

 233
233
通常情况,一款只能语音类产品在正式上市之前,在技术层面上需要多方配合,通常每一块领域都有专门擅长的团队提供技术,这个在之前做智能音箱产品介绍的时候有单独提过。
接下来关于智能音箱常用架构做一些参考说明,首先介绍如下常用词:

ASR:Automatic Speech Recognition
NLP:Natural language processing
TTS:Text-to-speech
STT:Speech to text
分别为语音识别,自然语言处理,文字转化为对话,以及对话转换为文字。
那么在智能音箱的实际架构上,首先,用户与智能音箱之间的交互,通过ASR完成,也就是音箱上的麦克风通过数据处理判断用户在说话,并通过唤醒词,或功能唤醒词等确认用户是在向音箱发送指令。常用语音助手指令例如Alexa,Cortana,Siri等等,都是专门经过唤醒词训练的。语音唤醒在学术上被称为keyword spotting(简称KWS),它指的是在连续语流中实时检测出说话人特定片段。语音唤醒系统的评测标准通常包括误识率和拒认率两个部分。 误识率指用户未发出命令,但系统却错误的被唤醒的情况。拒认率指用户发出了唤醒命令,但系统却没有相应的情况。误识率和拒认率越低,证明系统越稳定。
这里额外提一下,唤醒词(wake up words)的存在是为了方便用户更好的向智能音箱传输指令,那么为了避免噪声,数据处理不完全,有口音和发音问题等因素,我们需要针对这个唤醒词做系统训练,以便能够更加方便唤醒,并避免误唤醒的情况。通常,市面上唤醒词训练公司针对一个唤醒词的模型训练量大概5000~8000,而通常训练数据也有精细数据,和粗略数据(后者训练效果可能没有前者号),举例如下一种非常基本的唤醒词模型训练方案:
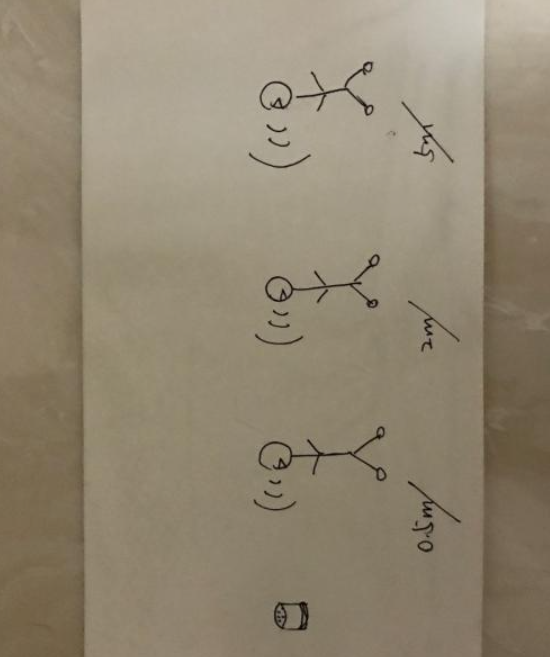
既,用产品本身的麦克风模拟实际的收音现场,用户分别在不同的距离面向产品,以三挡语速念出唤醒词。当然,粗略数据也可以找很多人,用手机麦克风简单录制数据,因个人的发音,语速,音调均会有所不同,因此也能起到训练意义。
硬件本身被唤醒之后,接下来麦克风将开始“倾听“用户说话,目前有很多方案是将对话内容生成wav录音文件直接上传至云端,开始进行STT,也就是将一段音频转换为一段文字,数据信息从wav文件变成了text文件形式,但是此时我们还并不知道用户意图,这一段文字目前仅仅是text形式文件而已,接下来text会进入下一个阶段,也就是NLP处理(自然语义理解),自然语言处理(英语:Natural Language Processing,缩写作 NLP)是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。自然语言处理的主要范畴包括中文自动分词、词性标注、句法分析、自然语言生成、文本分类、信息检索、信息抽取、文字校对、问答系统、机器翻译、文字蕴涵、命名实体识别等。
目前比较专精在中文NLP供应商有三角兽、蓦然认知、图灵、灵犀等;(其他很多同样积累NLP技术的公司,但是可能提供了可提供麦克风阵列、语音唤醒、语音识别、语义理解、语音合成等一系列语音技术,甚至平台技术,故不做此列)
这里既接入另外一个概念, Named Entity Recognition (NER) 命名实体识别,简单了解既讲一段文字进行分词,用于进一步的文本意图理解,概念介绍如下:

那么,很多接触过NLP的小伙伴们也大概了解,很多公司在NLP领域做专门研究,国内目前也很有多机构正在做相关研究,具体可以参考此篇文章:NLP(中文)团队研究
目前专精于NLP的团队的技术背景,通常需要有搜索引擎以及百科类知识图谱的框架。难点也在于,很多名词指向的内容分类有可能是多方面的,既可能是音乐类,也可能是百科,闲聊,有声读物类,故而在区分意图方面需要经常调整架构,这也是那句“人工智能靠人工“的调侃由来吧。
总之,理解了用户的意图,并给出准确的回答这一套逻辑,最终,生成了给到用户的完整回答。比如,现在时间是XX;马上为您播放周杰伦的《晴天》live版等等;并在云端将文字转换成音频,也就是我们常说的TTS(语音合成),它是将人类语音用人工的方式所产生。文字转语音(text-to-speech,TTS)系统将一般语言的文字转换为语音。
目前国内的主流语音合成方案有科大讯飞、搜狗、云知声、思必驰等。
而语音合成目前市面上一般使用参数合成,或者拼接合成,前者的音库都是在10小时左右,基本用不到20小时,对于合成人声效果的自然度,更依赖算法,而拼接则对于数据的需求量很高,对合成人声效果的自然度,更依赖数据量。很多听起来很自然的音库时长在100~200小时左右。
以及,TTS模型通常也会分为中文,英文,或者中英混输的。做训练的文本,有很多文字比较拗口,故而对录音声优的功力有要求,中英混输的模型数据就更难了。如果是普通的中文TTS模型,以刚才的例子“马上为您播放周杰伦的《晴天》live版本”,这种就可以在录音时加入一些简单的字母,单词,短语等等。
合成的wav文件回传到终端音箱,并播放出来,如此,完成了一环基础的用户与智能硬件之间的对话。
P.S.这里单独介绍一个常与自然语言处理弄混的概念:Neuro-linguistic programming (NLP)
通常用于我们说的机器学习,或者神经网络处理,通常是指我们通过Sigmoid函数尝试模拟人脑神经之间传递并处理信息的方式。关于Perception以及Sigmoid函数的概念区别,后面会单独做一个相对生动的举例来做说明,总体的信息处理模式非常类似于我们电路常用与或非门,这一部分(模拟计算机处理),在《三体》里面有更加生动的描述,非常有趣。





