

 425
425
数日前,SimilarWeb更新了一份关于聊天机器人ChatGPT访问数的数据统计。数据显示,2023年4月ChatGPT访问量再创新高,已经超过了必应、DuckDuckGo等其他国际搜索引擎,也超越了纽约时报和CNN等知名网站;目前ChatGPT访问数已经达到百度搜索引擎的60%,谷歌搜索引擎的2%。

图1:ChatGPT访问数据统计(图源:SimilarWeb)
当然,不光是ChatGPT,近一段时间以来,全球科技巨头纷纷发布自己的大模型。北京时间5月11日,谷歌宣布推出最新大型语言模型PaLM 2,在部分任务上已经超越GPT-4;在中国市场,百度、360、阿里、华为、京东、腾讯等也都纷纷推出了自己的AI大模型。
访问量陡增的ChatGPT,加上纷至沓来的AI大模型,AIGC(人工智能生成内容)产业不仅带来检索效率和工作效率的提升,同时由于大模型需要大量的数据和算力进行训练和运行,并在使用过程中产生大量新的数据,因此对底层基础设备提出了更高的要求。
在数据传输方面,光通信行业市场调研机构Lightcounting曾在2021年时预测,800G光模块将从2025年底开始主导市场。如今,在GPT等大模型的带动下,这一节奏明显提前。市场消息显示,目前已经有云服务厂商开始集中测试和采购800G光模块,相关需求将在2023年下半年开始集中爆发。
800G以太网需求提前爆发
为什么头部云服务商如此重视800G以太网用以数据传输呢?
最直接的回答就是:为了应对数据大爆炸。就以AI大模型训练而言,公开数据显示,从GPT-1到GPT-3,模型的参数量从1.1亿个增长到了1750亿个。有传言称,GPT-4模型的参数达到5000亿个,甚至可能超过万亿规模。根据市场调查机构TrendForce的数据,如果以英伟达A100显卡的处理能力计算,GPT-3.5大模型需要2万块GPU来处理训练数据。
因此,在算力集群的超算中心里,先进芯片和先进算力之间并不是划等号的,算力芯片只是提供了算力,而要高效利用算力还需要依赖光模块、存储等芯片的支持。
如下图所示,这是中国移动在《算力网络白皮书(2021年版)》中分享的一张算力网络体系架构。在这个结构中,中国移动将其分为算网底座、算网大脑、算网运营三个部分,其中在算网底座这部分,全光底座是行业的共识。因此,先进算力实际上是遵循“木桶效应”的,算力、存储和网络传输三大核心环节,一个出现短板,整个系统的性能就会出现巨大的下滑,这便是为什么云服务商积极部署800G以太网光模块的原因。
