

 1.8万
1.8万
对于人形机器人来说,延迟就是生命线。没有强悍的端侧大脑,再智能的算法也无法落地,再精密的机械关节也只是“木偶”。本文就来梳理一下人形机器人产品采用的主流端侧算力芯片有哪些,最新动态如何。
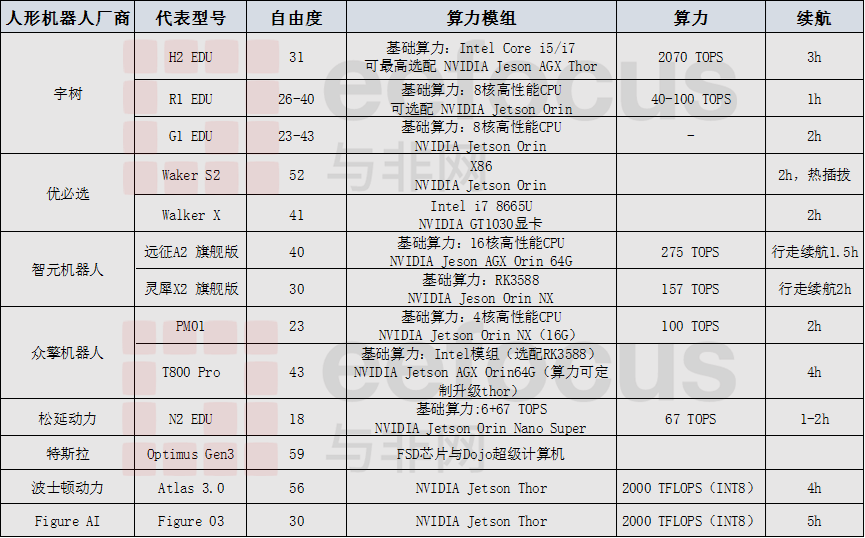
NVIDIA Jetson平台,性能引领
无论中国还是海外人形机器人厂商,其核心人形机器人产品的算力模组大多采用NVIDIA的Jetson产品,如宇树科技的G1/R1/H2,优必选的Walker S2,Figure Ai的Figure 03等。
NVIDIA Jetson是功能强大的、紧凑型的,面向边缘AI和机器人开发平台。其JetPack SDK,提供预构建软件服务,可快速推进复杂的边缘AI应用开发,涵盖机器人、生成式AI和计算机视觉领域。NVIDIA Jetson模组提供适合各种性能水平和价位的加速计算功能,从而能够满足各种自主应用的需求:
NVIDIA Jetson Thor是为物理AI和人形机器人打造的高性能平台。该系列模组可提供高达2070 FP4 TFLOPS的AI计算性能和128GB显存,功率可配置在40-130W之间。与NVIDIA AGX Orin相比,Jetson Thor系列模组的AI计算性能提高至7.5倍以上,能效提高至3.5倍。它是为了生成式AI专门设计的,能够让机器人像人一样实时进行语义推理。
Jetson Thor系列基于Blackwell架构,于2025年8月发布。该系列包含旗舰版T5000和效能版T4000。其中,Jetson T5000模块于2025年8月正式发售;Jetson T4000在2026年1月的CES 2026大会上,正式上市并开放订购。
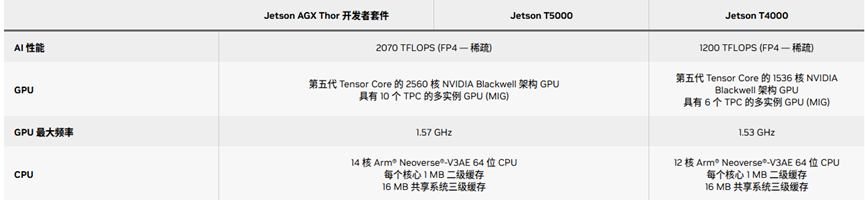
图:NVIDIA Jetson Thor系列规格,图源:Nvidia官网
NVIDIA Jetson Orin系列包含7个具有相同架构的模组,可提供每秒高达275万亿次运算的算力,其性能是上一代多模态AI推理的8倍,并支持高速接口。其强大的软件堆栈包含预训练的AI模型、参考AI工作流和垂直应用框架,可加速生成性AI的端到端开发,以及边缘AI和机器人应用。
- Jetson AGX Orin模组可提供高达275 TOPS的AI性能,功率可在15-60W之间进行配置。此模组的外形规格与Jetson AGX Xavier相同,但其性能可高达后者的 8倍以上。Jetson AGX Orin有64GB、32GB和工业版三个版本。
- Jetson Orin NX模组极其小巧,但可提供高达100 TOPS的AI性能,功率可在 10-25W之间进行配置。此模组的性能可高达Jetson AGX Xavier的3倍、Jetson Xavier NX的5倍。Jetson Orin NX有16GB和8GB两个版本。
- NVIDIA Orin Nano系列属于入门级产品。模组外形小巧,可提供高达40 TOPS的AI性能,功率可在7-15W之间进行选择。此模组的性能可高达NVIDIA Jetson Nano的142倍。Jetson Orin Nano有8GB和4GB两个版本。

图:NVIDIA Jetson Orin系列规格,图源:Nvidia官网
高通Dragonwing,极致能效比
