIC芯片的弱通用性难以应对下游算法的快速演化,GPGPU又难解高功耗与低算力利用率问题,业界正翘首以盼新架构、新工艺、新材料、新封装,以进一步突破算力天花板。
与此同时,博弈气息日渐浓厚的地缘关系,又给对先进制程工艺高度依赖的AI大算力芯片创企们提出了技术之外的新难题。
在这些大背景下,第三波创业浪潮正滚滚向前。从2017年到2021年期间集中成立的一批创企,选择探路存算一体等新兴技术,这可以被划定为中国AI大算力芯片落地的技术3.0。
不同于ASIC与GPGPU,这些新兴技术路线跳出了冯·诺依曼架构体系,理论上拥有得天独厚的高能效比优势,又能绕过先进制程封锁,兼顾更强通用性与更高性价比,算力发展空间巨大。随着新型存储器件走向量产,存算一体AI芯片已经挺进AI大算力芯片落地竞赛。
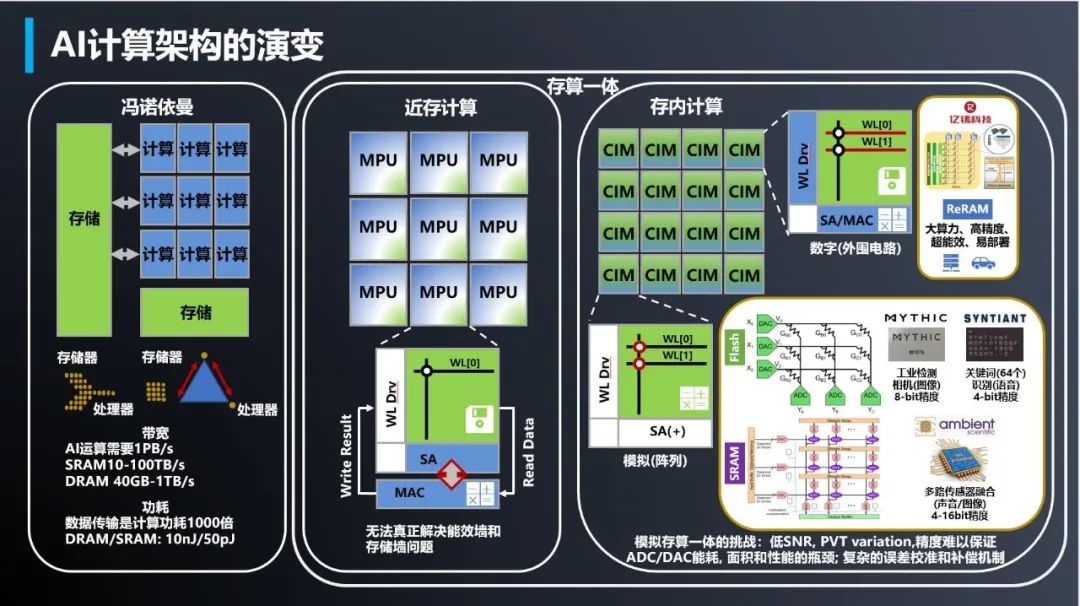
▲冯·诺依曼、近存计算、存内计算架构对比(图源:亿铸科技)
而无论是传统计算芯片还是存算一体芯片,在实际加速AI计算时往往还需处理大量的逻辑计算、视频编解码等非AI加速计算领域的计算任务。随着多模态成为大模型时代的大势所趋,AI芯片未来需处理文本、语音、图像、视频等多类数据。
这个问题如何解决?亿铸科技,一家做存算一体AI大算力芯片的创企提出了自己的解法——存算一体超异构AI大算力技术路径。这也是业内首次提出将存算一体和超异构做结合,提供在大模型时代AI大算力芯片换道发展的一个全新思路。
兼顾通用性&高性能未来必然走向超异构
生成式AI和大模型时代向算力基础设施提出的核心要求,可以简单概括为几个词:提高单芯片算力,突破算力利用率,实现更高能效比。
上海交通大学计算机科学与工程系教授、博导梁晓峣及其团队是开源GPGPU平台“青花瓷”的发起者。他谈道,当下需从系统的角度来思考问题。首先在单芯片算力方面,他非常看好存算一体,认为通过引入新型存储器件工艺,存算一体AI芯片有望将单芯片算力提高1~2个数量级。

▲存算一体能实现超越传统ASIC芯片的更大算力、更高能效(图源:浙商证券)
但单颗芯片很难为大模型提供充足的计算资源与存储资源,这就需要将很多计算芯片连在一起,形成系统。据韩媒报道,受ChatGPT热潮驱动,韩国两大存储芯片巨头三星电子、SK海力士的高带宽内存(HBM)接单量大增。
芯片与芯片之间的数据传输过程,往往会造成大量不必要的资源浪费,导致计算系统受限于传输带宽瓶颈,在实际应用中发挥的算力远小于理论峰值算力。要进一步提升计算资源利用率,必须研究更先进的互连技术,以实现成千上万个AI芯片之间的高效协同。
最后,软件的迭代升级亦不可或缺。要降低芯片开发门槛并实现所有芯片的高效协同,需要设计分布式的AI编程软件平台,来解决线程调度、同步、任务平衡等复杂问题。
“没有一个单芯片能够独立解决大模型问题,所以一定是走向一个超异构。”梁晓峣说,尽管他很看好存算一体路线,但仅靠存算一体还不够,还需与其他架构配合,形成一个完整的系统。