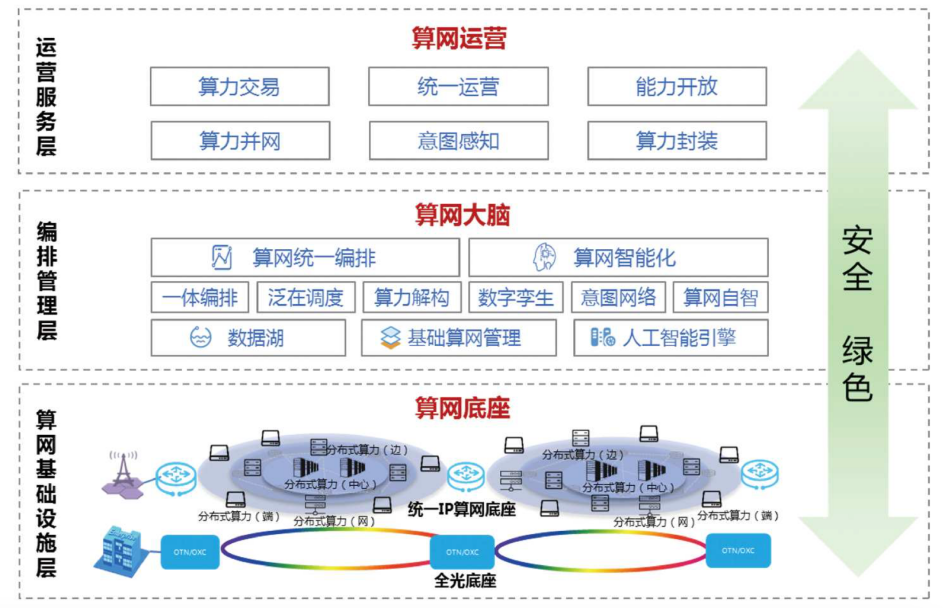
图2:先进算力网络框图(图源:中国移动)
目前,已经有多家方案商表示已经完成800G光模块送样量产。供需大幅度提前让LightCounting修改了自己在2022年的预测,该机构在今年3月份最新预测中表示,虽然今年整个以太网光模块市场将出现10%的下滑,但是800G光模块市场将在2023年维持高速增长。
当然,不光是800G光模块,在交换机芯片和交换机整机方面,产业也是快速跟进。2022年8月,博通正式发布自己的Tomahawk 51.2 Tbps交换机芯片;在2022年OCP全球峰会上,思科发布了两款新的800G交换机系列——Nexus 9232E和8111交换机,以及带有100G和400G接口的800G光模块。如下图所示,过去12年里,交换机的交换能力已经从640G发展到102.4T。
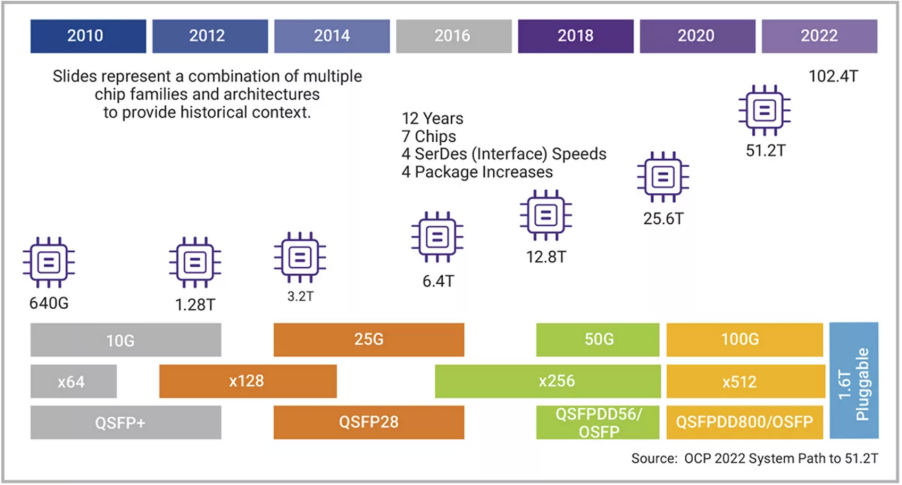
图3:交换机容量扩张年表
800G以太网的优势
当前,芯片厂商如博通等,设备厂商如思科等,云服务商如亚马逊等,围绕着高性能计算、5G和深度学习等产业积极向800G以太网过渡。
对于高性能计算和深度学习训练等领域而言,800G以太网具有两大突出的赋能价值。其一是在同等算力规模下,800G以太网能够带来倍增的计算效率。通过以太网技术联盟发布的800GBASE-R规范可以看出,800G以太网是400G的延伸和扩展,最直观的改变是带宽是此前400G以太网的两倍。如下图所示,端到端的以太网通信实际上可以抽象为这种连接,如果交换机全部端口从400G升级到800G,那么交换机传输容量将直接翻倍。

图4:端到端800G以太网实施用例
其二是能够进行更大规模的算力集群。我们都知道,算力网络最底层的算力底座一般会分为算力基础设施和网络基础设施,两者融合使得目前的数据中心和算力中心呈现出一种类似叶脊的架构。结合下图来看,这是Facebook构建的树形数据中心网络架构,名为data center fabric网络架构,里面的连接无处不在。
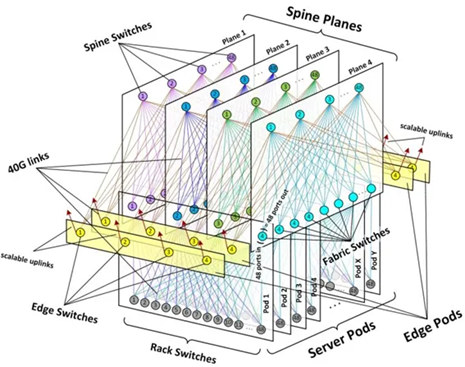
图5:4层data center fabric网络架构(图源:Facebook)
