

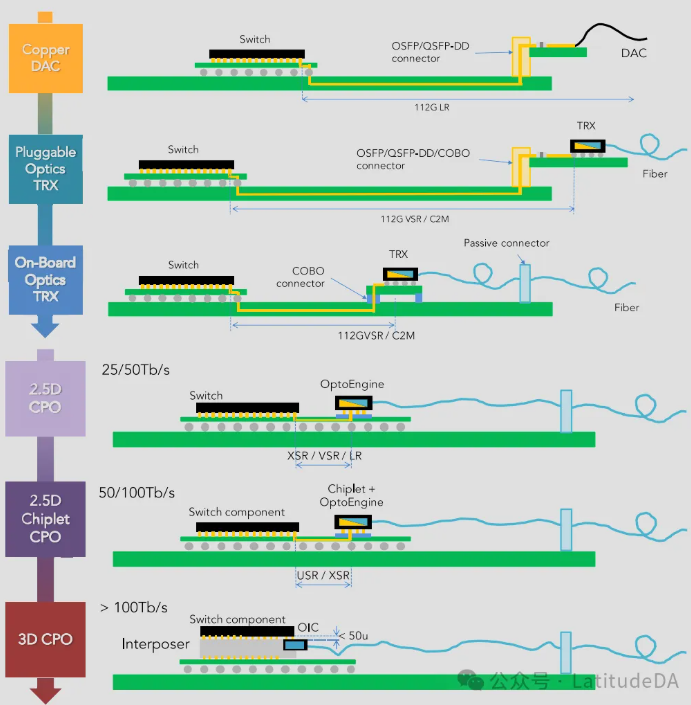
 121
121
电信号的瓶颈、光的物理优势、大模型如何倒逼光互连,以及你手机里的每一次AI对话,背后都藏着一条光路。
你有没有想过,当你在AI大模型里输入一个问题,点击发送,到屏幕上弹出答案,这短短一两秒里,数据跑了多远?
答案是:可能跑了几百公里。
你的问题被封装成网络包,从手机通过Wi-Fi或5G传到运营商骨干网,一路狂奔到云数据中心的GPU集群。集群里成千上万颗芯片协同计算,生成结果,再原路返回。这条“数据长征”中,真正承载信息的,不是铜线,不是同轴电缆,而是比头发丝还细的玻璃丝——光纤。
为什么非用光不可?为什么电信号不行?
一、电的“天花板”:传不远、传不快、传不稳
在数据中心内部,芯片之间、服务器之间、机柜之间需要交换海量数据。早期短距离互联用铜缆(DAC,直连铜缆)就行,但随着速率不断提升,电信号的物理瓶颈越来越明显。
衰减问题:电信号在PCB板或铜缆中传输时,电阻和趋肤效应会不断消耗信号能量。速率越高,频率越高,衰减越剧烈。10Gbps以上信号,在普通PCB上走几十厘米就需要中继放大;到了100Gbps、200Gbps,铜缆的有效传输距离被压缩到几米以内。
功耗问题:为了对抗衰减,需要用更强的驱动器和更复杂的均衡电路(如DSP),这些电路本身消耗大量功耗。高速SerDes(串行解串器)在112Gbps速率下,单通道功耗可轻松突破1W,交换机面板上几十个通道加起来,发热量惊人。
电磁干扰:高频电信号会像天线一样向外辐射噪声,互相串扰,信号完整性急剧恶化。为了屏蔽干扰,铜缆必须做得又粗又重,布线极其困难。
简单说,电信号在“高带宽 × 长距离”这个二维坐标系里,只能占据短距、低速那个角落。一旦速率突破100Gbps、距离超过数米,电就“喊不动”了。
二、光的“降维打击”:低损耗、抗干扰、高带宽
光纤中的光信号,工作机理完全不同。
全反射原理:光纤由芯层(高折射率,掺锗的SiO₂)和包层(低折射率,纯SiO₂石英玻璃)构成。光进入芯层后,在芯包界面发生全反射——入射光全部反射回芯层,几乎没有能量泄露。这就好比光在一条镜面管道里反复弹射前进,损耗极低。
极低衰减:石英光纤在1550nm窗口的典型损耗只有0.2dB/km。什么概念?一公里只衰减4.5%,99%以上的光功率能完整到达。相比之下,同速率电信号在铜缆上走100米就几乎不可识别。
巨大带宽:光纤的工作带宽在数十THz量级,单根光纤通过波分复用(WDM)可同时传输上百个波长,单通道200Gbps、400Gbps正在商用,实验室已突破单纤Pbps级传输。
抗干扰强:光信号不受电磁干扰,也不对外辐射,不同光纤之间天然隔离,布线极其灵活。
所以,光解决了三个核心诉求——传得远、传得快、传得稳。
三、AI大模型,把光通信逼上了“刚需”位置
如果只是普通互联网应用,电信号勉强还能凑合。但AI大模型的崛起,彻底打破了平衡。
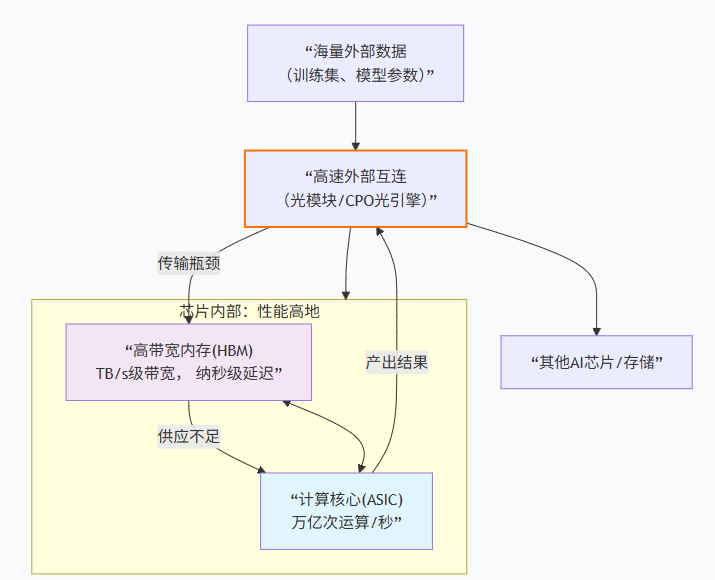
三大矛盾,我们展开讲讲:
矛盾1:HBM容量远远不够
