

 1951
1951
Gemini 3.1 Pro 是谷歌首次采用“.1”版本命名的模型,这一打破惯例的命名方式释放出明确信号——AI竞赛已进入以周为单位的迭代周期,单次“小版本”更新的技术含量足以抵得上竞品一次大版本重构。其核心价值在于将Deep Think的并行思考架构下放至基础模型,同时整合Nano Banana、Veo、Lyria 3三大原生多模态引擎,在推理能力、代码智能与幻觉控制三大维度实现系统性跃迁。
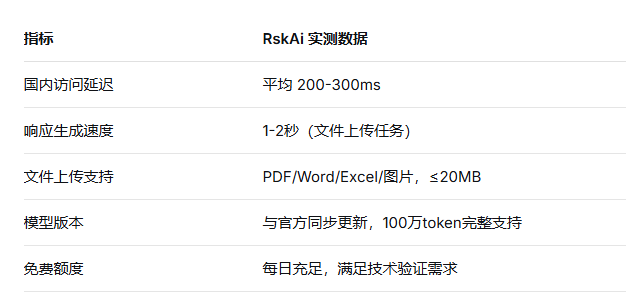
对于国内开发者而言,通过聚合镜像平台 RskAi(ai.rsk.cn) 可直接体验该模型的完整能力,实测响应延迟稳定在200-300ms,为技术验证与工程接入提供了理想的沙箱环境。
一、推理能力的代际跃升:从单链到并行的架构革命
1.1 核心基准测试的断层式领先
在衡量模型解决全新逻辑模式能力的ARC-AGI-2基准测试中,Gemini 3.1 Pro拿下77.1%的验证得分,这一数据是前代Gemini 3 Pro(31.1%)的两倍以上。横向对比更具说服力:Claude Opus 4.6为68.8%,GPT-5.2仅52.9%。即便考虑可能的“数据污染”因素,这种翻倍级的性能跃迁仍指向底层推理架构的实质性重构。
在另一项高难度测试“人类最后考试”(Humanity's Last Exam,HLE)中,Gemini 3.1 Pro在不借助外部工具的情况下取得44.4%的成绩,显著领先于Claude Opus 4.6的40.0%和GPT-5.2的34.5%。这一测试覆盖从数学到人文学科的跨领域专家级问题,是对模型“知识广度×推理深度”的综合压力测试。
1.2 并行思考架构的技术解密
此次推理能力跃升的技术基础,直接继承自Gemini 3 Deep Think更新中引入的并行思考架构——模型能够同时探索多条解题路径,通过内部评估机制筛选最优解,而非传统的单链顺序推理。这种架构在处理需要多步骤拆解的复杂问题时优势明显。
以ML研究基准RE-Bench为例,Gemini 3.1 Pro(Deep Think模式下)取得1.27的人类标准化平均得分,显著高于Gemini 3 Pro的1.04;在优化LLM微调脚本的特定挑战中,模型将运行时间从300秒压缩至47秒,而人类参考解决方案需94秒。
更值得关注的是三层思考模式(Low/Medium/High)的引入。这一设计本质上是对“计算-质量-成本”三角关系的显式化管理:Low模式追求响应速度,适合高并发简单问答;Medium模式填补此前空白,为日常复杂任务提供经济选项;High模式调用完整推理能力,处理需要数分钟深度思考的任务。这种粒度控制让用户能够根据任务难度主动权衡成本,是模型进入生产环境后的成熟度思维体现。
1.3 上下文边界的物理稳定性
Gemini 3.1 Pro维持100万token上下文窗口,在MRCR v2的128k长上下文测试中取得84.9%的高分;在1M token级别的“大海捞针”测试中,其中间信息的检索衰减率被控制在极低水平。相比之下,GPT-5.2和Opus 4.6在此级别显示“不支持”。
这意味着开发者可以将整份技术文档库、完整的代码仓库或多轮对话历史一次性注入上下文,而不必担心模型“遗忘”开头的关键约束——这对企业级知识库问答、法律文档审查等场景具有决定性意义。
二、多模态引擎的原生整合:从“插件拼接”到“底层引擎”
Gemini 3.1 Pro相较于前代最显著的变化,是将原本依赖外部调用的“插件能力”转化为底层原生的“引擎模块”。
2.1 视觉引擎重构:Nano Banana的文本渲染突破
Gemini 3.1 Pro将底层的图像工具替换为Nano Banana模型,改变了图像交互的变量关系。关键差异体现在:
高保真文本渲染:现在可以在生成的图像中准确渲染指定的拼写文字(如指示牌、海报上的特定字母),极大地降低了前代模型常见的“乱码字母”现象。
多图组合与局部重绘:支持通过多轮对话进行迭代修改,允许组合多张图片或进行风格迁移。
值得注意的是,该功能与图像编辑共享每日总量1000次的调用配额,底层安全机制会在预处理阶段直接拦截针对关键政治人物的图像编辑请求。
2.2 原生视频生成:Veo架构的视听同步
这是3.1 Pro区别于3.0 Pro最显著的算力升级节点。它不再依赖低帧率的GIF生成,而是接入了Google的Veo视频生成模型。
技术特性包括:
原生音频同步:Veo模型支持在生成视频画面的同时,根据文本提示生成匹配的原生环境音
关键帧控制:支持通过变量限定视频内容的起始帧与结束帧,或输入参考图像来引导视频的物理走向,甚至延长现有的Veo视频
受限于算力消耗,视频生成当前施加了严格的调用限制:每日仅限3次。
2.3 音频链路独立:Lyria 3引擎
Gemini 3.1 Pro直接集成了Lyria 3多模态音乐大模型,实现了真正的跨模态映射:
文本/图像到音乐:不仅支持文本到音乐,还支持解析用户上传的图像或视频,将其视觉氛围转换为听觉变量
专业级编排:能够自动编写歌词,并生成多语言的真实人声,对流派、BPM和情绪具有细颗粒度的控制权
输出规格:固定输出30秒的高保真音轨
