

 230
230
在认知科学的坐标系中,1943 年心理学家 Kenneth Craik 首次提出了“内部模型”(Internal Model)的概念:人类大脑之所以能快速应对复杂世界,是因为我们在脑海中装了一个小型的、能模拟现实的机器。当你闭上眼睛,想象“把手边的水杯推下桌子”,你的脑海里会立刻预演出杯子坠落、砸碎、水花四溅的画面。
今天的大语言模型(LLM)就像是一个极其渊博的剧本朗读员,它背诵了无数人类的文字,但文字只是现实世界极度压缩后的“切片”。要想实现真正的通用人工智能(AGI)或具身智能(Embodied AI),AI 不能仅仅停留在“读剧本”,它必须拥有一个能真正搭起舞台、计算引力与碰撞的“脑内物理引擎”——世界模型(World Models)。
当前,整个科技界和学术界正围绕这一概念展开一场人类历史上最高密度的技术军备竞赛。结合最新的学术突破与工业落地,我们可以将全球号称在做世界模型的技术路线,进行一次“去伪存真”的外科手术式切割,深度解构为四大阵营、十大流派。
阵营一视觉与像素生成阵营:经验主义的视觉狂想
这一阵营是彻底的数据经验主义者,也是目前大众感知最强烈、资本最追捧的路线。他们就像是拥有超强记忆力的“文科艺术生”,拒绝硬编码任何枯燥的物理公式,坚信只要看过的视频足够多,AI 就能在暴力压缩海量数据的过程中,隐式地“顿悟”万有引力和流体动力学。
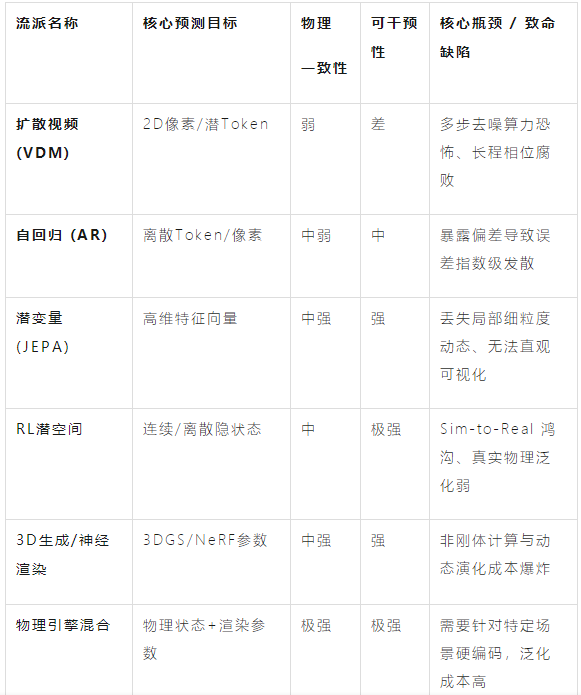
流派1:扩散视频世界模型(DiT/Diffusion-based VDM)
代表选手:OpenAI Sora、Google Veo、Alibaba Wan、NVIDIA Cosmos-Predict
核心信仰:“只要我看过足够多的落日,我就能画出任何光影。”这一流派将视频生成直接等同于世界模拟。
通俗比喻:想象一个从未摸过真实水滴的顶级画师,凭借脑海中几千万张海浪的照片,试图画出水花飞溅的过程。它看起来极其逼真,但画师并不懂流体力学,只是在极力模仿“像素的排列组合”。
数学直觉:优化的目标是在给定历史帧和条件下,最大化生成当前观测的条件概率。
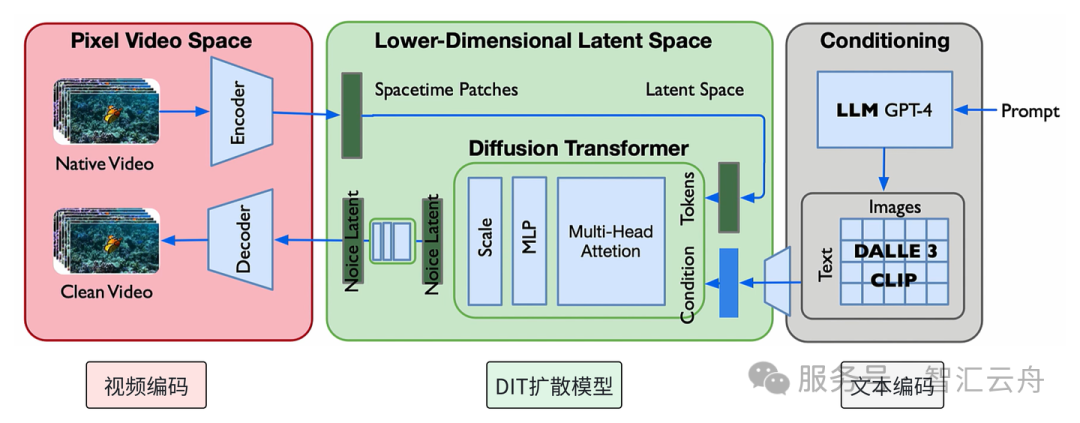
硬伤:物理一致性较弱。外界常误以为 DiT 会被像素级的平方阶计算量卡死,但实际上它们早已通过 VAE 将视频压缩成了低维的时空块(Spacetime Patches)。它原生多步迭代去噪的算力消耗依然显著(尽管近年一致性蒸馏等技术已大幅减少采样步数,但高保真长视频的时空注意力机制仍是主要算力瓶颈)。由于它本质上是在“猜像素”,随着推理步数增加或长程演化,容易出现物理退化(相位腐败)。所以我们经常会看到“左脚踩右脚上天”、杯子碎了又自动愈合这种违背物理常识的“穿模幻觉”。
流派2:自回归交互世界模型(AR/Transformer-based)
