

 750
750
上周,美国对华芯片政策再次加码,要求AMD及英伟达暂停对中国大陆出货面向数据中心的GPU计算卡。英伟达服务器GPU——A100与H100,AMD服务器GPU——MI100与MI200均在禁售名单之上。
消息一出,立马有朋友在微信上问我,高端GPU禁售,是不是代表我以后打游戏买不到显卡了?
作为一名垂直行业的媒体记者,笔者觉得有必要站出来稍加说明,为一些行外的小白做点科普,于是就有了这篇文章。事实上,美国本次禁售的显卡属于服务器用GPU,虽然它与我们日常使用的消费级显卡都叫GPU,但用途和参数有着较大不同。
以RTX、RX显卡为代表的消费级独立显卡
显卡(Video card)全称为计算机显示卡,是个人计算机的重要组成部分,主要提供显示计算输出的功能,还可以运行深度学习等运算。
我们拿英伟达GeForce RTX 3090 Ti显卡举例。

英伟达3090Ti 参数 来源:zol中关村在线
显卡的工作内容其实很简单。电脑屏幕上所有的画面其实是显卡一张一张“画”出来的。CPU执行程序指令后,把需要显示的内容命令通过主板上的PCIE插槽交给GPU,GPU逐张画好图像后再通过显卡接口交给显示器显示。我们在上图看到的CUDA核心数量就相当于画师数量,画师越多,理论上绘画速度就越快。基础频率/加速频率相当于每个画师的绘画速度,频率越高,单个画师作图速度越快。
画师将图像画好后,会放到“显存”仓库里暂存,再通过货车运送到显示器进行显示,货车的数量就是显存位宽。
此外,显卡的接口也有不同的种类。我们日常价看到的接口主要有VGA、DVI、HDMI、DP等。

首先说下VGA,这个接口传输模拟信号,共有三排15个针脚。作为在大头电脑(显像管显示器)时代已经普及的接口,至今传输速率已经跟不上科技发展水平,目前在部分低端显示器与显卡上还在使用。
DVI接口传输数字信号,包括DVI-I单、双通道与DVI-D单、双通道等。它采用数字信号方式传输,不过部分无法传输音频信号。由于其复杂的接口样式,目前也渐渐用的少了。
重点聊聊后面两个常用接口。
HDMI接口,High Definition Multimedia Interface,高清多媒体接口,俗称高清口。这个接口想必大家不会陌生,它也采用数字信号方式传输数据,并且可以同时传输音频信号,目前大多数电脑、投影、电视等设备都是用该接口。HDMI2.0就可以支持4K 60Hz HDR的图像传输了。
DP接口,DisplayPort,数字式视频接口标准。DP接口是2006年才新出现的,是目前中高端显卡、显示设备的标配。DP 的功能和 HDMI 非常相似,主要用于视频传输。目前主流是DP1.2和DP1.4版本。其中DP1.2即可支持4K 60Hz,DP1.4支持8K 60Hz,或4K 120Hz,同时音频提升到32声道1536 KHz采样率。
说了这么多,那服务器用的GPU通常用哪个接口呢?
答案是,没!有!接!口!
专注计算功能的服务器GPU
是的,没有错,通常服务器用GPU是没有视频输出接口的。这类GPU的使用场景与日常见到的显卡不太相同,它通常被称为计算卡或加速卡。
GPU服务器是基于GPU搭建,用于视频编解码、深度学习、科学计算等多种场景的快速、稳定、弹性的计算服务。而服务器GPU就是专门使用在这类服务器上的计算芯片。
服务器加装GPU后,就可以用来运行CPU不擅长运行的大规模浮点运算,或是进行3D图形渲染、视频解码、深度学习等运算。通常来说,因为它专注于各类计算工作,所以服务器GPU并不需要独立的图形显示模块来输出图像。
我们以本次被限制进口的英伟达H100 SXM举例。

H100 SXM渲染图 来源:英伟达
H100是英伟达在2022年新推出的顶级GPU。它采用最先进的台积电4nm技术,以单个芯片上就集成了8000亿个晶体管。此外,H100还集成了144组流处理器单元,每组单元有128个CUDA核心,共计18432个。
还记得之前提到的RTX3090Ti拥有的CUDA核心数量吗,H100要比3090Ti多了近1倍。除了核心,H100还拥有80GB的显存容量、3TB/s的显存带宽,无论从哪个角度看,H100都完胜RTX系列GPU。当然,如此强悍的性能,其价格也不会低(老黄才不做亏本买卖)单块H100的售价高达24万元人民币。
为了驾驭H100如此强劲的性能,该类GPU通常通过四联装或八联装搭载进服务器内,并通过多个高性能散热风扇与精心设计的风道来发挥GPU核心的全部性能。

