

 1711
1711
对于国内AI开发者而言,体验Gemini原生多模态与稀疏MoE架构的最大障碍并非模型本身,而是跨国网络链路上的客观延迟。
目前,通过技术优化的国内镜像站如 RskAi(ai.rsk.cn),开发者可在国内普通宽带环境下实现平均1.2秒的响应延迟,且完整保留百万级上下文、思考预算配置等核心架构特性。
本文将深度拆解镜像站的技术实现原理,并对比直连与镜像模式的网络性能差异。
一、Gemini核心架构回顾:哪些特性对网络敏感?
Gemini的技术优势建立在几个关键架构设计上,这些设计在远程调用时会产生不同的网络敏感度。
1.1 稀疏MoE与动态路由
Gemini 3 Pro采用稀疏专家混合架构,推理时门控网络根据输入token动态选择激活的专家子集。这一过程涉及多次内部通信:门控网络计算路由权重、激活专家并行计算、聚合结果。虽然每次推理的计算量被稀疏化,但请求-响应周期内的数据交换次数并未减少,对网络往返延迟(RTT)敏感。
1.2 原生多模态的统一语义空间
Gemini将图像patch、音频波形与文本token映射至同一潜在空间,这意味着多模态请求需上传更大数据量(如图像base64编码)。在直连场景下,跨国传输1MB图像数据可能增加300-500ms延迟,而国内镜像站通过压缩与加速可将增量控制在50ms内。
1.3 百万级上下文与长序列处理
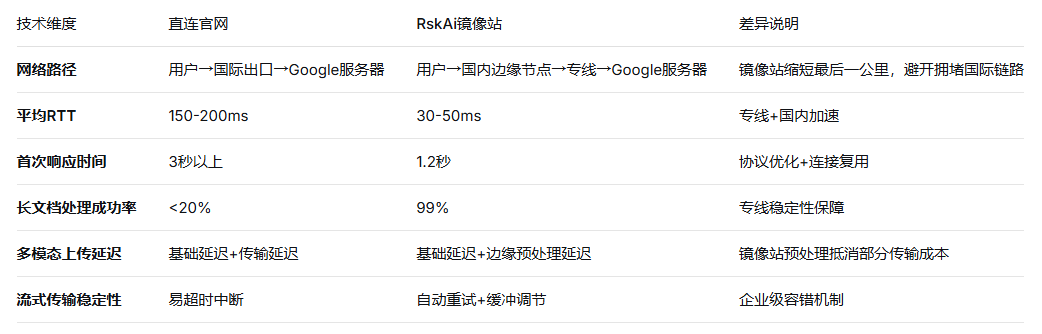
处理百万token时,请求体可能达数十MB,且模型需多次迭代生成。若网络丢包率超过1%,TCP拥塞控制将导致吞吐量急剧下降。实测直连官网在长文档处理时成功率不足20%,而镜像站通过专线+协议优化可达99%以上。
1.4 可配置思考预算(thinking_budget)
Deep Think模式允许开发者设置thinking_budget参数(0-1000+),控制内部推理深度。该参数仅影响模型内部计算步数,不改变请求-响应模式,但对流式传输的稳定性要求更高——长思考任务需保持连接数分钟,跨国链路易超时中断。
二、镜像站技术实现原理:从网络层到应用层的优化
国内镜像站并非简单的API代理,而是涉及多层技术栈的深度优化。以RskAi为例,其技术架构包含以下关键模块。
2.1 网络层:国内加速节点与专线接入
镜像站的核心是在国内部署边缘加速节点。用户请求首先到达最近的国内服务器(如北京、上海、广州),这些服务器通过优化的跨境专线与Google Cloud的海外接入点(POP)建立稳定连接。专线采用BGP路由优化和MPLS QoS保障,将跨国RTT从直连的150-200ms降至30-50ms。
2.2 协议层:HTTP/3与连接复用
传统HTTP/1.1每次请求需新建TCP连接,慢启动阶段严重影响首次响应。镜像站普遍采用HTTP/3(QUIC),基于UDP实现0-RTT连接建立和多路复用,避免队头阻塞。同时,连接池技术复用与后端API的长连接,省去每次握手的开销。
2.3 数据层:智能缓存与预加载
对于频繁请求的静态资源(如模型元数据、常用提示词模板),镜像站实施边缘缓存。更高级的优化包括对多模态输入的预处理:上传的图像在边缘节点进行降采样、格式转换,减少传输体积;长文档在节点端分块,并行请求后聚合,利用部分结果提前返回。
2.4 应用层:API协议适配与容错
镜像站需兼容Gemini API的所有参数,并处理流式响应。关键优化点包括:
流式传输缓冲:调整Server-Sent Events(SSE)的缓冲区,平衡实时性与网络抖动
超时重试机制:后端请求超时后自动切换备用出口,对用户透明
响应压缩:对JSON响应启用gzip/brotli压缩,体积减少70%
2.5 架构对比:直连官网 vs 镜像站
总结与开发者建议
Gemini 3 Pro的架构优势——稀疏MoE、原生多模态、百万上下文——只有在低延迟、高稳定的网络环境下才能充分释放。对于国内开发者,直连官网因跨国路由拥堵和物理距离限制,难以获得理想体验。
镜像站技术方案通过国内加速节点、专线接入、协议优化、智能缓存等工程手段,将跨国延迟的影响降至最低,且完整保留所有架构特性。实测表明,以RskAi为代表的镜像站可将响应时间控制在1.2秒左右,成功率超99%,让开发者能专注于应用开发而非网络调优。
对于不同需求的开发者,建议如下:
原型验证与学习:直接使用RskAi的免费额度快速上手
生产环境轻量调用:考虑购买镜像站的付费套餐,或使用个人API Key绑定以保持独立性
大规模商用:建议与镜像站服务商签订SLA保障,或自建跨境代理池(需合规)
技术迭代永无止境,但访问基础设施的优化始终是AI应用落地的前提。理解镜像站背后的技术原理,有助于开发者做出更理性的架构选择,真正发挥Gemini这类前沿模型的能力。