代表选手:IRIS、Genie / Genie 2、Wayve Gaia-1
核心信仰:将下一帧预测视为纯粹的语言“下一词预测”(Next-token Prediction)。
通俗比喻:就像是一场极其快速的“你画我猜”接龙游戏。AI 根据当前的画面和你的动作(比如“踩油门”),预测下一帧画面,然后再用这个新画面去预测下下一帧。
技术深潜:无论是生成可交互虚拟 2D 平台的 Genie,还是 Wayve 极具代表性的自动驾驶模型 Gaia-1,它们都在通过输入显式的动作(Action-conditioned)来让 AI 演化未来。像 Gaia-1 这样纯粹用 Transformer 把动作和画面 Token 打包做自回归的模型,哪怕是用在三维的自动驾驶场景上,也无法在后台生成任何 3D 拓扑结构,因此被严谨地归入本流派,而非 3D 渲染派。
硬伤:长程稳定性差。受困于自回归架构致命的暴露偏差(Exposure Bias)——训练时 AI 看的是完美的高清录像(Ground-truth),但推理时,它必须基于自己前一秒生成的、带有微小瑕疵的画面继续推演。这种误差会像滚雪球一样随着时间轴呈指数级发散,走着走着整个世界就坍塌成了一团马赛克。
阵营二 认知与潜空间阵营:理性主义的降维打击
这一阵营对“像素派”极其鄙视。他们认为,现实世界充满了路边随风摆动的树叶、水面的随机反光等无用噪音。每次预测未来都要把这些“废像素”一帧帧画出来,不仅浪费算力,更偏离了智能的本质。真正的智能不在于复刻表象,而在于提取事物运作的抽象规律。
流派3:联合嵌入预测架构(JEPA)
代表选手:V-JEPA 2.1、Causal-JEPA、杨立昆(Yann LeCun)新创立的 AMI Labs
核心信仰:“扔掉无用的像素渲染,真正的因果推理在不可见的高维潜空间里。”
通俗比喻:就像是一个极其硬核的后端服务器(Backend)。它完全不关心前端 UI 界面长什么样(不渲染像素),它只负责在底层高速传递核心的 JSON 业务逻辑(高维向量)。汽车向左打方向盘时,它不生成未来高清视频,而是直接计算“车身与车道线特征数据”的相对变化。图灵奖得主杨立昆坚信这是通向 AGI 的唯一解,并在 2026 年借此斩获超 10 亿美元融资全面押注此路线。
技术深潜:JEPA 完全抛弃解码器。当前帧和未来帧被编码为抽象向量,模型只预测特征的变化。
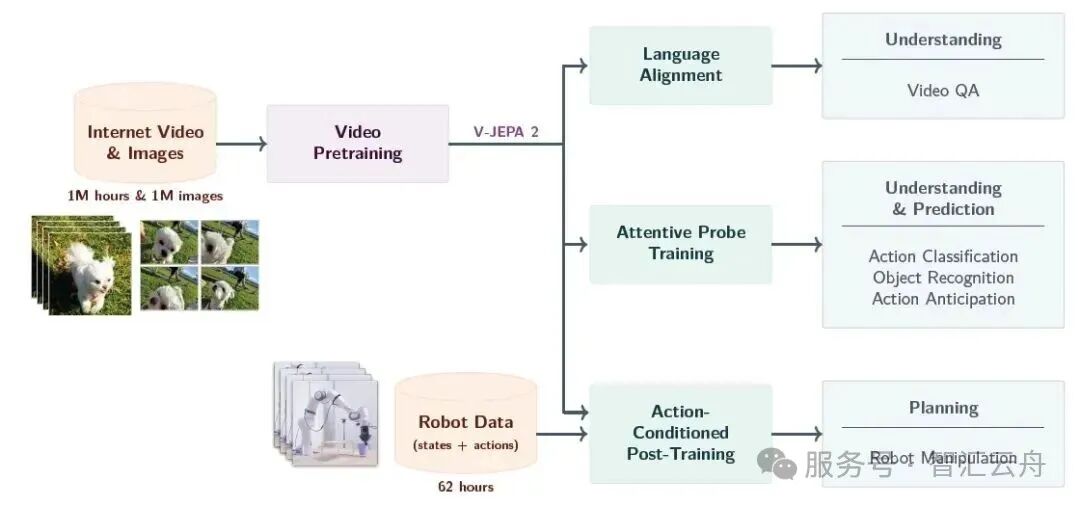
优势与瓶颈: 在数学上,JEPA 通过非对称编码器(Predictor 与 Target 网络)及对目标编码器应用指数滑动平均(EMA)等机制,已经从根本上免疫了把所有输入都猜成 0 的“表征坍塌(Representation Collapse)”。它的真正痛点是局部细粒度视觉动态的丢失——为了追求抽象而主动过滤了大量像素级纹理细节,若遇到“细小针落地”这种在图像层面极其微弱、但在逻辑层面关键的物理事件,潜空间编码若不特意针对该维度进行监督,极易在压缩过程中将其淹没。