亿铸科技首次提出的“存算一体超异构”概念,就有可能是一个未来的理想组合。
超异构计算将CPU、GPGPU、CIM(存内计算)等不同类型的芯片用先进封装技术组合,让不同架构各司其职,既有灵活、可编程的部分来适应算法的快速变化,又有定制化部分来提供超高性能和超低功耗,通过统筹调度,综合发挥出多类芯片架构的优势,将整体效率做到最优。
由于器件优势,存算一体在同等功耗下能承担更大算力。在超异构计算的基础上,以存算一体架构为核心,以其他架构作辅助,理论上能够兼顾对高算力与通用性的需求。亿铸科技创始人、董事长兼CEO熊大鹏博士相信,存算一体超异构将来会成为AI算力芯片的主流技术路线之一。
在今年2月份举行的国际芯片设计领域最高级别会议ISSCC 2023大会上,AMD董事长兼CEO苏姿丰也提出了相似的“系统级创新”概念,即综合考虑跨计算、跨通信、跨内存等各项元素,从整体上推动系统级性能和能效的提升。
而存算一体超异构理念的前瞻性和落地可行性在于,它不像基于传统计算架构的大算力芯片那样依赖先进制造技术。这一思路需结合的新架构、新存储、新封装等前沿技术,国内均已有储备。
减轻先进制程依赖症,亿铸科技的存算一体超异构如何换道超车?
据悉,存算一体超异构主要运用到新型忆阻器(RRAM)、存算一体架构、Chiplet(芯粒)、3D封装等技术,而国内企业在这些技术路线上已经有越来越多的起色。
Chiplet及先进封装方案能够弥补先进制程落后的劣势,通过将来自不同生产厂商、不同制程工艺的芯片组件“混搭”,降低实现目标性能所需的成本。这为国内芯片企业提供弯道超车的机会。
目前,国内封测巨头相关技术积累已初显成效。例如长电科技的XDFOI Chiplet高密度多维异构集成系列工艺已进入稳定量产阶段;通富微电与AMD密切合作,已大规模生产7nm Chiplet产品;华天科技的Chiplet系列工艺也实现量产。
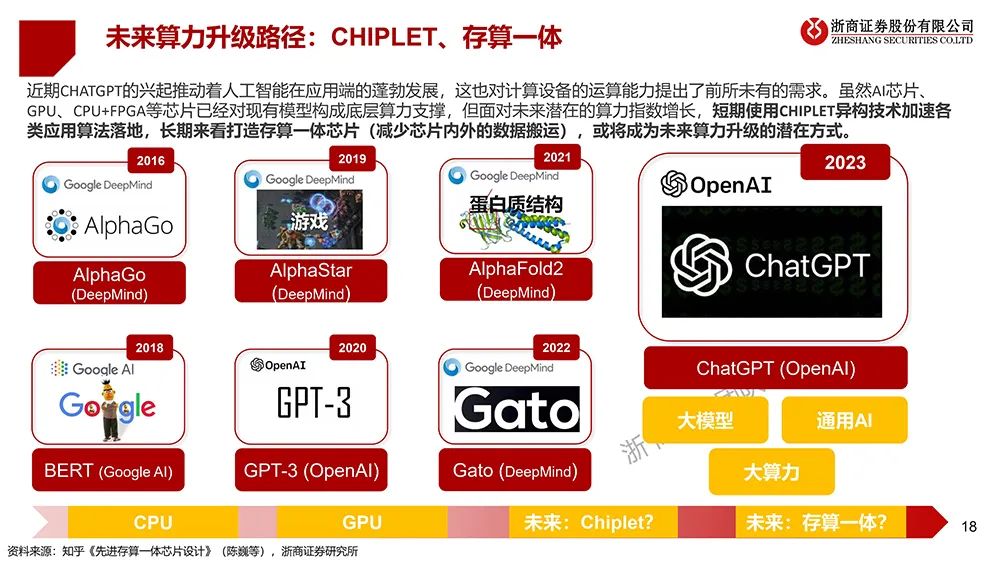
▲未来算力升级路径:Chiplet、存算一体(图源:浙商证券)
从单芯片来看,熊大鹏告诉智东西,存算一体芯片属于是“换道超车”,对工艺的要求较低,比如在28nm工艺上实现的算力和能效,就能比肩甚至超过传统架构芯片在7nm工艺上的表现。
梁晓峣说,亿铸科技是第一家尝试设计并量产基于ReRAM全数字存算一体AI大算力芯片的企业。据熊大鹏透露,亿铸科技自研的存算一体AI大算力芯片,或将在75W-100W功耗范围内实现接近1P的算力,能效比优势非常显著,将于今年回片。同时,亿铸科技基于存算一体超异构概念的下一代芯片设计工作已经开始推进。
从器件来看,相比传统存储器存在易失性、微缩性差等痼疾,亿铸科技选择采用的非易失性新型存储器RRAM更适合应用于AI大算力场景。
此前,台积电、联电、中芯国际、昕原半导体等代工厂均建立了商业化RRAM产线。去年2月,昕原半导体主导建设的RRAM 12寸中试生产线已顺利完成自主研发装备的装机验收工作,实现中试线工艺流程的通线,并成功流片。
