

 682
682
从传统芯片一统产业的时代走来,AI芯片的发展并非一帆风顺,泡沫充斥、资本遇冷、人才稀缺……不过,在半导体产业整体步入下行周期的2022年,AI芯片反倒扛住了争议和质疑,在服务器、汽车等领域显现出了日益放大的价值效应。
2022年的这三大技术和应用趋势,有望成为AI芯片未来几年的关键动力:
一、智能算力反超通用算力规模
当前,我国通用算力的数据中心仍是市场主力,按机架规模统计,占比超过90%。随着我国高性能计算、AI计算及边缘计算需求提升,超算中心、智算中心及边缘数据中心将进一步发展,特别是智算中心,正在从早期实验探索逐步走向商业试点。
IDC数据显示,2022年我国智能算力规模达到268 EFLOPS,超过通用算力规模。预计未来五年,我国智能算力规模的年复合增长率将达52.3%,超出同期通用算力规模18.5%的年复合增长率,到2026年,我国智能算力规模将达到1271.4EFLOPS。
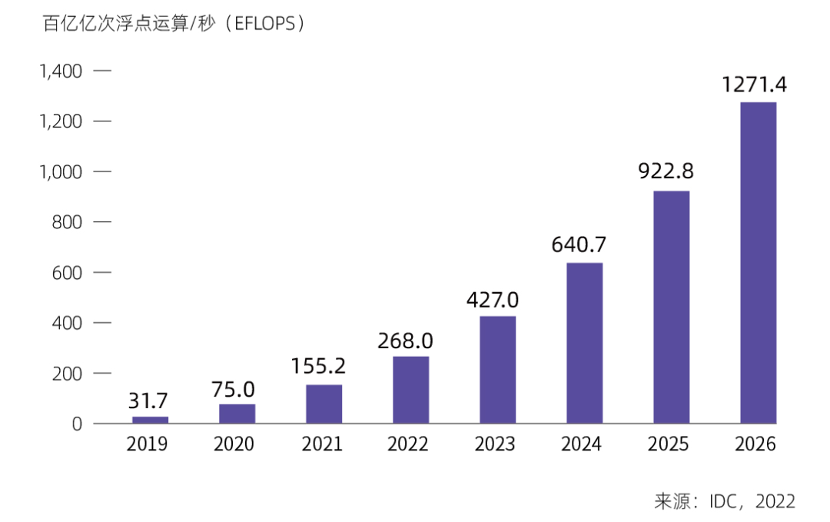
中国智能算力规模及预测(2019年-2026年)
同时,边缘计算需要处理的数据量会越来越多,算力要求也将逐步提高。边缘侧的设备也不再拘泥于简单的数据采集,还会有大量的边缘网关、边缘AI、边缘可扩展型服务器等设备,协助前端数据处理,将处理后的数据传输给云端,有效减轻云端的数据压力,用户也可根据自己的实际业务,灵活就近选择边缘计算节点或中心云计算节点。
边缘计算场景大致有两条路线:一是高性能通用处理器做专用设备,为场景提供专用算力;二是高度集成化、低功耗化的SoC芯片,通过自主设计降低功耗的同时,可实现中低端边缘计算设备的户外现场应用,可大量部署在工业等现场。这些方案也可以叠加AI芯片、FPGA等,针对某类场景提供定制化算法,提升边缘计算的能力。
从AI芯片角度来看,随着AI产业技术不断提升,产业AI化加速落地,全球AI芯片市场将高速增长。IDC预计,到2025年AI芯片市场规模将达726亿美元。异构计算成为主流趋势,未来18个月,全球AI服务器GPU、ASIC和FPGA的搭载率均会上升,算力多元化发展趋势明显。
从计算架构发展来看,基于 DSA( Domain-Specific Architectures)思想设计的AI芯片正在成为主导,推动了AI芯片的多元化发展。此外,多元算力从“能用”到“好用”并且为企业创造业务价值,离不开通用性强、绿色高效、安全可靠的计算系统的支持。业内正在推动多元算力系统架构创新,基于计算节点内和节点间的互联技术破局现有计算架构的瓶颈,通过充分调动起多芯片、多板卡、多节点的系统级能力,实现各种加速单元以及跨节点系统的高效协同,提升计算性能。
从场景应用维度来看,智能化场景将随着时间的推移,呈现出更加深入、更加广泛的趋势。
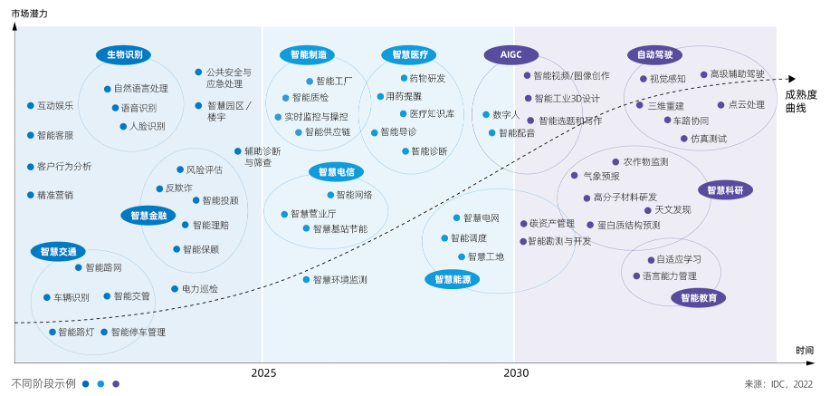
AI应用场景发展
二、大算力自动驾驶芯片走向巅峰对决