从上图的上方不难看出,data center fabric网络架构是一个四层结构,也被成为“F4结构”。不过,Facebook在2019年已经将其升级为“F16结构”,原因是数据暴涨和设备更新让“F4结构”已经难以适应。
参考下图来看,“F16结构”明显是更大规模的算力集群,连接数量和服务器数量都更多。预计这个结构很快也会更新,因为在2019年Facebook认为400G并不成熟,所以只支持了100G以太网,如今800G已经步入商用,这个集群规模显然太小了。
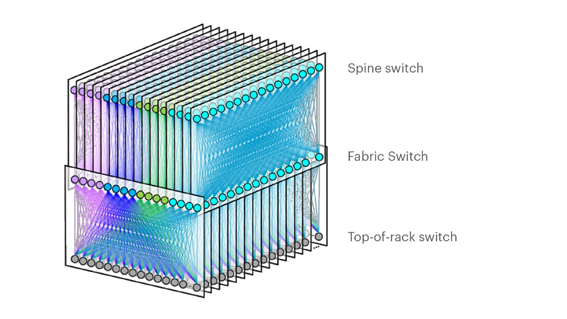
图6:16层data center fabric网络架构
(图源:Facebook)
800G以太网的部署挑战
在具体实现的过程中,800GBASE-R规范并非是简单地将两个400G拼接在一起,而是引入了新的介质访问控制(MAC)和物理编码子层(PCS),能够以最小的成本实现800G。由于新的PCS包含对之前PCS的重用,因此保留了标准RS(544, 514)前向纠错,并提供了很好的向后兼容特性。
下图是800G Pluggable MSA工作组在《800G MSA白皮书》中给出的示意图,这是一种能够快速上市的800G实现方案,通过重新调整两个400G的PMA,进而得到一个800G的PMA,再定义一个低成本的800G的PMD,最终实现基于8通道100Gb/s技术的800G以太网。
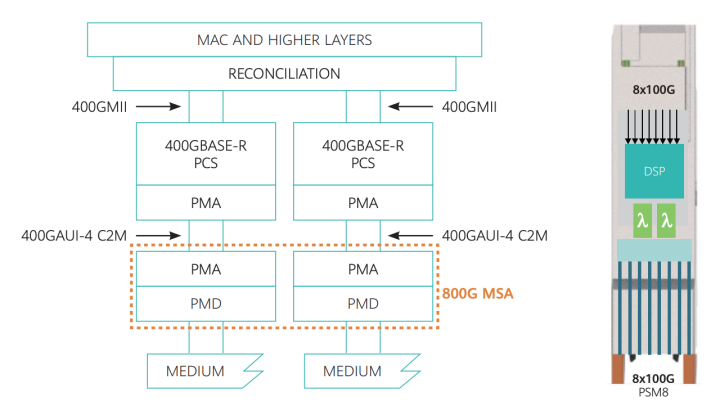
图7:800G SR8方案系统框图(图源:MSA)
当然,为了继续向1.6T以太网进化,MSA工作组在白皮书中指出,后续800G会通过每通道200G PAM4技术进行优化,并且DSP芯片会采用更先进的工艺制程,因此这是一种更加低功耗、低延迟的解决方案。不过,如MSA工作组所言,这种实现方式实际上是为了从800G向1.6T过渡,是一种未来式的实现方式。

图8:800G FR4方案框图(图源:MSA)
虽然系统框图都已经很清晰,不过要完成800G交换芯片的设计还是会遇到很多挑战。
首先,第一个显著的问题是,800G并不是简单的两个400G叠加,那么MAC、PCS和PMA被集成之后,如何保证整个系统能够实现最佳的性能和延迟。