流派4:强化学习潜空间世界模型(RL-based Latent WM)
代表选手:DreamerV3、MuZero、SimPLe
核心信仰:建立一个专为机器人活下去、拿高分的“脑内精神游戏厅”。
通俗比喻:就像一个把所有挡风玻璃都涂黑的飞行模拟舱。飞行员(AI)看不见外面的风景(像素),只能盯着仪表盘上的参数(潜空间隐状态)。它在这个虚拟舱里坠毁一万次,摸清了所有按钮对应的后果,最后在现实世界里一次试飞成功。
技术深潜:遵循部分可观察马尔可夫决策过程(POMDP),构建循环状态空间模型(RSSM)。AI 在“梦境里”通过动作和状态预演未来与奖励。
派系细分:纯粹的潜空间试错以 Dreamer 为代表;而SimPLe则代表了 RL 流派中向视觉保真度妥协的“混合过渡态”,它试图在潜空间奖励预测和像素级画面重构之间找平衡,以此来辅助策略的生成。
硬伤:虚拟与现实的鸿沟(Sim-to-Real Gap)。脑补世界中极其微小的摩擦力或伺服电机延迟的偏差,都会导致机器人在现实中彻底瘫痪。
阵营三 空间生成与神经渲染阵营:建构在3D坐标系上的生成派
这一阵营是视觉生成(阵营一)与硬核物理引擎(阵营四)之间极具潜力的过渡态与融合体。他们承认纯 2D 像素预测会“穿模”,但他们同样拒绝像计算物理学家那样去手写枯燥的刚体碰撞公式。他们选择用数据驱动的方式,让大模型自己“长出”对 3D 空间的认知。
如果说视觉生成路线试图通过海量视频学习世界表象,那么空间生成路线则开始尝试建立机器对于三维空间结构本身的理解。这也是近年来“空间智能(Spatial Intelligence)”受到广泛关注的重要原因。在产业界,包括智汇云舟在内的一批空间智能技术厂商,也正在探索基于视频三维重建、实时空间建模与数字孪生技术构建面向真实物理世界的空间认知底座。
流派5:3D空间生成与神经渲染(3D-Spatial Generative/NeRF-based)
代表选手:World Labs(李飞飞团队)、Marble、RTFM
核心信仰:“智能不仅是看懂像素,更是能脑补出物体的背面与深度。”
通俗比喻:他们不是在底层一行行敲代码写“虚幻引擎”。他们更像是一台“用海量数据喂出来的 AI 3D 打印机”。当你给它看一张杯子的正面照,它不会去套用物理圆柱体公式,而是凭借看过千万个杯子的经验,直接“生成(Hallucinate)”出杯子的背面和内部的空洞。
技术深潜:李飞飞提倡的“空间智能”(Spatial Intelligence)正是此流派的灵魂。模型在后台隐式地生成并反向渲染出由3D高斯溅射(3DGS)或NeRF构成的三维立体场景。在这个虚拟世界里,你可以任意从主驾视角切换到上帝视角,背后的空间几何关系由于有了 3D 表征的锚定,不会瞬间崩塌。