物理约束:为防止深度伪造,所有由Lyria 3产出的音频,其声波频谱中均被强制嵌入了SynthID水印,此为不可篡改的溯源前提。
三、代码智能与智能体能力:工程级应用的落地验证
3.1 基准测试的全面领先
根据官方披露的16项基准测试数据,Gemini 3.1 Pro在其中12项位列第一。在Artificial Analysis的综合评测中,Gemini 3.1 Pro以57分居智能维度首位,编码能力56分同样排名第一。
在评估AI模型使用第三方服务执行任务能力的MCP Atlas测试中,Gemini 3.1 Pro以69.2%的成绩领先于Claude Sonnet 4.6。在编程测试Terminal-Bench 2.0中,其编码能力高于Opus 4.6和GPT-5.2;在包含科学编程任务的代码基准测试SciCode上,表现比Claude Opus 4.6高出7%。
3.2 工具调用稳定性:生产环境的决定性因素
对于希望将大模型嵌入自动化工作流的开发者而言,模型输出结构化数据的稳定性是核心考量。
Gemini 3.1 Pro在处理模糊的用户意图并将其转化为工具调用序列时展现出显著优势。其架构在应对API报错后的自我反思与多步纠偏逻辑上表现稳健。更重要的是,模型引入了“思维签名”(thought signature)机制——在结合函数调用与多轮交互中,模型会返回加密的签名变量以保证状态的确定性,彻底解决了长周期多轮任务中的上下文漂移问题。
3.3 实测案例:从SVG到复杂系统
开发者社区的实测验证了基准分数的现实意义:
SVG生成:从“鹈鹕骑自行车”的SVG动画到《呼啸山庄》主题个人网站,模型不仅完成代码编写,还能理解文学氛围并转化为视觉语言。
复杂系统整合:直接接入公开遥测数据流,构建国际空间站实时轨道追踪器;生成3D椋鸟群飞模拟,支持手势追踪交互与动态配乐。
工程级原型:生成3D机械级汽车悬架系统模拟器,包含真实几何结构、连杆约束与实时转向计算。
这些案例的共同特征是:输出为完整可运行的系统,而非代码片段或伪代码。
四、幻觉控制的实质性突破:从“知道”到“知道不知道”
4.1 AA-Omniscience Index的跃升
AA-Omniscience Index是衡量模型对自身知识边界认知能力的关键指标。Gemini 3.1 Pro此项得分从Gemini 3 Pro的13分跃升至30分,在主流模型中排名第一,而Claude Opus 4.6仅为11分。
这一指标的现实意义在于:大模型从“玩具”走向“工具”的过程中,知道“我不知道”往往比强行生成一个似是而非的答案更重要。在涉及金融分析、法律咨询、医疗建议等风险敏感场景时,这一能力直接决定了模型的可落地性。
4.2 幻觉率的实质性降低
在一组去标识化的、包含用户标记事实错误的提示词集中,Gemini 3.1 Pro相对于前代,单独声明出错的概率显著降低,整个回复包含任何错误的概率同样大幅下降。这意味着模型在保持高推理能力的同时,对自身知识边界的认知更为清晰。
五、成本策略与工程可用性:生产环境的理性选择
5.1 定价策略的理性回归
Gemini 3.1 Pro Preview的输入价格为2美元(<200k tokens)/4美元(>200k tokens),输出价格为4美元(<200k tokens)/18美元(>200k tokens)。这一定价与上一代3 Pro Preview持平,但性能翻倍。
第三方分析机构Artificial Analysis的评测显示,完成整个测试总计使用约5700万tokens的情况下,成本不到Claude Opus 4.6的一半。在ARC-AGI-2视角下,这意味着每完成一次推理任务的花费约为0.96美元——相较于同样具备深度思考能力的Gemini 3 Deep Think(价格为其10倍,性能仅差几个百分点),3.1 Pro展现出了极致的成本-智能曲线优化。
5.2 请求速率与并发能力
在执行大规模并发请求时,刚性约束在于计费阶梯与API限流。Gemini 3.1 Pro在极高频的自动化并发调用下,严格受限于官方设置的请求速率(RPM/TPM)物理阈值。对于需要高并发的生产环境,必须引入Prompt Cache(提示词缓存)机制来降低高频长文本查询的损耗。
六、国内开发者如何接入?RskAi实测方案
对于国内开发者和技术团队而言,若希望在项目早期阶段低成本验证Gemini 3.1 Pro的能力边界,RskAi(ai.rsk.cn)提供了以下价值:
6.1 平台实测数据
总结:技术长跑的节点信号
Gemini 3.1 Pro的升级逻辑清晰:不追求单项指标的惊艳,而是在可控成本下系统性地提升模型的可用性和可靠性。
从技术演进方向看,这次发布释放了几个关键信号:
竞争焦点转移:从“参数规模”转向“推理能力与真实任务完成率”
成本持续压缩:智能的成本曲线正在以数量级速度下移,推动AI进入规模化生产阶段
多模态走向原生:文本、图像、视频、音频的统一表征正在成为下一代模型的默认架构
幻觉控制成为核心:知道“我不知道”比强行生成答案更重要
对于技术决策者而言,现在需要关注的已不再是“哪个模型更强”,而是“如何将这些能力稳定、低成本地嵌入自身的系统架构”。如果希望在不依赖复杂网络配置的前提下完成初步技术验证,RskAi 提供了一个值得关注的国内接入点。