下图展示的是一个800G芯片的设计框图,对于这款芯片而言,信号完整性、电源完整性等方面的测试只是基础,重点是如何系统性优化beachfront、SerDes、PCS和MAC这些块分区。如果是在交换机芯片研发设计的过程中,又会分为单裸片方案、双裸片方案和Chiplet三个不同的类型,需要考虑的因素都不同。比如在Chiplet配置方式里,需要考虑如何更好地进行模块划分,如何进行参考时钟布线等。

图9:具有8通道100G Serdes的800G芯片示例图
为了保证在各种实现方式中,整个芯片的信号一致性和低延迟,就需要一种高效的FEC,用以补偿更快传输速度下必然伴随的更高错误率。
第二个挑战是芯片功耗和面积难题。目前800G芯片采用的是112G SerDes或PHY技术,进而打造成一款并行处理能力强和时钟速度快的硬件。虽然采用先进制程,不过为了保证良率,芯片面积不能过小。然而,在交换机中,器件的集成度只会越来越高,因此合适的芯片尺寸是一个非常值得考究的问题;另外,高速芯片必然伴随功耗问题,如果功耗过高就需要在交换机中加入额外的、昂贵的冷却系统。
第三个挑战也来自112G SerDes或PHY技术,那就是如何做到更好的跨信道传输。为了让各个112G SerDes或PHY之间具有最小的串扰(xtalk)影响,在芯片实现的过程中往往会采用增加封装层数,以满足高速SerDes或PHY串扰规格,这必然会带来更高的成本挑战。同时,多层封装也需要考虑南北(N/S)、东西(E/W)方向进行封装出线的问题。
因此,如果要打造一款高性能的800G芯片,就需要拥有用于优化beachfront、SerDes、PCS和MAC设计的专业知识,同时对时钟布线、封装出线和Chiplet等有深刻的认识。如此,才能够打造出一颗完美的800G芯片。
新思科技800G以太网方案
看到了挑战和要求,可能对一些想要从事800G以太网芯片研究的人进行了劝退。为了帮助大家应对这些挑战,新思科技提供了业界唯一完整的200G/400G/800G以太网IP解决方案。
作为全球以太网IP开发的领航者,新思科技能够为业界提供经过硅验证的800G以太网IP方案。我们上面提到,800G是基于112G SerDes或PHY技术进行实现。新思科技112G以太网PHY IP解决方案可实现真正的长距离、中距离、极短距离和超短距离(LR、MR、VSR、XSR)接口,以及CEI-112G-Linear和CEI-112G-XSR+光接口,是支持实现800G光模块和800G交换机的理想方案。