从神经网络计算推动自动驾驶大行其道开始,到走向高阶的辅助驾驶感知方案,随着自动驾驶级别的提升,所需要的算力几乎是指数级爆炸式的增长,从L2、L3、L4走向L5,每向上走一级至少有10倍以上算力需求的提升,大规模并行化的AI计算,使得大算力的计算平台成为了产业必须,在提升有效算力的道路上似乎永无止境。
Gartner数据显示,预计到2025年,全球汽车AI芯片市场将以31%的年复合增速飙升至236亿美元。其中,中国汽车AI芯片的市场将达到68亿美元,2030年为124亿美元,年复合增长率预计可达28.14%。
暴增的算力需求下,主机厂纷纷推动“硬件预埋”概念。走向L4级别自动驾驶甚至L5级无人驾驶究竟需要多大算力才够?目前业界并没有定论,但几千TOPS的有效算力支撑被认为是需要的。
国内市场方面,地平线征程5已经成为国内首款实现前装量产的百TOPS大算力AI芯片,这款芯片对于地平线自身、以及我国大算力芯片的发展都具有重要意义。如果把自动驾驶大算力芯片的竞逐比喻为世界杯,地平线征程5与英伟达算是率先进入百TOPS芯片前装量产的阶段,相当于“提前锁定了决赛席位”。
不过今年10月,英伟达推出的芯片NVIDIA Drive Thor,直接把标杆又拉高了一个级别,这款超级芯片可实现最高 2000TOPS AI 算力以及 2000 TFLOPS 浮点算力。据官方介绍,NVIDIA Drive Thor是第一个使用集成推理Transformer引擎的自动驾驶汽车平台,借助Transformer引擎,它可将 Transformer 深度神经网络的推理性能提升9倍,这对于支持与自动驾驶相关的、庞大且复杂的AI工作负载至关重要。
在通往自动驾驶的路上,Drive Thor肯定不会是AI芯片终结者,不过它在2022年出现的意义在于:第一,将智能汽车带到中央计算模式。此前业界对于智能汽车芯片的设计思路基本上是自动驾驶芯片负责自动驾驶,座舱芯片负责车载娱乐,而未来融合是趋势,Drive Thor单芯片舱驾一体的设计,或将加速中央计算时代的到来。第二,它将汽车芯片算力直接推向了2000TOPS标准。提升计算效率是汽车智能化发展的关键一环,因为实现更高级别的自动驾驶、实现更智能的人机交互座舱体验都需要更强的算力。按照iHS Markit预计,2024年座舱NPU算力需求将是2021年的十倍,CPU算力需求是2021年的3.5倍,这都要求汽车芯片的算力必须进一步拉高。
在汽车AI芯片方面,存算一体的大算力AI芯片也在发力。这方面的从业者认为,相比于传统的冯·诺依曼架构,用存算一体技术做大算力AI芯片,对先进制程依赖度不是很强,可以用较低的制程实现较大算力,并且由于数据计算和数据存储深度融合,避免了大部分数据的无效搬运,可以兼顾成本和能效,因此非常适合智能驾驶和自动驾驶应用场景。
三、AI大模型推动算力集群效能优化