2026年初,高通凭借Dragonwing(骁龙翼)品牌完成转型,成为人形机器人端侧算力领域的有力竞争者,其专为该领域及高级自动化设计的端侧芯片,清晰划分成IQ系列(旗舰、工业级)与RB系列(开发、中端级)两大产品线,依托在移动芯片领域的技术积淀,发力布局下一代机器人市场。
旗舰型号Dragonwing IQ10系列于CES 2026发布,直接对标英伟达Jetson Thor,被称作“人形机器人大脑”。该芯片最高达700 TOPS AI性能且针对VLA大模型优化,搭载18核自研Oryon CPU,支持20路以上摄像头并行接入,安全岛达SIL-3级功能安全标准,目前已被Figure集成至其通用机器人架构中。高通IQ10采用4nm先进制程工艺。该制程为其18核Oryon CPU、Hexagon NPU与Adreno GPU提供了坚实的能效基础,在实现700 TOPS AI算力的同时,相比前代功耗降低约40%,并能在-40℃~115℃的工业宽温环境下稳定运行。
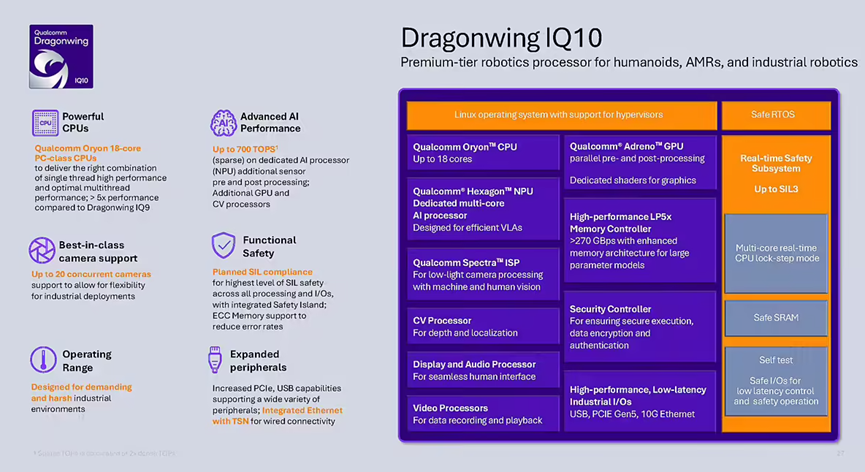
图源:高通
IQ9系列作为此前主力,适配中端人形机器人与工业AMR,可本地运行130亿参数大语言模型,功耗比英伟达同级别产品低30%,适配高续航需求的服务型机器人。
Robotics RB5/RB6系列则聚焦开发级与中端市场,是开发者和初创公司的主流选择。其中RB6算力70-100TOPS,多用于四足机械狗、室内递送机器人;RB5算力15 TOPS,虽性能非顶级,但7-10W的极低功耗,使其成为机械臂末端控制等轻量化机器人部件的优选,覆盖了中低算力场景的多样化需求。
值得一提的是,在2026年1月的CES大会上,Figure宣布将在后续的大规模量产版本中集成高通IQ10,主要因为IQ10在能效比上的卓越表现,比竞品低约30%-40%,这对需要全天候工作的通用人型机器人至关重要。此外,VinMotion在CES 2026上, 也展示了搭载高通技术的Motion 2人型机器人。
英特尔,第三代酷睿Ultra for Edge
在2026年初的机器人市场中,英特尔已经凭借其酷睿Ultra 3系列(Panther Lake)芯片,正式杀入了人形机器人的端侧算力战场。不同于英伟达纯粹的GPU路径,英特尔走的是“通用CPU+AI加速”整合至单颗SOC。英特尔表示,基于Panther Lake的嵌入式系统预计将于2026年第二季度开始出货。
酷睿Ultra 3系列采用英特尔18A(2nm级)工艺,功耗覆盖15–65W,兼顾性能与续航。芯片集成CPU、Xe3 GPU与NPU 5架构,AI总算力达180 TOPS,虽峰值算力不及英伟达Thor,但在ROS 2等X86传统逻辑代码执行上效率突出。
英特尔同步推出Robotics AI Suite软件套件,推动“一芯多用”落地。传统机器人常需分别用芯片处理运动控制与AI视觉,而酷睿Ultra 3可同时承担关节实时控制与环境感知AI任务,简化硬件架构、降低整机复杂度与成本。
目前该方案已落地的典型产品是在CES 2026大会上意大利Oversonic Robotics的RoBee人形机器人,应用于医院与工厂场景。依托英特尔芯片的本地算力,RoBee实现亚秒级语音交互与障碍物规避,展现出端侧AI在实时性、可靠性上的明显优势。
特斯拉AI5,闭环自研