一个千亿参数的大模型,光模型权重就占据几百GB存储空间,加上训练过程中的梯度、优化器状态、激活值,总内存需求轻松突破1TB。而单颗GPU的HBM(高带宽内存)通常只有80GB(如H100)或141GB(如MI300X)。哪怕是最顶级的GPU,也装不下整个模型和数据集。
所以,训练时必须频繁从外部存储(NVMe SSD、CPU内存)或其他GPU节点调入/调出数据。这些数据一旦离开芯片内部总线,就必须通过网络传输——而网络传输的物理层,正是光模块。
矛盾2:并行训练需要芯片间频繁同步
大模型训练不是单卡能完成的,必须把模型切分到成千上万颗GPU组成的集群上并行训练。典型的分布式训练(如数据并行、模型并行、流水线并行)中,每张卡每轮迭代都要交换梯度、激活值等中间结果,进行全局同步。
这些交换在芯片内部通过HBM和NVLink(NVIDIA的片间高速互连)完成,带宽可达900GB/s以上。但一旦数据要发给另一个机架、另一台服务器里的GPU,就必须离开芯片,走交换机、走光模块、走光纤——整个过程全靠光互连支撑。
矛盾3:物理距离与带宽的严重不匹配
数据中心内部,同一个机柜里的服务器距离几米,不同机柜间可能几十米,不同房间可能上百米。电信号铜缆(DAC)最多支撑3-5米的可靠传输,超过这个距离就严重失真。而AI集群往往横跨多个机柜、多个机房,铜缆根本无能为力。
此外,如果外部数据供应带宽跟不上计算核心的需求,再强的GPU也得“饿肚子”——利用率大幅下降。光互连的作用,就是确保数据“粮道”永远畅通。
HBM解决了“计算核心与内存墙”的内部矛盾,而光模块/光引擎解决了“芯片与外部世界”的外部矛盾。两者缺一不可,共同支撑起AI算力。
四、你手机里的AI,靠的是远方的光
像DeepSeek、ChatGPT这样的AI应用,工作模式是:
模型训练:在云数据中心,用成千上万张NVIDIA H800/A800/H100或华为昇腾等AI芯片组成超大规模集群,在海量数据上训练数月,耗电巨大。这一步绝对不可能在手机或普通电脑上完成。
模型部署与推理:训练好的模型被部署在云端服务器的GPU或专用推理芯片(如NVIDIA L4、华为昇腾)上。当你打开App提问时,App本身不包含大模型——它只有一个交互界面和网络通信代码。
云端交互:App把你的语音或文字打包成网络请求,通过API调用发送到云端服务器。服务器上的GPU集群运行模型推理,生成答案,再把结果通过光纤网络传回你的手机。
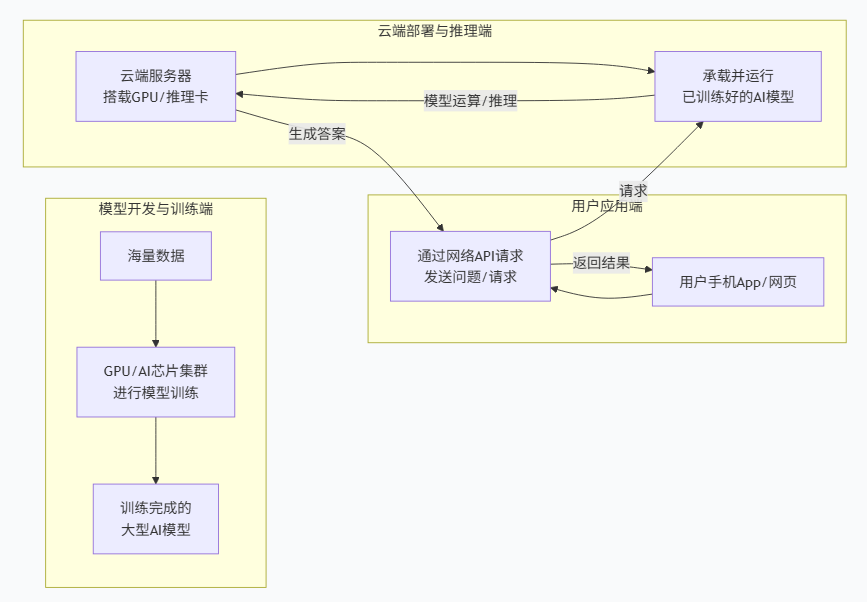
整个过程,你的问题变成电信号,电信号变成光信号,在光纤里跑几百公里,到GPU算完,再变成光跑回来,最后变成文字显示在屏幕上。你感觉不到延迟,但光已经奔波了数千公里。
这就是光通信在AI时代的价值——它不是锦上添花,而是生存刚需。
结尾预告
看完应用场景,相信大家已经明白光通信的产业价值。但光通信的核心载体 —— 光模块,如今也在经历技术迭代:从传统分立器件光模块,到集成度更高的硅光模块,技术路线正在发生巨变。 下一篇,我们将深入拆解传统光模块与硅光模块的技术差异、优劣势以及成本对比,带你看懂当下主流的两大技术路线。