早在2021年1月,新思科技就已经推出经过硅验证的采用5纳米FinFET工艺的112G以太网PHY IP,提供超出IEEE 802.3ck和OIF标准电气规范的卓越信号完整性和电气性能。研发人员借助这款PHY IP能实现高集成度的800G以太网芯片,拥有显著的性能、面积和功耗优势。这款IP主要用于长距离和中距离接口,能够在大于45dB的信道中以低于5pJ/bit实现出色的BER(误码率)。
另外,用于极短距离接口的新思科技112G以太网PHY可以在大于20dB的信道中以低于3pJ/bit的速度实现出色的BER;用于超短距离接口的新思科技112G以太网PHY可以在大于10dB的信道中以低于1.4pJ/bit实现出色的BER。
这些PHY IP全部都支持在芯片的四个边缘进行布局和堆叠,最大限度地提高每个芯片边缘的带宽。它们都支持脉冲幅度调制4级(PAM-4)、不归零(NRZ)信号和独立的每通道数据速率,并以极高的灵活性支持PCI Express®、DDR、HBM、Die-to-Die、CXL和CCIX等广泛的连接协议。
为了使研发人员能够加速基于以太网设计的验证收敛,新思科技还推出了用于以太网的VC VIP,提供一套全面的协议、方法、验证和生产力功能。
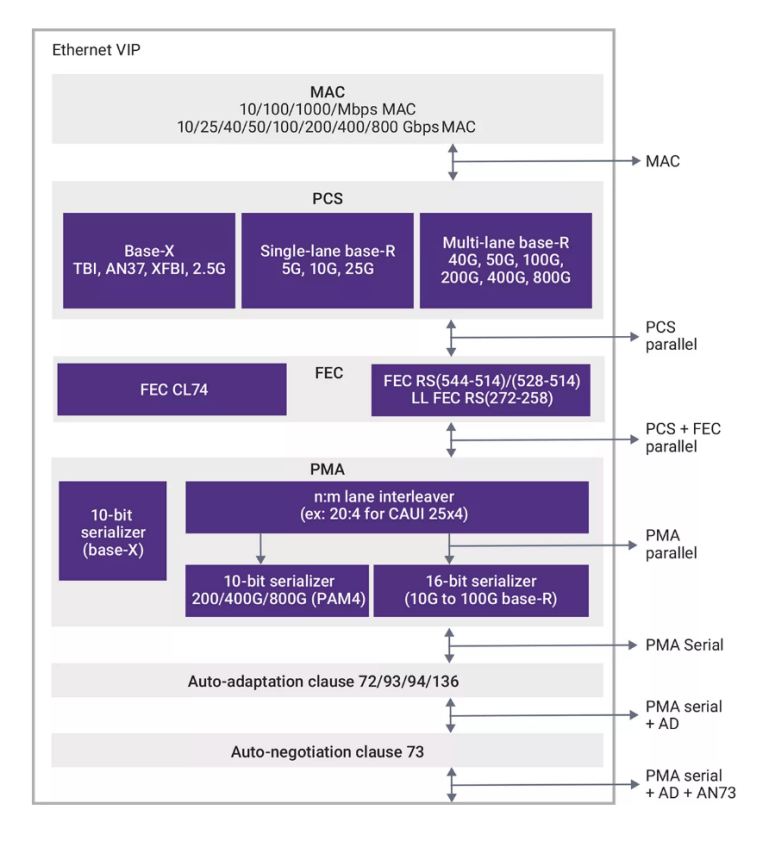
图10:新思科技以太网VIP
通过这些IP和VIP,再结合新思科技在路由可行性研究、封装基板指南、信号和电源完整性模型以及串扰分析等方面的全面经验,研发人员可实现高速可靠的800G芯片开发。
当然,在此还需要额外提到,新思科技112G以太网PHY是该公司广泛的IP产品组合中的一部分,新思IP产品组合包括逻辑库、嵌入式存储器、嵌入式测试、模拟IP、有线和无线接口IP、安全IP、嵌入式处理器和子系统,对高性能HPC应用进行全方位的赋能。
结语
AIGC产业的爆发进一步带动了800G以太网的需求。通过引入全新的MAC和PCS,800G以太网找到了当前最经济理想的实现方案——8通道112G SerDes或PHY技术。不过,要把800G SR8方案系统框图兑现到具体的800G芯片中,依然面临着性能、功耗、面积和信号完整性等多方面的挑战,帮助大家克服这些挑战,便是新思科技112G以太网PHY IP和以太网VIP的价值所在。






