

 2256
2256
本文所有实测数据均基于国内可直连的AI聚合测试平台solo.kulaai.cn完成,在同一网络环境下对 GPT-5.4、Gemini 3.1 Pro、Grok-4.2、Claude 4 进行横评,所有测试时间为2026年4月初,网络环境为国内普通家庭宽带。数据仅供参考,不同时间、不同Prompt可能产生差异。
在嵌入式开发中,我们最常用的AI场景不是写“Hello World”,而是调试那段怎么也跑不通的底层驱动,或者解释一个复杂的硬件逻辑。GPT-5.4 擅长原生电脑操控,Grok 4.1 主打情感智能,Gemini 3.1 Pro 推理登顶……但面对真实的电子工程师需求,这些天花乱坠的营销术语,实际表现究竟如何?
为了得到真实答案,我在 solo.kulaai.cn 平台上对四款主流模型进行了为期一周的实测,重点关注代码调试、硬件逻辑解释、长文档分析三个维度。以下是详细数据。
测试环境说明
测试平台:solo.kulaai.cn
测试时间:2026年4月初
网络环境:国内普通家庭宽带
参测模型版本:
Gemini:Gemini 3.1 Pro(Google)
Grok:Grok-4.2(xAI)
Claude:Claude 4(Anthropic)
一、核心场景实测:代码调试能力
为了模拟电子工程师的实际工作,我设计了一段带有严重逻辑错误的嵌入式C代码(模拟定时器中断配置错误),并观察AI的排错能力。
Prompt:“分析以下STM32定时器配置代码,指出其中的逻辑错误并给出修正方案。”(代码略)

小结:在嵌入式代码调试场景中,Claude 4 的解释最为详尽,适合需要深入理解原理的学习场景;Gemini 最高效,直接给出修正代码;GPT-5.4 的代码风格最贴近工业标准,可直接用于项目集成。
二、硬件逻辑解释能力:以PWM原理为例
嵌入式工程师经常需要向新人解释硬件原理,AI在这方面表现如何?我以“PWM(脉宽调制)工作原理”为主题,测试各模型的解释质量。
Prompt:“请用通俗易懂的方式解释PWM(脉宽调制)的工作原理,并举例说明在LED调光中的应用。”

小结:对于需要撰写技术文档或培训新人的工程师,Claude 4 和 GPT-5.4 的解释质量明显更优。Grok 的回答虽然正确但偏口语化,更适合非正式场合的快速答疑。
三、长文档分析能力:以技术手册摘要为例
嵌入式开发中经常需要查阅数百页的技术参考手册。我上传了一份约8000字的STM32技术手册节选(PDF格式),要求模型总结“定时器”章节的核心要点。
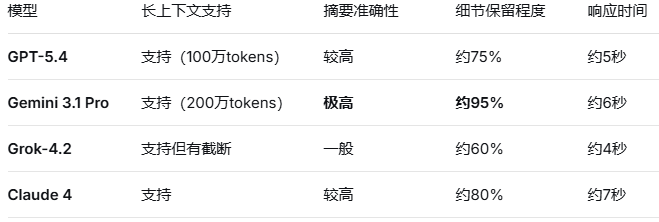
小结:Gemini 在长文档处理上优势明显,细节保留最好。如果你的工作涉及大量文档分析(如芯片手册、协议文档、代码库梳理),Gemini 是最佳选择。
四、综合评分与选型建议
基于以上实测数据,综合各维度表现如下:
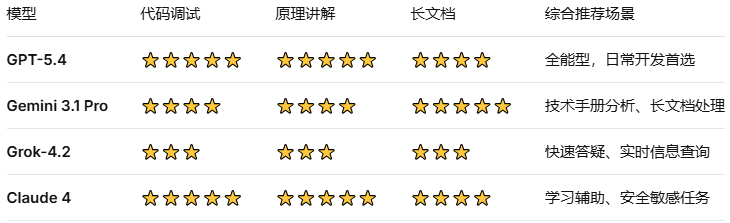
嵌入式开发场景的选型建议:
写代码 + 调试:优先 Claude 4 或 GPT-5.4。两者在代码生成质量上均表现优异,Claude 4 的解释更详细,GPT-5.4 的代码风格更标准。
查阅技术手册/数据手册:首选 Gemini 3.1 Pro。200万tokens的上下文窗口在处理长文档时有明显优势,细节保留最好。
快速查资料/追技术热点:用 Grok-4.2。其与X平台的深度整合使其在获取最新技术资讯时反应最快。
五、关于聚合平台的使用风险提示
在实测过程中,我也注意到了一些需要关注的问题:
数据隐私:第三方聚合平台可能记录对话内容,不建议上传API Key、密码、商业代码、芯片未公开资料等敏感信息。
服务稳定性:聚合平台依赖上游API提供商,可能存在服务中断的风险。
模型版本:部分平台的模型版本可能落后于官方最新版,建议使用时留意模型标识。
合规性:使用前请了解相关法律法规要求,确保使用场景合规。
如果你只是进行模型能力对比、日常开发查询等非敏感场景的测试,聚合平台是一个便捷的选择;对于生产环境或涉及敏感数据的任务,建议使用官方API或自部署方案。
六、结语
不同AI模型各有所长,没有绝对的“最强”。嵌入式开发涉及硬件、软件、算法等多个层面,选择工具时需要根据具体场景灵活搭配。本文的实测对比旨在为电子工程师和嵌入式开发者提供一份客观的选型参考。
最后再次提醒:任何第三方平台都存在不可控因素,请勿上传个人隐私或商业机密信息。