从工程实践角度看,这一路线与数字孪生产业的发展方向高度契合。以智汇云舟为代表的空间智能企业,正在通过视频孪生、视频三维重建以及自主可控3D引擎等技术路线,将静态三维场景进一步演进为具备实时感知、动态更新和空间推理能力的数字空间,为未来世界模型提供更加真实的环境载体。
硬伤:运算开销极其恐怖。用生成式的方法去维持一个高分辨率的 3DGS 场景,对于静态的刚体(如建筑、汽车)效果极佳,但如果要求它生成衣服的褶皱、流体的飞溅等非刚体动态,渲染参数的演化复杂度会呈指数级爆炸,目前的算力根本兜不住。
阵营四 硬核物理与科学计算阵营:公理不容亵渎
这一阵营由真正的计算物理学家和传统图形学家组成。他们坚信牛顿、纳维等先贤推导出的物理方程是不可亵渎的,与其让神经网络用海量数据去“瞎猜”物理规律,不如直接把方程当作硬约束写死在系统里。
流派6:物理引擎-神经网络混合(Differentiable Physics+Neural)
代表选手:ContactGaussian-WM、Anima Anandkumar (PINNs 团队)、胡渊鸣 (太极图形)
核心信仰:“引擎负责确定性物理,神经网络只负责计算不确定性。”
通俗比喻:就像在代码里加了最严格的“类型校验”。不管神经网络怎么发散思维,系统底层的“重力参数”被死死锁在 9.8。神经网络只负责去猜那些极其复杂的摩擦力或风阻系数。
技术深潜:将可微分物理引擎作为硬先验嵌入网络。一个碰撞场景,典型混合模型仅暴露约 $10^2$ 个具有明确物理意义的可学习参数(如弹性模量),而纯神经网络流派则包含 $10^6$ 个不透明的权重黑箱。
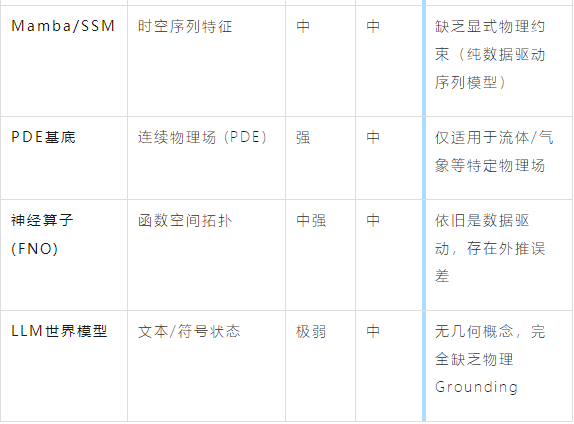
流派7:状态空间模型世界模型(Mamba/SSM-based)
代表选手:FR-Mamba、Video Mamba Suite
技术深潜:利用选择性状态空间模型(Mamba)在长序列建模中的线性复杂度优势,有效降低视频时空推演的算力开销。需要明确指出,其与常微分方程(ODE)的类比仅限于数学构造层面,本身并不自带显式的物理守恒约束,本质仍是一种高效的数据驱动序列骨干网络,常作为其他流派的基础架构组件。
流派8:PDE/反应-扩散动力学世界模型(PDE-based Substrate)
代表选手:FluidWorld
通俗比喻:拒绝用 AI 去“猜”风怎么吹,而是直接把流体力学的绝对真理(偏微分方程)塞进大脑,让 AI 变成一个带有物理直觉的超级计算器。
流派9:神经算子世界模型(Neural Operators)
代表选手:FNO (傅里叶神经算子)、FourCastNet
技术深潜:学习无限分辨率的函数空间映射。它在频域执行全局积分操作,在气象预报、科学计算中实现了相比传统流体力学方法10的五次方倍的恐怖加速。