2026年第一季度,特斯拉正式展示人形机器人量产型号Optimus Gen 3,核心搭载专为机器人与自动驾驶打造的自研Tesla AI5(HW 5.0)算力芯片,其AI推理算力较前代HW 4.0提升约10倍,成为该机型的核心技术支撑。
这款芯片具备独特架构优势,内置Transformer算法专属加速硬件单元,可本地运行Cortex端到端神经网络,不仅让机器人能集成xAI的Grok实现实时语音对话,更赋予其即时物理推理能力,从单一处理器升级为兼具交互与推理的智能算力核心。
Optimus Gen 3在硬件设计上也实现大幅升级,全身拥有50余个自由度,核心亮点是全新灵巧手,自由度从Gen 2的11个提升至22个,模拟人类肌腱结构可完成弹钢琴、整理易碎衣物等精细动作;同时电池包完成优化,续航能力实现突破,可支持约8小时的持续作业。
国产力量,奋起直追
地瓜机器人
地瓜机器人在人形机器人领域的核心产品是以旭日智能计算芯片和RDK(Robot Development Kit)机器人开发者套件为核心,提供了5-128 TOPS多层级的智能计算平台。

图源:地瓜机器人发布会
2025年11月21日,在地瓜机器人开发者大会上,公司发布了具备560 TOPS算力的S600具身智能机器人开发平台。其采用高效灵活的大小脑架构设计并进行了深度优化,大脑配置18核A78AE CPU和全新BPU Nash,可支持VLA、VLM、LLM、Locomotion多种具身大模型算法端侧高效部署;小脑配置6核R52+MCU,专为人形机器人优化,具备高可靠、实时的运动控制能力。该款算力平台于2026年Q1上市。
值得一提的是,2025年6月11日,同样是在深圳,地瓜机器人正式对外发布了算控一体开发平台RDK S100,彼时,地瓜机器人已经将具身智能开发平台的算力拉升到了128 TOPS。
黑芝麻智能
2025年11月20日,黑芝麻智能正式推出面向机器人产业的SesameX多维智能计算平台,这是业界首个机器人商业化专属部署平台,标志着黑芝麻智能的发展路径从智能驾驶扩展到包含机器人的具身智能产业。
SesameX的最底层计算平台是由自研的Kalos、Aura、Liora三款模组组成,配套运行Ubuntu,ROS2和黑芝麻智能自研的SesameX RTOS系统。
- SesameX Kalos专为配送、清洁、巡检等商用低速轮式服务机器人打造,主打极致性价比与成熟度,是SesameX平台中最易落地的机器人中枢。拥有48 TOPS INT8 NPU算力,运控一体化设计,支持8路1080p视觉感知,工业级模组仅69×55mm,集成SoC、内存等核心组件,兼容主流接口与生态,可快速部署,大幅降低开发成本与周期,已在星程智能物流车实现商业化落地。
- SesameX Aura适配四足机械狗、协作机械臂、工业巡检机器人及轻量人形机器人,主打感知与行动能力的平衡,是高性能异构计算平台。具备70 TOPS INT8 NPU算力,搭载多核异构运控处理器,支持12路1080p/4路4K多模态同步采集,配备TSN万兆口、PCIe Gen4等高带宽接口,工业级模组82×54mm,融合多模态感知与安全控制,能实现精准行动,已应用于云深处、深庭记的四足/轮式机器人产品。
- SesameX Liora(旗舰级)专为通用人形机器人打造的全能计算平台,是SesameX的旗舰款“机器人大脑”,主打高阶具身智能推理。拥有近600 TOPS超高算力,采用CNN与Transformer超融合架构,支持世界模型与端到端控制,可同时处理语音、视觉、触觉感知及复杂行为决策,支持24路1080p视觉输入,能让机器人实现自主思考、预测与决策,适配服务/教育人形、双臂协作、情感交互等高阶具身智能机器人场景。
