

 852
852
高端GPU作为通用计算的“加速神器”,日渐成为大型数据中心、人工智能、超算等领域的刚需。长期以来,英伟达在高端GPU市场占据主导地位,市场占有率一度超过90%。目前来看,国内企业突破英伟达等国外公司的垄断仍然任重道远,但国内基于架构创新的DSA(特定领域架构,即针对特定领域的可编程处理器)芯片产品日渐丰富,可能会带来一些曙光。
高端GPU与传统GPU“泾渭分明”
20世纪90年代,Play Station等游戏主机的发布和彩色显示器的出现,催生了3D游戏的萌芽。而彼时的3D制作主要依靠计算机的CPU执行,计算任务需要串行排队,难以满足游戏画质的提升需求。英伟达的GeForce 256,将“GPU”概念推向市场。自此,光线追踪等图形图像处理任务有了专用芯片承载,在提升3D画质的同时,也提升了计算机的整体效能。
随着超算等高并发性计算需求不断增长,GPU用于计算任务的可能性受到业界关注。英伟达首席科学家David Kirk认为,GPU的浮点运算和并行计算能力不应该局限于图像渲染。在他的倡导下,英伟达以推动GPU从专用计算芯片走向通用计算处理器为目标,推出了GPGPU(即通用GPU),并于2006年发布并行编程模型CUDA。GPGPU与CUDA组成的软硬件底座,构成了英伟达引领AI计算的根基。
由于GPGPU专注高性能算力,也常常被业界和市场称为“高端GPU”,并发展出与传统GPU“泾渭分明”的应用路径。燧原科技产品市场部总监陈超向《中国电子报》记者指出,传统GPU聚焦图像学,关注帧数、渲染逼真度、对于真实场景的映射程度等指标,主要用于运行游戏、专业图像处理、加密货币处理等场景。而高端GPU是用于计算加速的芯片产品,专注于基础科学等超算领域和训练、推理等大规模人工智能计算场景。
2022年第二季度独立GPU市场(包括AIB 合作伙伴显卡)份额
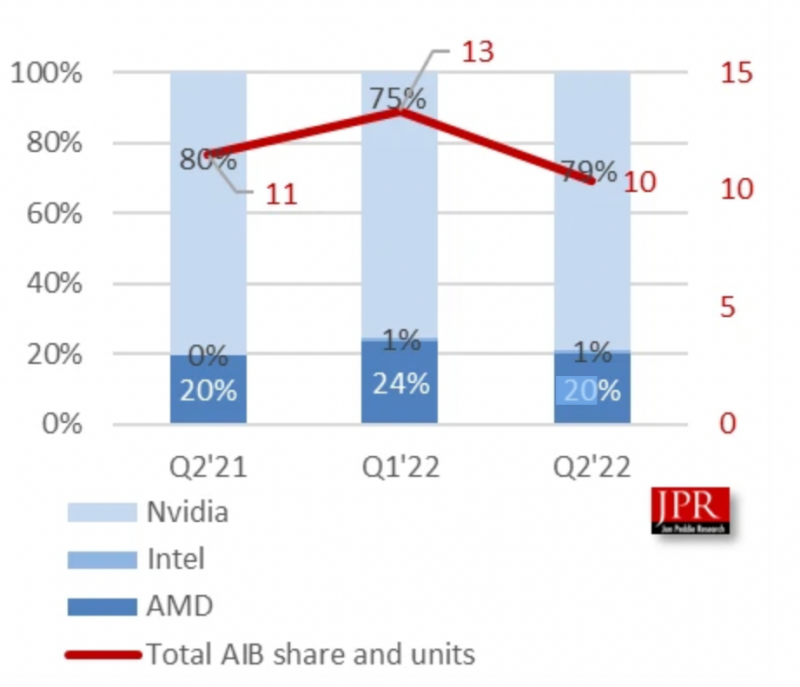
来源:Jon Peddie Research
“高端GPU不涉及消费级GPU的场景,纯粹用于计算加速。高端GPU早期用于超算等高性能计算场景,真正的蓬勃兴起并大规模产生一些商业行为,是在人工智能迅猛发展产生了强有力的算力需求之后,GPU被大量应用于人工智能场景,特别是人工智能训练。”陈超向记者指出。
目标不同则指标不同,高端GPU有着与传统GPU不同的关注点。昆仑芯科技CEO业务助理宋春晓向《中国电子报》表示,衡量高端GPU的主要维度是通用性、易用性和高性能。通用性指硬件架构要有足够的灵活性,以适应人工智能不断迭代变化的算法和场景。易用性是指较低的开发门槛,让开发者更容易上手,结合实际场景进行定制化的开发。高性能指芯片产品的基础性能和性价比要对标国际先进水平,才能进行市场开拓。
算力大小往往是市场对GPU性能优劣的“第一印象”。但高端GPU的性能不等于纸面性能,尤其不能以单一性能的纸面数据来衡量。
“在实际使用的过程中,GPU的通用性、易用性、实际性的重要程度远大于纸面标出的算力这一单一性能。纸面指标标得再高,也要关注内存和带宽够不够,以及芯片之间的互联等问题解决得好不好。用单一性能来衡量GPU是否高端,是一个常见的误区。”宋春晓说。
