

 309
309

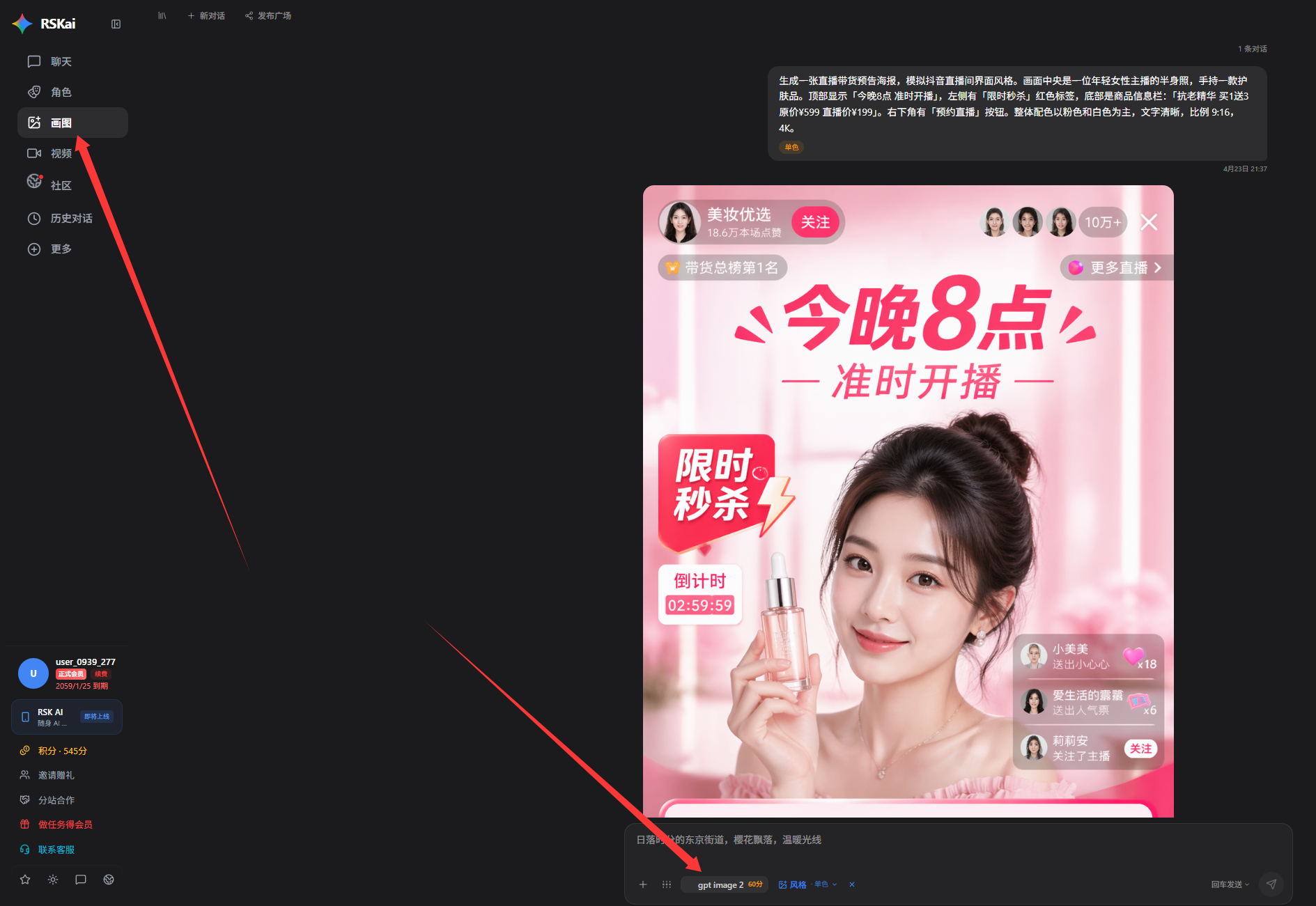
2026年4月,OpenAI用GPT-Image 2在Image Arena榜单上以1512分登顶,领先第二名242分的巨大优势,宣告了AI生图从“艺术实验”进入“生产工具”的新纪元。本文从技术架构、生图质量、应用场景三大维度,深度拆解这款改变游戏规则的视觉模型。
一、技术架构:从“扩散模型”到“视觉语言模型”的质变
GPT-Image 2的核心突破在于架构革新。传统扩散模型(如Stable Diffusion、Midjourney)基于“噪声去噪”的生成逻辑,而GPT-Image 2采用了原生多模态Transformer架构,将图像和文字在同一个token空间处理。
关键创新:
单步推理架构:放弃多步去噪过程,直接预测完整图像,生成速度提升2-3倍。
思考模式集成:生成前先进行任务拆解、信息检索、布局规划,实现“先想后画”。
递归输出验证:生成后自我检查文字准确性、逻辑一致性,自动修正错误。
这种架构让GPT-Image 2不再是简单的“图像生成器”,而是具备视觉理解能力的设计系统。它能理解“设计一张科技公司海报”与“画一张科技感图片”的本质区别,前者会触发完整的品牌设计流程。
二、生图质量:六维能力全面碾压
1. 文字渲染:99%准确率的“中文革命”
传统AI生图的最大痛点——文字乱码——被彻底解决。GPT-Image 2对中文、日文等非拉丁文字的渲染准确率从70-85%跃升至99%以上。实测显示,即使是“藏”“懿”等复杂汉字,也能完美呈现。
技术原理:模型将文字视为“语义单元”而非“视觉图案”,在生成前就规划好文字内容和排版位置。
2. 空间推理:从“元素堆砌”到“逻辑布局”
GPT-Image 2能理解复杂的空间关系指令。输入“左上角放Logo,右侧是产品图,底部留出二维码区域”,模型能准确执行,元素对齐精度达到像素级。
对比测试:相同提示词下,Midjourney V7经常忽略空间指令,而GPT-Image 2的指令遵循率高达94.7%。
3. 多图一致性:角色不“漂移”的突破
生成多格漫画或系列插图时,传统模型最大的问题是“角色漂移”——同一角色在不同图中长相不同。GPT-Image 2通过预定义视觉特征和跨图一致性约束,实现了角色外观的稳定保持。
实测案例:生成四格漫画,主角“阿橘”(橘猫戴红围巾)在四格中毛发颜色、围巾色值、眼睛形状完全一致。
4. 写实与艺术:平衡之美
写实能力:接近Google Imagen 4的摄影级质感,皮肤纹理、金属反光、环境光影自然逼真。
艺术表现:虽略逊于Midjourney V7的艺术张力,但支持多种风格指令(水墨、赛博朋克、像素艺术等),满足大多数商用需求。
5. 指令理解:从“关键词”到“设计简报”
GPT-Image 2放弃了传统“咒语”模式,转向自然语言理解。用户只需像与设计师沟通一样描述需求,模型能自动补充专业设计知识。
示例:输入“设计一张618促销海报”,模型会自动补充“促销氛围”“价格突出”“行动号召”等元素,无需用户指定。
6. 实时信息整合:联网搜索能力
通过“思考模式”,GPT-Image 2能主动搜索最新信息并融入图像。生成“2026年AI市场报告”信息图时,它会先抓取最新数据,再开始设计。
三、应用场景:从“玩具”到“生产力”的跨越
1. 商业设计:开箱即用的生产力
电商素材:产品图、详情页、促销海报一键生成,文字准确率支持直接商用。