虽然在“大脑(通用人工智能推理)”算力上不如英伟达,但瑞芯微是目前国产机器人的“小脑(运动控制)”与“边缘感知”最不可或缺的底层基座。其RK3588系列凭借8核CPU和成熟的Linux/ROS 2适配,能够以极高频率处理平衡算法(MPC)、足端轨迹规划和电机扭矩控制。提供6 TOPS的内置NPU算力,通常用于处理基础的视觉避障、手势识别或简单的语音指令分析。
2026年1月27日,瑞芯微在其首届AI软件生态大会上,重磅介绍了业内首颗3D叠封AI芯片—RK182X系列协处理器,并公布了RK1820(2.5GB带宽)与RK1828(5GB带宽)两颗芯片,该系列带宽较RK3588提升30倍,可大幅降低数据传输功耗,兼具高性能、低时延、高输出、高精度优势。
RK182X平面“计算层”采用2x4多核Mesh结构,立体层面则叠封1或2层“存储层”DRAM,层间有数万IO互联。这种3D叠封设计带来的带宽与功耗优势,为各类算法提供了更强物理底座,可推动性能-功耗前沿整体外推,同时支持W4A16等LLM适用数据类型,能高效满足3B、7B等端侧主流模型的本地化部署需求。得益于这一创新设计,RK1820具备20T算力。
产品规划方面,瑞芯微预告2026年Q2将推出进阶版RK1860,其拥有64 TOPS稠密算力及8K视频解码能力,涵盖2.5GB/5GB/10GB多存储版本且支持LPDDR存储扩展,可适配3B~13B模型并实现级联运行;而中远期的RK1899,目标算力250+TOPS,这标志着瑞芯微将正式进入“大脑”市场,直接挑战英伟达Orin甚至Thor的中端市场。
天数智芯
2026年1月,天数智芯推出彤央系列边端侧AI算力产品,作为人形机器人“大脑”端侧算力芯片,是英伟达方案的优质国产替代选择。该系列含TY1000、TY1100、TY1100_NX、TY1200四款,算力为实测稠密算力,覆盖100-300 TOPS,超英伟达Orin系列,其中TY1200算力达300 TOPS,为具身智能核心支撑。

图源:天数智芯
产品核心优势是兼容CUDA生态,算法可与英伟达Orin丝滑切换,迁移成本低,适配国内企业开发现状;且实测中TY1000在计算机视觉、具身智能VLA模型等多场景性能优于英伟达AGX Orin。同时产品兼具高性价比,采用自研GPGPU架构,硬件配置强悍,部分型号还支持多路视频编解码,小巧易部署,适配人形机器人端侧算力需求。
写在最后
人形机器人端侧算力芯片领域已形成多元竞争格局,海外巨头凭借性能与生态领跑,国产力量加速追赶。从极致性能到高性价比,从通用方案到专项优化,各厂商精准布局不同场景。随着技术持续突破与场景深度适配,行业将逐步实现算力分层适配、软硬协同升级,国产芯片有望在差异化竞争中突破瓶颈,推动人形机器人端侧算力领域向更成熟、更普惠的方向发展。
本文由与非网原创,转载请注明以上来源。如有投稿爆料采访需求,请发邮箱dezhi.shi@cn.supplyframe.com,或添加微信号Derek--Shi,谢谢!
来源: 与非网,作者: 史德志,原文链接: https://www.eefocus.com/article/1968422.html