硬件性能最终要通过软件接口被开发者感知和使用。芯动科技GPU项目总监何颖对《中国电子报》记者表示,高端GPU设计的算力,需要专门优化过的驱动和加速库。只有软硬协同,才能把高端GPU的算力真正应用到实际场景中。
高性能计算将是主要“竞技场”
长期以来,英伟达在高端GPU市场占据主导地位,市场占有率一度超过90%,在人工智能计算领域尤其具备垄断性优势。迄今为止,英伟达推出了面向高性能计算和AI训练的Volta、Ampere、Hopper等架构,并以此为基础推出了V100、A100、H100等高端GPU,面向向量的双精度浮点算力从7.8 TFLOPS一路来到30 TFLOPS。
市场优势的建立,归功于英伟达GPU产品能力的均衡和生态的完善。
“英伟达在通用性、易用性和高性能三个方面做得比较均衡,加上英伟达在每一代架构上都有所创新,为软件承接大模型训练和推理场景的人工智能计算提供了持续提升的硬件基础。”宋春晓说。
“人工智能对于生态的要求非常高,涉及框架、应用、模型的适配等,英伟达率先基于CUDA生态将上下游打通,对于下游的算法开发商和服务商来说,它的GPU在性能具备优势的同时还保持了易用性。”陈超表示。
作为全球第二大独立GPU供应商,AMD虽在高端GPU的整体份额与英伟达存在差距,却在超算领域闯出了一片天。在最新全球超算TOP500榜单上,世界上最快的超级计算机橡树岭国家实验室(ORNL)Frontier、世界排名第三的超级计算机LUMI,都采用了AMD EPYC处理器和AMD Instinct MI250X GPU加速器。
AMD在超算领域的亮眼表现,是建立在针对性的软硬件设计上,基于CDNA 2架构的GPU加速器、ROCm软件平台与开源应用程序资源中心AMD Infinity Hub的组合,构成了对于科研人员更加友好的硬件性能和编程环境。
“超算涉及许多科研探索性质的计算任务,AMD开源的软件格局为科学家探索新的计算方式提供了更多可能和便利。”陈超表示。
“AMD针对架构和适用场景做了更细分的设计,使GPU产品能够更多地应用于科学计算场景,因为他们的双精度做得比较好。”宋春晓表示。
但高性能计算和AI计算并不能与GPU划等号。陈超指出,高性能及AI计算本质上具有四项基本要求。一是高精度,尤其高性能计算对于FP64双精度浮点有着较高的需求;二是高性能,以满足面向超大数据量的信息处理要求;三是并发计算,大大缩短信息处理全流程延时;四是软件易用性,能支撑更广泛的应用场景,且易于编程和开发。
“虽然直接采用GPU进行高性能或AI计算较为便利,但上层应用降本增效的核心诉求对底层算力提出了更高要求,国外AI创企推出的AI芯片往往基于全新的架构,对并行计算能力进行全面提升和重点优化。国内相关的AI芯片领先企业同样推出了一系列基于DSA架构的人工智能计算芯片,也是出于同样的考虑。”陈超说。