最近爆火的OpenAI旗下的对话模型ChatGPT,能够理解用户需求创造内容、协助代码编写、能够针对用户的追问在后续对话中进行修正或补充。相较于苹果 Siri、微软小冰等,ChatGPT除了逻辑严密的创造能力之外,还具有记忆能力,在连续的对话中无需用户提供重复信息,语言组织和表达能力也更接近人类水平,使对话更自然流畅。
同样火热的还有AIGC(Generative AI,生成式AI),一系列初创公司融资不断,并且在实际应用中也体现出了较高的水准。百度AI十分钟内复原了《富春山居图》残卷,浪潮“源”支持的“金陵诗会”,使用者可一键创作韵味悠长的诗句……而除了自主生成文本、图像,AI自主生成音频、视频、虚拟场景等也在成为热潮。这些都推动了生成式AI的蓬勃发展,打造了新的数字内容生成与交互形态。
Gartner将“生成式AI”列为2022年五大影响力技术之一,预测到2025年,生成式AI所创造的数据可占到所有已生产数据的10%。
业内认为,ChatGPT和AIGC爆火,代表着AI大模型进入一个新的技术范式,同时也是第三波AI浪潮经过十几年发展之后,到达了一个非常重要的拐点。
它们代表着从以前的“大炼模型”(各自研发专用小模型),到“炼大模型”(研发超大规模通用智能模型)的一个范式转变,其意义在于:通过这种比较先进的算法架构,尽可能多的数据汇集大量算力,通过集约化的训练模式,从而供大量用户使用。
AI发展至今,大模型的出现可以说是生逢其时,它将碎片化的AI应用开发转向集中式开发。一方面,AI大模型具备很好的泛化能力,一个模型可以支撑各类不同应用,有效缓解碎片化开发反复建模的困境;另一方面,围绕AI大模型构建的算法基础设施,比如开放的API、开源的应用代码等,使开发者无需关心底层技术,设置无需配置编程环境,就可以直接将应用构建于AI大模型的能力之上,在降低开发门槛的同时,让开发人员将更多精力聚焦在核心业务逻辑上。
从算力的角度来看,挑战不可谓不大。因为训练大模型所需要的算力是海量的,成本是高昂的,这就需要发挥AI算力集群的整体效能,让AI算力能够“算”尽其用,从而降低大模型训练的成本。当前,基于液冷等技术的算力产品,将软件层面(模型和框架)与硬件基础设施(计算、存储、网络)进行协同优化的方案,都是业界较为推崇的方式。一方面能在高算力集群上能实现更好的算力利用率,另一方面也能降低电力消耗,降低整体成本。
可以说,AI大模型的投入是AI技术迈向新台阶的必经之路,是解决产业碎片化的一种方式。AI大模型的发展与商业落地,有望重塑AI算力与AI应用的市场格局。随着大模型的数量走向集约,有利于AI芯片进行更有针对性的设计开发与优化,这是AI算力企业生态重建的新机会,也是国产AI芯片在国际巨头林立的市场中突围的机会。
写在最后
不破不立,破而后立。大破大立,晓喻新生。
写在AI芯片踏实走过的2022年。
来源: 与非网,作者: 张慧娟,原文链接: https://www.eefocus.com/article/1388291.html

 下载ECAD模型
下载ECAD模型