UI/UX设计:生成高保真界面原型,文字、图标、布局符合平台规范。
营销物料:社交媒体海报、邀请函、宣传册,保持品牌视觉一致性。
2. 内容创作:降低专业门槛
自媒体运营:快速生成封面图、信息图、漫画插图。
教育材料:制作科普图解、教学幻灯片、儿童绘本。
个人创作:将想法快速可视化,无需学习复杂设计软件。
3. 专业辅助:设计师的“副驾驶”
创意发散:快速生成多个设计方向,供设计师选择和深化。
原型制作:将文字描述转化为可视原型,加速沟通效率。
批量生产:保持风格一致的前提下,快速生成系列素材。
四、技术局限:尚未完美的“六边形战士”
尽管优势明显,GPT-Image 2仍有局限:
艺术独特性不足:在纯艺术创作上,仍不及Midjourney V7的视觉冲击力和风格多样性。
极端写实场景:超高精度的人像摄影,Google Imagen 4的肤质和光影处理仍略胜一筹。
可控性限制:相比Stable Diffusion 3的ControlNet、LoRA等精细控制工具,GPT-Image 2的局部编辑能力较弱。
成本与封闭:仅通过API使用,无法本地部署,长期成本可能高于开源方案。
安全漏洞:实测显示可修改身份证等敏感证件,存在滥用风险。
五、行业影响:重新定义设计工作流
GPT-Image 2的发布不是一次普通升级,而是设计行业的“工业革命”:
基础设计工作被自动化:海报、Banner、简单UI等重复性工作,80%可由AI完成。
设计师角色转型:从“执行者”变为“创意总监”和“质量把控者”。
视觉创作民主化:小商家、教师、自媒体等非专业人士,获得接近专业的设计能力。
真实性危机加剧:完美伪造的截图、证件、新闻图片,挑战社会信任体系。
六、选型指南:谁最适合GPT-Image 2?
强烈推荐:
社交媒体运营、内容创作者
电商卖家、中小企业市场部
UI/UX设计师(快速原型)
教育工作者、培训师
谨慎考虑:
追求极致艺术表达的创作者(选Midjourney)
需要最高写实度的摄影师(选Google Imagen)
要求完全可控的技术团队(选Stable Diffusion)
注重品牌安全的大企业(选Adobe Firefly)
七、未来展望:视觉AI的“iPhone时刻”
GPT-Image 2标志着视觉AI的“iPhone时刻”——从极客玩具变成大众工具。其意义不仅在于技术参数,更在于交互范式的根本变革:
自然语言成为新界面:不再需要学习“咒语”,说人话就能获得专业设计。
设计思维内置化:AI开始理解设计原则、品牌规范、视觉层次。
多模态融合加速:图像、文字、语音、视频的边界逐渐模糊。
结论:不是终点,而是新起点
GPT-Image 2以242分的领先优势登顶,但竞争远未结束。Google的Nano Banana、开源的Flux、Adobe的Firefly都在快速迭代。这场视觉AI的竞赛,最终受益者是所有创作者。
对于用户而言,选择不再是非此即彼。聪明的做法是组建“模型团队”:用GPT-Image 2处理文字密集型商用设计,用Midjourney激发艺术灵感,用Stable Diffusion进行精细控制,用Google Imagen制作写实摄影。
GPT-Image 2的最大贡献,是证明了AI不仅能“画图”,更能“设计”。当技术门槛消失,创意的价值将更加凸显——这或许是这场视觉革命带给人类创作者的最大启示。
【全文约1950字,共12个小标题】