某款基于GPU搭建的服务器渲染图 来源:英伟达
关于GPU服务器,有网友提出过这样一个问题:我用GPU服务器玩扫雷可以稳定60帧吗?
虽说网友提出的问题非常幽默,但我们还是来讨论一下GPU服务器打游戏的可能性。
前面说过,单独的服务器GPU芯片通常没有显示输出接口,但多块GPU桥接后,是可以通过单独的显示输出模块进行视频信号输出的,也就是“加亮机卡”。所以问题的答案是,可以打游戏,但这类GPU运行游戏时性能可能会非常糟糕,因为它们的驱动并不针对图形、游戏进行开发。据了解,单块H100 GPU芯片拥有的图形处理CUDA核心仅500多个,甚至不如多年前的GTX950。
那么除了常用的游戏用独立显卡与服务器显卡之外,有没有一种折中方案,即可以应用于生产力场景,又可以插在普通的PC电脑上呢?
特效师绘图师的神器——专业显卡
专业显卡指的是专门为某些专业应用而优化的显卡,有时也被俗称为制图卡、图形加速卡。专业卡和游戏卡虽然在PCB设计上有部分差别,但两者的GPU芯片是一模一样的。
举例来说,英伟达RTX A6000图形加速卡,与同代游戏显卡一样采用安培架构,基于完整的GA102 GPU核心打造,内含10752个CUDA核心和三代Tensorcore。GA102芯片同时也是英伟达3090与3080的核心。与3090相比,A6000仅在核心频率与显存方面有些不同(还有价格)。

英伟达RTX A6000 来源:leadtek
Lambda网站专门对两款不同领域的显卡进行过横向测试。

来源:Lambda
上图为两块显卡在PyTorch 卷积神经网络训练上的能力对比,单显卡两者互有胜负,只有在增加显卡数量后,两者逐渐拉开差距。显然,A6000为多显卡交火模式进行了特定优化,增加了显卡间数据交换的速度。
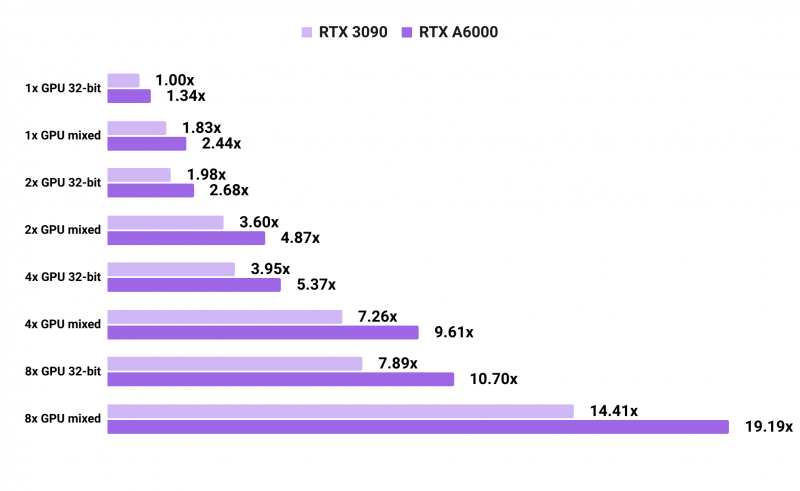
来源:Lambda
在语言模型训练速度方面,A6000要比3090快上不少。所以,专业显卡在生产力方面,尤其是多显卡交火时优势明显。
从显卡参数中可以看出,硬件并不是区分游戏卡和专业卡的主要因素,两者的不同点在于驱动。
由于显卡的应用环境不同,两者的驱动优化也有这不同的侧重方向。消费级显卡主要提升在游戏中的性能,例如英伟达、AMD会与大量游戏厂商共同开发驱动。游戏在不断更新的同时,显卡驱动也跟着与时俱进——消费显卡通常每个月都会推动新的驱动更新包。
对于专业显卡,它们的主要功能是加速生产力软件的运行,通常在Adobe全家桶、CAD、Maya、SolidWorks等专业软件上有特别优化。且为了保持驱动的稳定,更新速度也不像消费显卡般迅速。
总结
希望大家看了这篇文章后至少可以清楚知道GPU的不同种类和应用。
未来GPU的发展方向仍是在图形显示和高性能计算这两大方向上,元宇宙也让我们对这一产品的未来应用充满无限的想象空间。
参考资料:
RTX A6000 vs RTX 3090 Deep Learning Benchmarks https://lambdalabs.com/blog/nvidia-rtx-a6000-vs-rtx-3090-benchmarks/
NVIDIA H100 Tensor Core GPU https://www.nvidia.cn/data-center/h100/
来源: 与非网,作者: 刘浩然,原文链接: https://www.eefocus.com/article/525676.html



.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)
.jpg?x-oss-process=image/resize,m_fill,w_128,h_96)