在国内市场,基于架构创新的DSA芯片产品日渐丰富。例如华为面向AI计算特征的自研架构达芬奇,昆仑芯科技推出的一代架构“XPU-K”和二代架构“XPU-R”,燧原科技的自研架构“GCU-CARA”已进入规模落地期。随着AI计算的应用场景越来越细分和复杂,定制化、异构化的DSA有望在下一代计算平台中发挥更大效用。
架构和软件是攻克高端GPU的核心要素
无论是高端GPU,还是同样以优化并行计算效率为核心的各类DSA芯片,都有着技术、人才、资金密集的特征,研发难度不容小觑。
在采访中,三位受访者均表示,架构设计是攻克高端GPU的核心要素。
架构设计具体难在哪里?首先是各项能力的均衡性。宋春晓表示,架构设计的通用性、易用性和高性能构成了“不可能三角”。如果优先保障通用性,兼顾各个场景,就难以在某一个场景进行足够的定制化以提供更高性能。如果找到了一种兼顾通用性和高性能的路径,将是一个跨度较大的架构创新,生态上要推倒重来,易用性会受到很大影响。
“在架构设计过程中,一方面注重有哪些巧思能够在这个‘不可能三角’中尽可能达到平衡;另一方面也要充分理解市场、客户的需求,比如客户在什么情况下,能够在通用性、易用性、高性能的哪一点去做到什么程度的取舍。了解这些情况之后,才能设计出合理、均衡、契合需求的架构。”宋春晓告诉记者。
其次是指令集设计。“指令集是硬件的灵魂。指令集的多与少、高效与否,对于芯片架构以及微架构有着重大影响。如果指令集设计巧妙,芯片架构会更加高效,客户做开发时也能在应用、开发效率、性能、成本方面获得较为均衡的支持。”陈超说。
此外,架构设计对于芯片企业在产业链理解能力和技术积累上提出了更高要求。
“硬件架构层面上,高端GPU的构成极其复杂,涉及先进工艺层面的超大规模集成电路设计。头部公司积累了大量专利,对后来者构筑了极高的技术壁垒。”何颖说。
高端GPU的另一个门槛是软件生态。可以说,软件决定了GPU生态的能力上限,也是硬件能力充分释放和灵活调度的必要条件。
“高端GPU需要厂商提供高度优化的驱动,以及各种加速库和相关的文档,以支持用户纷繁复杂的使用场景。此外,终端用户需要厂商提供功能强大的工具以辅助问题诊断和性能调优。”何颖表示。据悉,芯动科技推出的风华系列GPU已经兼容了OpenGL4.3,并支持微软Windows10 DirectX图形框架。
在完成硬件设计和软件栈构建的基础上,还要考虑芯片的工程实现。陈超表示,高端计算芯片对于算力性能的要求非常极致,往往会用到最先进的工艺和封装技术,运行时钟的频率也非常高,需要考虑功耗对于环境和运行可靠性的影响。同时,也要考虑芯片的生产良率。
“良率直接影响高端GPU的成本,这个成本会最终体现到消费端,影响算力成本的高与低。所以良率是高端GPU工业化、商业化落地中非常重要的因素。”陈超说。
除了产业链环节本身,人才作为研发的生力军,也是高端GPU研发水平的决定性因素。
“国内专业对口人才相对稀缺,需要在2~3年甚至更长的培养时间里,有持续投入和资金支持。我们非常注重国内外人才的积累,以保障研发基础和创新迭代的能力,同时也有利于新生代的培养,进一步夯实人才基础。”何颖说。
作者丨张心怡
编辑丨陈炳欣
美编丨马利亚
监制丨连晓东