熊大鹏认为,随着工艺不断迭代,国内“超车”速度会越来越快,优势会越来越明显。
从超异构来看,对于国内企业来说,CPU有广受欢迎的开源RISC-V架构,GPGPU有新兴的开源架构“青花瓷”平台,存算一体也有亿铸科技等厂商在大力投入研发。
开源GPGPU“青花瓷”平台由上海交通大学先进计算机体系结构实验室开发,定位相当于GPGPU领域的RISC-V架构。它提供了一个免费开放的先进GPGPU指令集和架构参考设计,能够接入现有GPGPU生态,从而助力降低设计门槛,加速相应产品的落地。

▲“青花瓷”平台开源代码页面
“青花瓷”平台直通门:gpgpuarch.org
开源地址:github.com/SJTU-ACA-Lab/blue-porcelain
在梁晓峣看来,超异构需要不同类型的芯片架构互相配合、取长补短,这恰好与“青花瓷”平台的设计思路完美契合。
存算一体架构适用于计算和数据量大但算法相对简单的应用,在性能和功耗的优势超过其他类型架构;而GPGPU架构可以适配现有的主流AI框架和平台,并能处理比较复杂的算法。两者结合,将会实现更大有效算力、放置更多参数、实现更高能效比、更好的软件兼容性。
因此,面向未来大模型时代,存算一体超异构的技术路径打开了国内AI大算力芯片技术发展的新思路,而亿铸科技的存算一体超异构芯片是该路径在国内切实落地的关键一步。
结语:大模型落地势不可挡AI算力困境亟待换道突破
正如苏姿丰所言,AI已是未来十年最重要的事。
在生成式AI风暴的催化下,大模型正发展成AI基础研究和产业化落地的一大趋势。这对三波创业浪潮中的一众AI大算力芯片创业公司提出了摩尔定律濒临极限之外更大的技术挑战:如何以更低的系统成本、更少的能源消耗,支撑起庞大且持续增加的参数量所带动的更高算力需求?
在美国对华屡屡架设芯片藩篱的背景之下,国内短期内难以实现先进制程的自主可控。回望中国AI大算力芯片发展历程,业界一直用“弯道超车”来寄予对其发展路径的期待,但弯道超车隐喻着产品和技术的发展和行业头部企业在同一赛道上做跟随和追及,这势必对后来者在速度上和超车节点的把握上提出了更高的要求。
骨感的现实告诉我们,中国AI大算力芯片在“弯道超车”路径下,也许还有很长的路要追赶。而“换道”可能加速缩短与国际先进水平的差距。同时,换道发展也不是无本之木,其芯片设计和量产有着严谨的底层逻辑和成熟的产业链配套作为支撑。亿铸科技的存算一体超异构AI大算力芯片技术,便提供了一种能够适应未来算法快速变化、满足算力可持续发展需求的可行思路。
中国AI大算力芯片企业面临的挑战依然险峻,但不管是落地技术的1.0、2.0还是3.0,不管是同道追及还是换道前行,所有的努力都是为了支撑中国AI产业的高速发展,只要能切实解决问题,提供有价值的产品,都值得关注和期待。沉舟侧畔千帆过,病树前头万木春,希望看到更多像亿铸科技这样的机构,大步流星地走到换道前行的赛道上,为破解国内AI大算力困局探寻属于中国AI芯片产业自己的发展道路。
作者 | ZeR0
编辑 | 漠影