流派10:大预言模型世界模型(LLM-as-WM)
代表选手:Language World Model (LWM)、GPT-4o(辅助推理)、Generative Agents
技术深潜:完全把环境状态隐式维护在 LLM 的超长上下文中。动作为工具调用,世界反馈为结构化的描述。需要严格指出,像 GPT-4o 这样的模型虽然能做惊艳的多模态物理推理,但缺乏对连续物理空间中力学交互的原生微分建模,它属于通用大模型对物理世界的“兼职推测”,而非原生交互世界模型。它缺乏物理 Grounding,知道“水杯掉地上会碎”,但算不出碎片的真实弹射轨迹。
终局:从黑箱走向分层的架构觉醒
在今天,世界模型的技术进化呈现出一个极其明确的趋势:从“端到端黑箱”走向“状态与观测的分离”。
最具里程碑意义的工程实践方向,当属以 2026 年 NVIDIA Cosmos 系列为代表的工业级探索。值得关注的是,这种分层架构思路不仅出现在AI基础模型领域,也正在数字孪生和空间智能产业中逐渐形成共识。例如智汇云舟等企业正在探索“空间底座+认知推理+场景应用”的技术体系,通过高精度空间建模、实时数据融合与智能推演能力的结合,为世界模型提供更加稳定的现实映射基础。工业界开始放弃单模型包揽一切的想法,探索将系统拆分为:Reasoner(推理器,侧重于底层潜空间物理推演)+Generator(生成器,侧重于扩散或 3D 视觉渲染)的前后端分离架构。这就好比现代软件工程中最成熟的前后端分离架构:
Reasoner(后端):吸取了阵营二(JEPA/RL)的思想,负责在底层高速处理业务逻辑和物理隐状态推演。
Generator(前端):吸取了阵营一(VDM)和阵营三(3DGS)的优势,只负责将最终的物理结果漂亮地、符合光影逻辑地渲染给人类肉眼看。
结语:造飞机的四种终极融合
如果把通往真正 AGI 物理感知的大路比作建造一架飞机:
视觉生成派是在观察了几百万只鸟之后,试图用极其庞大的算力在屏幕上“画”出一对能飞的翅膀,虽然看着极其逼真,但一吹风就会羽毛错乱;
抽象潜空间派完美推导了空气动力学的底层核心逻辑,却极度理智地不屑于制造精美可视的机身外壳;
3D空间生成派在脑海里用 AI 魔法“打印”了空间结构完美的机身,但在复杂的非刚体气流面前发现算力消耗过大;
硬核物理与混合派则直接拿出了物理教科书和风洞,精细控制着每一个零件的咬合,绝不容许任何超出物理定式的越界。
行业已经达成共识:世界上没有世界模型的“单一银弹”,只有复杂的系统级分工。真正的下一代世界模型,必然是一个分层混合架构——用物理引擎锁死确定性的边界,用 JEPA 在潜空间进行因果规划,用 3D 打印机建构拓扑结构,最终仅在需要向人类展示时,调用扩散生成器去渲染像素。这不仅是一场算法的迭代,更是一场重新定义智能计算边界的工业革命。


